No Firebase, nossa missão é ajudar as equipes de aplicativos para dispositivos móveis a terem sucesso. Isso significa ter os recursos para apoiar empresas e equipes de todos os tamanhos e níveis de complexidade. Amadurecemos muito nos últimos anos, passando de um banco de dados em tempo real para uma plataforma completa de desenvolvimento de aplicativos para dispositivos móveis. O Firebase foi desenvolvido usando o Google Cloud como base. Portanto, ele oferece toda a escala técnica, a gestão e o controle de acesso de nível empresarial e a força do aprendizado de máquina que são marca registrada de muitos produtos do Google. Hoje, temos o prazer de falar sobre alguns novos produtos e recursos que ajudarão a criar aplicativos melhores, aumentar a qualidade dos já existentes e expandir a sua empresa.
O Firebase tem vários produtos para ajudar você a envolver os usuários e expandir a empresa, da segmentação por aprendizado de máquina com o Firebase Previsões até a otimização de aplicativos sem republicação com o Remote Config e o novo envolvimento de usuários ausentes com o Cloud Messaging. Hoje, estamos adicionando um novo produto, o Firebase In-App Messaging, para completar o conjunto de ferramentas disponível para expandir a base de usuários. Além disso, estamos aprimorando alguns produtos já existentes.
As notificações são uma forma excelente de trazer usuários de volta a um aplicativo. Mas, como garantir que os usuários estão interagindo com o aplicativo da forma certa e esperada e não pulando de tela em tela sem executar nenhuma ação importante? Como guiá-los pela experiência do aplicativo?
Estamos lançando hoje o Firebase In-App Messaging para ajudar você a orientar os usuários ativos do aplicativo por meio de mensagens segmentadas e contextuais. Agora, você poderá se comunicar com os usuários mais importantes (os que já interagem com o aplicativo) e aprofundar o envolvimento com eles oferecendo informações, ofertas e dicas relevantes enquanto usam o aplicativo.
As mensagens podem ter formato, cor e CTA personalizados, o que permite que você aplique às mensagens a identidade visual da sua marca. O In-App Messaging também é integrado ao Google Analytics para Firebase e ao Firebase Previsões, o que facilita a segmentação de mensagens com base nos dados de perfil dos usuários, como versão do aplicativo; no comportamento atual, como o clique de um botão; ou no comportamento futuro previsto, como o risco de abandono. O lançamento do In-App Messaging começa hoje. Leia a nossa documentação para ver mais detalhes.
O console e as APIs do Firebase Cloud Messaging (FCM) permitem enviar notificações e mensagens de dados a usuários que usam iOS, Android e web. No entanto, é difícil compreender o desempenho dessas notificações em todas essas plataformas diferentes. O novo painel de relatórios do FCM oferece às equipes um lugar central para ver as principais estatísticas das mensagens, como envios, impressões e aberturas. Com essas informações, elas conseguem entender rapidamente o desempenho das mensagens. Além de agregar todas essas estatísticas, o painel de relatórios também fornece, pela primeira vez, informações sobre as mensagens enviadas do console por meio da API.
Os desenvolvedores podem usar essas informações para monitorar o estado da funcionalidade da notificação, como uma queda nos envios após o lançamento de uma nova atualização, além de usar as informações sobre envios e aberturas de notificações para melhorar a estratégia, como acompanhar o efeito de um título de uma notificação sobre as taxas de abertura. O painel de relatórios do FCM permite filtrar envios por data, plataforma (iOS e Android) e tipo (mensagem de dados ou notificação), facilitando a localização dos dados.
Antes, se você quisesse checar que valores do Remote Config usou no passado, precisaria manter um controle manual. Em equipes de uma pessoa só, isso era um problema contornável. Mas, para equipes grandes, em que vários desenvolvedores diferentes podem alterar o Remote Config do projeto ao mesmo tempo, o controle manual era praticamente impossível.
Hoje, temos o orgulho de anunciar a adição do recurso de histórico de alterações ao Remote Config. O Firebase salva 300 versões do Remote Config de um projeto por até 90 dias. Você poderá ver como os parâmetros e as condições evoluem com o tempo e, se quiser voltar a uma versão anterior, basta clicar no botão de rollback.
Hoje, estamos iniciando o lançamento do histórico de alterações para o Remote Config. Em alguns dias, o novo recurso estará totalmente disponível para todos os projetos. Clique aqui para ver a documentação técnica.
