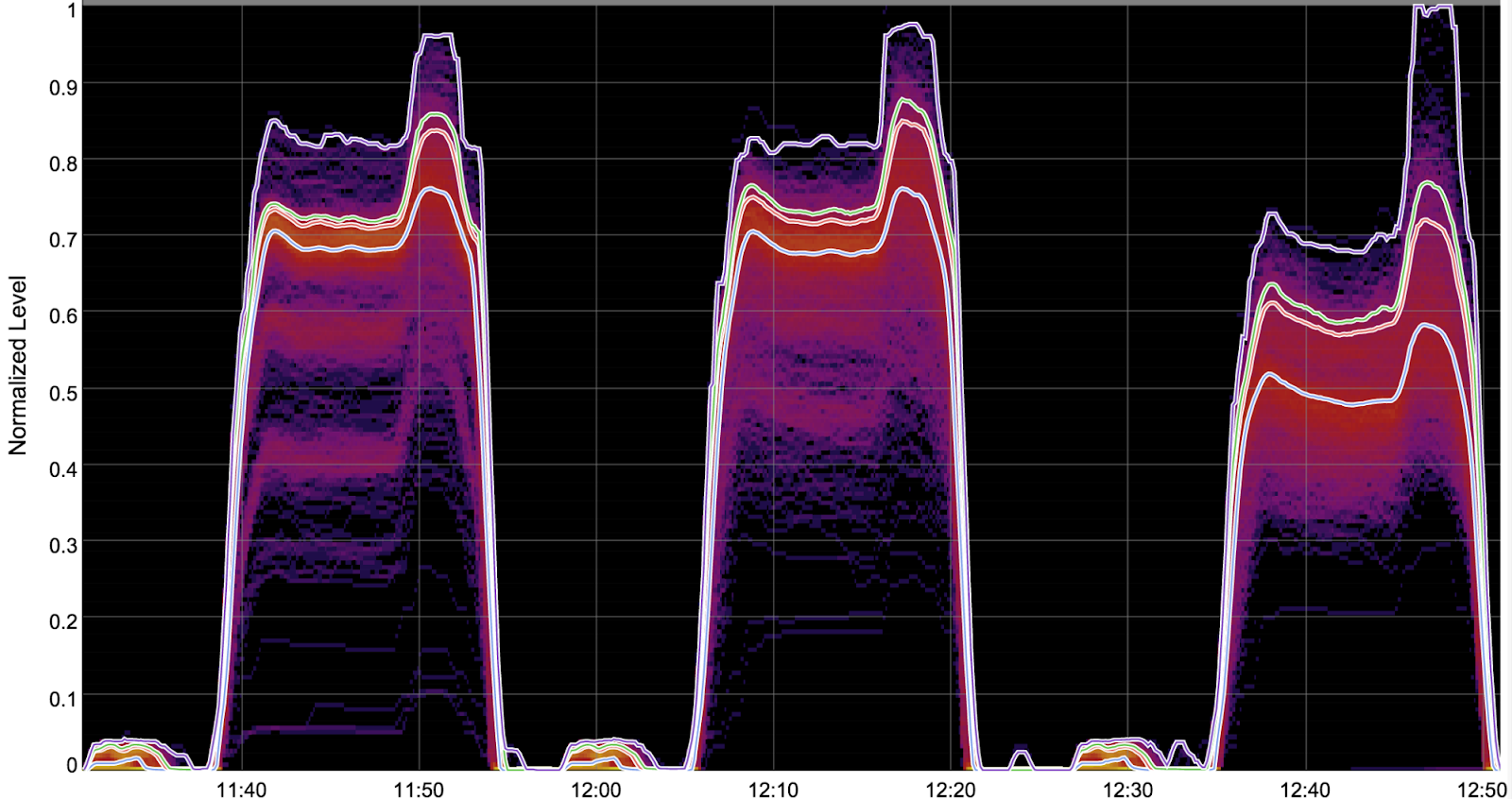
| À esquerda: o modelo do Transformer é aplicado a uma frase de entrada (no canto inferior esquerdo), junto com a frase de saída do idioma de destino (no canto superior direito) e a frase de entrada no idioma de destino (na parte central, à direita, começando com o marcador “<sos>”). Assim é feito o cálculo da perda na tradução. A função “AdvGen” usa a frase de origem, a distribuição de seleção de palavras, as palavras candidatas e a perda na tradução como entradas para construir um exemplo de origem controverso. À direita: no estágio de defesa, o exemplo de origem controverso é usado como entrada para o modelo do Transformer, e a perda na tradução é calculada. O AdvGen usa o mesmo método acima para gerar um exemplo de destino controverso a partir da entrada do destino. |









































4 comentários :
If you are stuck with your online management assignment then in this case you can opt for our Marketing Assignment help. we provide the best assignment online assignment help.
We also provide Business Marketing Assignment help. for students across the globe.
for more information contact us +16692714848
If you are stuck with your online management assignment then in this case you can opt for our Marketing Assignment help. we provide the best assignment online assignment help.
We also provide Business Marketing Assignment help. for students across the globe.
for more information contact us +16692714848
Keep sharing new things.
Physician Burnout Treatment
Nursing Leadership Training
KFC Secret Menu KFC Secret Menu, a culinary adventure reserved for those in the know. Delve beyond the ordinary and explore a realm where tantalizing flavors and hidden treasures await. From tantalizing twists on classic favorites to exclusive creations known only to a select few, the Secret Menu is a playground for true food aficionados.
This post saved me so much time. Ehsaas Program 8171 vs BISP Appreciate it!
Postar um comentário