Histórico de alterações no Remote Config
Quando a equipe da Fabric chegou ao Firebase no ano passado, ficamos entusiasmados por aprender com a especialização da equipe no desenvolvimento de ferramentas para depuração e relatórios de erros. Nos últimos 18 meses, demos passos muito importantes para tornar o Firebase uma plataforma que você pode usar para aumentar a qualidade dos aplicativos, incluindo a incorporação do Crashlytics, originalmente da Fabric, ao Firebase. Hoje, temos o prazer de anunciar diversos aprimoramentos no Crashlytics, que ajudarão em sua integração às ferramentas usadas atualmente pelas equipes de desenvolvimento.
Vocês nos disseram que usam muitas ferramentas diferentes para tornar sua empresa um sucesso. Queremos nos juntar a você na forma como trabalha e ajudar a usar a melhor ferramenta para o seu trabalho. Por isso, estamos lançando algumas novas integrações para o Firebase Crashlytics.
Em primeiro lugar, agora você pode exportar os dados do Crashlytics do Firebase para o BigQuery, o que permite executar suas próprias análises de relatórios de erros não ofuscados, incluindo metadados como chaves e valores personalizados, registros e IDs de usuário. Em seguida, você pode visualizar dados e identificar tendências com o Data Studio ou qualquer outra ferramenta de análise empresarial disponível. Além disso, você também pode assumir o controle dos seus dados no BigQuery, definindo suas próprias políticas de retenção e exclusão.
Em segundo lugar, estamos lançando uma integração com o Jira Software que permite abrir problemas no Jira com base em falhas relatadas no Firebase. Esse novo recurso, combinado com a integração com o Slack, permite que a sua equipe controle as falhas em que estão trabalhando com as ferramentas que já usam. A integração com o Jira será lançada gradualmente ao longo das próximas semanas. Se você quiser gerenciar as suas integrações do Firebase agora, é só acessar a guia de configurações do console.
O núcleo do DNA do Firebase é um conjunto de produtos que ajudam desenvolvedores como você a criar uma infraestrutura de back-end para dispositivos móveis com rapidez e facilidade. Afinal de contas, tudo começou com um Realtime Database. Estamos trabalhando em conjunto com o Google Cloud Platform para criar a próxima geração de ferramentas de back-end sem servidor, como o Cloud Firestore e o Cloud Functions, e continuamos aprimorando esses produtos. Além disso, estamos lançando algumas melhorias para o Firebase Hosting que esperamos que ajudem você a criar sites com mais eficiência.
Há algumas semanas, no Cloud Next 2018, apresentamos diversas melhorias para o Cloud Firestore e o Cloud Functions para Firebase. Agora, o Cloud Firestore permite escalonar um banco de dados para até 10.000 gravações por segundo e 1 milhão de usuários simultâneos para gerenciar possíveis picos no tráfego. O Cloud Functions agora é GA e está pronto para uso em produção, com serviço previsível garantido por um SLA. Se você pretende criar sua infraestrutura em algumas partes do mundo, o Cloud Firestore e o Cloud Functions adicionarão suporte a novas regiões da Europa e da Ásia nos próximos meses.
Outra informação que recebemos constantemente de vocês é que nem sempre há uma relação de um para um entre projetos do Firebase e sites hospedados. Ao longo das próximas semanas, lançaremos uma atualização para o Firebase Hosting que permitirá hospedar diversos sites em um único projeto.
Além disso, ao enviar uma atualização para um site, o Firebase CLI (a partir da versão v4.1.0) só atualiza os arquivos que foram alterados entre as versões. Essa mudança acelera drasticamente o processo e aumenta a eficiência do seu trabalho.
A página Project Overview do console recebeu uma grande atualização que agregou dados de diversas partes do Firebase para oferecer uma única visualização da integridade dos aplicativos, dos serviços e da empresa. Além dos dados de análises e falhas que sempre estiveram disponíveis, agora você poderá ver problemas de desempenho, notificações e status de testes A/B, além dos dados de uso e integridade de outros serviços do Firebase como o Functions, o Hosting e o Storage, entre outros.
Você também notará que a seção "Latest Release" do console mostrará dados ao vivo. Essa foi uma das melhorias mais solicitadas para as análises no console, e estamos felizes por disponibilizá-la a vocês.
Todas essas atualizações estão começando a ser lançadas hoje e estarão disponíveis para todos em algumas semanas.
Como sempre, obrigado por fazer parte da comunidade do Firebase. Trabalhamos muito para criar uma comunidade receptiva para desenvolvedores com os mais diversos históricos e empresas com todos os níveis de sofisticação. Suas opiniões e dúvidas são extremamente valiosas para moldar o futuro do Firebase. Portanto, como sempre, fale conosco pelos canais de suporte sempre que quiser.
Se quiser conhecer a equipe pessoalmente, venha ao Firebase Summit anual, que será realizado em 29 de outubro, em Praga, na República Tcheca. Lá, você terá um dia cheio de sessões técnicas, codelabs práticos com instrutor e outra rodada de novas atualizações. Espero ver você lá!
Vemos com frequência o aprendizado por transferência aplicado a modelos de visão computacional, mas será que funcionaria também para classificação de texto? Apresentamos o TensorFlow Hub, uma biblioteca para aprimorar modelos de TF com aprendizado por transferência. O aprendizado por transferência é o processo de obter os pesos e variáveis de um modelo existente já treinado com muitos dados e usá-lo na sua própria tarefa de dados e previsão.
Um dos muitos benefícios do aprendizado por transferência é que você não precisa fornecer tantos dados de treinamento, como se começasse do zero. Mas, de onde vêm esses modelos pré-existentes? É aí que o TensorFlow Hub ajuda, oferecendo um repositório completo de pontos de controle já existentes para vários tipos de modelo: imagens, texto e outros. Nesta postagem, mostrarei como criar um modelo para prever o gênero de um filme com base na sua descrição usando o módulo de texto do TensorFlow Hub.
Você pode executar esse modelo no navegador usando o Colab, sem necessidade de configurar nada.
Para esse modelo, usaremos este conjunto de dados de filmes incrível da Kaggle, que é de domínio público e contém dados de mais de 45.000 filmes. O conjunto tem diversos dados sobre cada filme, mas, para simplificar as coisas, vamos usar somente as descrições (chamadas de "overview", ou visão geral) e os gêneros. Esta é uma visualização do conjunto de dados do Kaggle:
Primeiro, importamos as bibliotecas que usaremos para criar o modelo:
Disponibilizei um arquivo CSV desse conjunto de dados em um bucket público do Cloud Storage. Executaremos o comando abaixo para fazer download dos dados da nossa instância do Colab e lê-los como um dataframe do Pandas:
Para manter a simplicidade, vamos limitar os gêneros possíveis:
Limitaremos o conjunto de dados a filmes desses gêneros que tenham descrição. Depois, poderemos dividir os dados em conjuntos de treinamento e de teste aplicando uma divisão de 80% para treinamento e 20% para teste:
É surpreendente como uma incorporação com o TF Hub usa tão pouco código. Nosso modelo só terá um recurso (a descrição) e será representado por uma coluna incorporada. As incorporações de texto criam uma forma de representar partes do texto em espaço de vetor. Portanto, palavras ou frases parecidas ficam mais próximas no espaço de incorporação (leia mais sobre esse assunto aqui). Você pode criar vetores de incorporação de texto do zero usando apenas seus próprios dados. O TF Hub simplifica esse processo disponibilizando incorporações de texto já treinadas com diversos dados de texto.
Para texto em inglês, o TF Hub oferece diversas incorporações treinadas com vários tipos de dado de texto:
As incorporações de texto pré-treinadas que você escolher são um hiperparâmetro no seu modelo. Por isso, é melhor experimentar com outras e ver qual delas tem a maior precisão. Comece com o modelo que foi treinado com textos mais parecidos ao seu. Como nossas descrições de filme são entradas mais longas, notei que consegui a maior precisão com as incorporações do codificador universal de sentenças. Ele codifica as descrições em vetores de texto altamente dimensionais. Note que esse modelo em particular é bem grande e vai ocupar 1 GB.
Podemos usar hub.text_embedding_column para criar uma coluna de recursos para essa camada em uma linha de código, passando a ela o nome da camada ("movie_descriptions") e o URL do modelo do TF Hub que usaremos:
Veja que pode levar algum tempo para a execução dessa célula, já que está fazendo o download das incorporações pré-treinadas.
O melhor é que não precisamos de pré-processamento para inserir as descrições em texto nas incorporações de palavras pré-treinadas. Se fôssemos criar esse modelo do zero, teríamos que converter as descrições em vetores. No entanto, com a coluna TF Hub, podemos passar as strings de descrição diretamente para o modelo.
Como um filme muitas vezes tem diversos gêneros, nosso modelo retornará os vários rótulos possíveis para cada filme. No momento, nossos gêneros são uma lista de strings de cada filme (como ["Action", "Adventure"], ou ação, aventura). Como todos os rótulos têm que ter o mesmo tamanho, transformaremos essas listas em vetores multi-hot de dígitos 1 e 0, que correspondem aos gêneros presentes em uma determinada descrição. O vetor multi-hot de um filme de ação e aventura (Action e Adventure) ficaria assim:
Para transformar os rótulos de string em vetores multi-hot em poucas linhas de código, usaremos um utilitário da biblioteca scikit-learn chamado MultiLabelBinarizer:
Você pode imprimir encoder.classes_ para ver uma lista de todas as classes de string que o modelo está prevendo.
Para o nosso modelo, usaremos um DNNEstimator para criar uma rede neural profunda que retorna um vetor multi-hot, já que todo filme pode ter 0 ou mais rótulos possíveis (isso é diferente de um modelo em que cada entrada tem exatamente um rótulo). O primeiro parâmetro que passamos ao DNNEstimator é chamado de "head" (cabeça) e define o tipo de rótulos que nosso modelo deve esperar. Como queremos que o nosso modelo gere diversos rótulos, usaremos "multi_label_head":
Agora, podemos passar isso quando instanciarmos o DNNEstimator. O parâmetro "hidden_units" indica quantas camadas teremos na nossa rede. Esse modelo usa 2 camadas: a primeira tem 64 neurônios e a segunda tem 10. O número e o tamanho das camadas é um hiperparâmetro. Portanto, o ideal é experimentar valores diferentes para ver qual funciona melhor com o conjunto de dados. Por fim, passamos nossas colunas de recurso ao Estimator. Nesse caso, só temos uma (a descrição), e já a definimos como uma coluna de incorporação do TF Hub acima para podermos passá-la aqui como uma lista:
Já está quase tudo pronto para treinar o modelo. Antes de podermos treinar nossa instância do estimador, precisamos definir a função "input" (entrada) do treinamento. Essa função conecta nossos dados ao modelo. Aqui, vamos usar um "numpy_input_fn" e inserir os dados no nosso modelo como matrizes "numpy":
Os parâmetros "batch_size" e "num_epochs" da nossa função "input" são hiperparâmetros. "batch_size" diz ao modelo quantos exemplos serão passados ao modelo em uma iteração e "num_epochs" é o número de vezes que nosso modelo analisará todo o conjunto de treinamento.
Chegou a hora de treinar o modelo. Fazemos isso com uma linha de código:
Para avaliar a precisão do nosso modelo, criamos um eval "input_function" com os dados do teste e chamamos "estimator.evaluate()":
Esse modelo atingiu 91,5% de área abaixo da curva (AUC) e 74% de precisão/recall. Os seus resultados podem variar um pouco.
Chegamos na melhor parte: gerar previsões com dados que o nosso modelo nunca viu. Primeiro, vamos criar uma matriz com algumas descrições (peguei as descrições abaixo no IMDB):
Em seguida, vamos definir nossa função "input" de previsão e chamar "predict()":
Por fim, podemos iterar os resultados e exibir os 2 principais gêneros encontrados para cada filme junto com os valores de confiança:
Nosso modelo consegue marcar todas as descrições de filme acima corretamente.
Quer começar a desenvolver o seu próprio modelo com o TF Hub? Confira a documentação e os tutoriais. Veja o código completo do modelo que usamos aqui no GitHub ou no Colab. Em uma postagem futura, mostrarei como exportar esse modelo para operar no TensorFlow Serving ou no Cloud ML Engine, e como criar um aplicativo que gera previsões sobre novas descrições.
Se tiver alguma dúvida ou quiser fazer uma observação, fale comigo no Twitter: @SRobTweets.
array-contains
sly
arrayRemove
arrayUnion
viewers
De Yash Katariya, estagiária de engenharia de programas para desenvolvedores
Sempre achei os modelos geradores e sequenciais fascinantes: eles fazem um tipo de pergunta diferente dos que normalmente encontramos quando começamos a estudar aprendizado de máquina (AM). Quando comecei a estudar AM, aprendi (como muitos de nós) classificação e regressão. Esses conhecimentos me ajudaram a responder perguntas como:
Classificação e regressão são conhecimentos que vale muito a pena dominar. As possibilidades de aplicação desses conhecimentos em problemas úteis e reais são praticamente ilimitadas. Mas há outros tipos de pergunta que podemos fazer e que têm um aspecto bem diferente:
No meu estágio de verão, desenvolvi exemplos dessas áreas usando duas das APIs mais recentes do TensorFlow: tf.keras e execução antecipada. As duas estão compartilhadas a seguir. Espero que sejam úteis e que você se divirta bastante!
Se você ainda não é muito experiente com essas APIs, pode aprender mais explorando a sequência de blocos de anotações em tensorflow.org/tutorials, que contém exemplos atualizados recentemente.
Todos os exemplos abaixo são completos e seguem um padrão similar:
Nosso primeiro exemplo é de geração de texto, em que usamos uma RNN para gerar texto em um estilo parecido com o de Shakespeare. Você pode executá-lo no Colaboratory com o link acima (ou baixá-lo do GitHub como um bloco de anotações do Jupyter). O código é explicado em detalhes no bloco de anotações.
Considerando a enorme coleção de obras de Shakespeare, esse exemplo aprende a gerar textos com estilo parecido:
Embora a maioria das sentenças não faça sentido (obviamente, esse modelo simples não aprendeu o significado da linguagem), o que impressiona é que a maioria das palavras *é* válida e a estrutura das peças produzidas é semelhante à do texto original (esse é um modelo baseado em personagens, no breve período em que o treinamos; ele aprendeu as duas coisas totalmente do zero). Se quiser, você pode alterar o conjunto de dados mudando uma única linha do código.
O melhor lugar para entender melhor as RNNs é no excelente artigo de Andrej Karpathy, The Unreasonable Effectiveness of Recurrent Neural Networks. Se quiser saber mais sobre como implementar RNNs com o Keras ou o tf.keras, recomendamos esses blocos de anotações de Francois Chollet.
Neste exemplo, geramos dígitos escritos a mão usando DCGAN. Uma rede geradora adversária (GAN) consiste em um gerador e um discriminador. O trabalho do gerador é criar imagens convincentes para enganar o discriminador. O trabalho do discriminador é classificar as imagens como reais ou falsas (criadas pelo gerador). O resultado abaixo foi gerado após o treinamento do gerador e do discriminador por 150 eras usando a arquitetura e os hiperparâmetros descritos neste artigo.
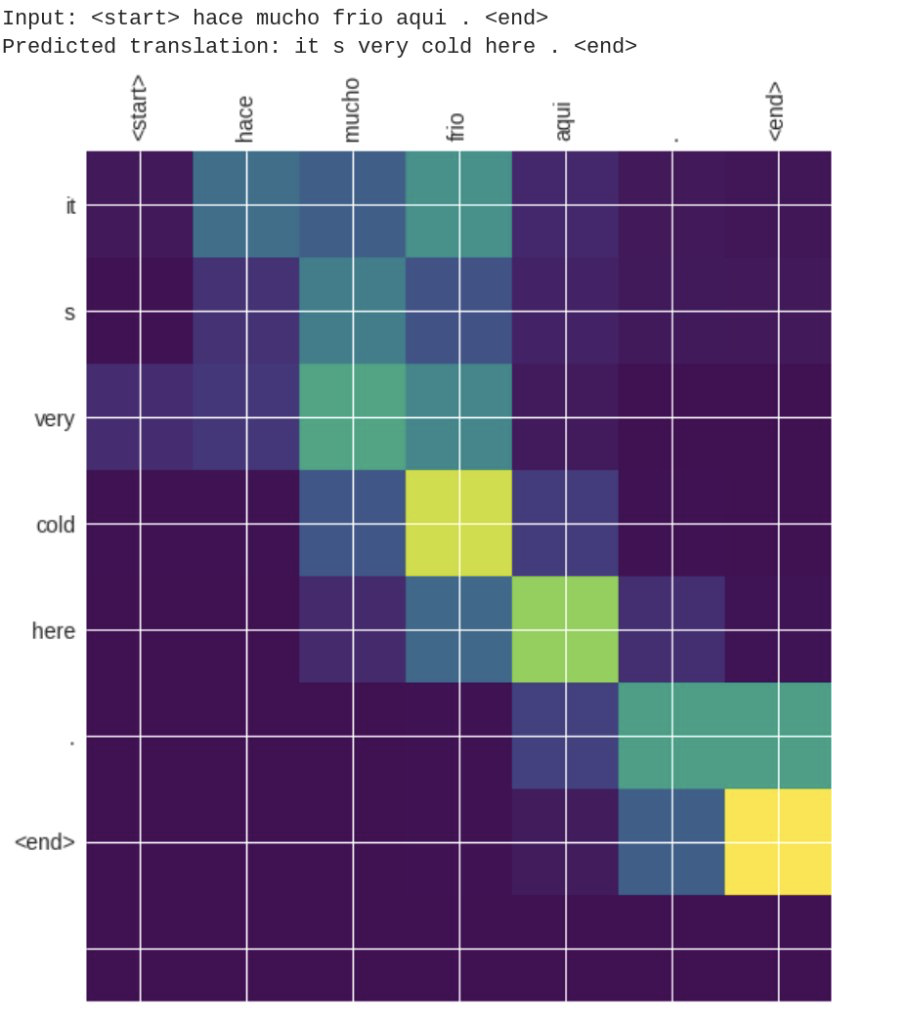
Este exemplo treina um modelo para traduzir frases em espanhol para o inglês. Depois de treinar o modelo, você poderá inserir uma frase em espanhol, como "¿todavia estan en casa?", e retornar a tradução para o inglês: "are you still at home?"
A imagem abaixo é o diagrama de atenção. O diagrama mostra que partes da frase de entrada têm a atenção do modelo durante a tradução. Por exemplo, quando o modelo traduziu a palavra "cold", estava analisando "mucho", "frio", "aqui". Implementamos o Bahdanau Attention do zero usando o tf.keras e a execução antecipada, que explicamos detalhadamente no bloco de anotações. Você pode usar essa implementação como base para implementar seu próprios modelos personalizados.
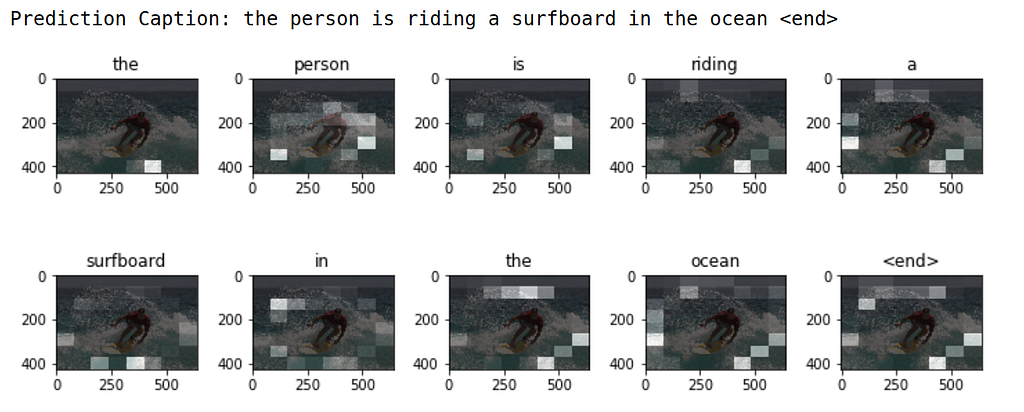
Neste exemplo, treinamos o nosso modelo para prever a legenda de uma imagem. Geramos também um diagrama de atenção, que mostra partes da imagem em que o modelo se concentra para gerar a legenda. Por exemplo, o modelo se concentrou na área perto da prancha de surfe da imagem quando previu a palavra "surfboard". Esse modelo foi treinado usando um subconjunto do conjunto de dados MS-COCO, que será baixado automaticamente pelo bloco de anotações.
Próximos passos
Para saber mais sobre o tf.keras e a execução antecipada, fique atento ao conteúdo de tensorflow.org/tutorials (frequentemente atualizado) e confira periodicamente este blog e o feed do TensorFlow no Twitter. Obrigado por ler!
Agradecimentos
Agradecemos imensamente a Josh Gordon, Mark Daoust, Alexandre Passos, Asim Shankar, Billy Lamberta, Daniel "Wolff" Dobson e Francois Chollet por suas contribuições e sua ajuda.
Postado por James Lau, gerente de produtos (@jmslau)
Quando se usa Java como linguagem de programação, um dos erros mais comuns é tentar acessar um membro de uma referência nula, gerando uma NullPointerException. O Kotlin oferece proteção contra esse tipo de problema incorporando tipos que permitem e que não permitem valor nulo ao sistema de tipos. Isso ajuda a eliminar NullPointerExceptions do código e melhorar a qualidade do aplicativo no geral. Quando código Kotlin chama APIs escritas em Java, precisa das anotações de nulabilidade dessas APIs para determinar a nulabilidade de cada parâmetro e o tipo de retorno. Parâmetros e tipos de retorno sem anotação são tratados como tipos de plataforma, o que enfraquece a garantia de segurança contra valores nulos do Kotlin.
NullPointerException
Como parte do anúncio do Android 9 de ontem, lançamos também um novo Android SDK que contém anotações de nulabilidade para as APIs mais usadas. Dessa forma, é possível preservar a garantia de segurança contra valores nulos quando o código Kotlin chama APIs anotadas do SDK. Mesmo que você esteja usando o Java como linguagem de programação, ainda pode se beneficiar dessas anotações usando o Android Studio para encontrar violações de contratos de nulabilidade.
Normalmente, violações de contratos de nulabilidade no Kotlin geram erros de compilação. Mas, para ter certeza de que as APIs recém-anotadas são compatíveis com o seu código atual, estamos usando um mecanismo interno oferecido pela equipe do compilador do Kotlin para marcar as APIs como recém-anotadas. APIs recém-anotadas só gerarão avisos (em vez de erros) no compilador do Kotlin. Você precisa do Kotlin versão 1.2.60 ou mais recente.
A ideia é fazer com que as anotações de nulabilidade recém-adicionadas gerem apenas avisos e aumentar o nível de gravidade dos erros a partir do Android SDK do ano que vem. O objetivo é proporcionar tempo suficiente para que você atualize o seu código.
Para começar, acesse Tools > SDK Manager no Android Studio. Selecione Android SDK no menu à esquerda e verifique se a guia "SDK Platforms" está aberta.
Use o SDK Manager no Android Studio para instalar o SDK para a API de nível 28 revisão 6
Marque "Android 8.+ (P)" e clique em "OK". Será instalada a plataforma Android SDK 28 revisão 6, a menos que já esteja instalada. Em seguida, defina a versão do SDK de compilação do seu projeto como "API 28" para começar a usar o novo Android Pie SDK com anotações de nulabilidade.
Use a caixa de diálogo "Project Structure" para alterar a versão do SDK de compilação do seu projeto para API 28
Talvez seja preciso atualizar seu plug-in do Kotlin no Android Studio, caso esteja desatualizado. Verifique a versão do plug-in do Kotlin em Tools > Kotlin > Configure Kotlin Plugin Updates. Ela deve ser a 1.2.60 ou posterior.
Após a configuração, as compilações começarão a apresentar avisos caso seu código viole os contratos de nulabilidade do Android SDK. Veja um exemplo de aviso abaixo.
Exemplo de aviso do compilador do Kotlin quando o código viola um contrato de nulabilidade recente do Android SDK.
Além disso, você começará a ver avisos no editor de código do Android Studio se chamar uma Android API com a nulabilidade incorreta. Veja um exemplo abaixo.
Aviso do Android Studio sobre a passagem de uma referência nula a um parâmetro anotado como um tipo não nulo recente na android.graphics.Path API.
Mesmo que seu código esteja em Java, as novas anotações de nulabilidade podem ser úteis. Por padrão, o Android Studio destaca todas as violações de contrato de nulabilidade com um aviso, como este:
Android Studio exibindo um aviso sobre uma violação de contrato de nulabilidade em código escrito em Java
Para garantir a ativação dessa inspeção, acesse a página de configurações do IDE, busque a inspeção "Constant conditions & exceptions" e verifique se esse item está marcado.
Use a página "Inspections" em "Settings" para verificar se a inspeção de código "Constant conditions & exceptions" está ativa.
Se você usa o Java como linguagem de programação, as violações de contrato de nulabilidade não produzirão aviso ou erro do compilador. Apenas as inspeções de código no IDE podem sinalizar esses problemas.
Você ainda pode realizar inspeções de código em todo o seu projeto e ver os resultados combinados. Clique em Analyze > Inspect Code… para começar.
A superfície da Android SDK API é muito grande e anotamos apenas uma pequena parte das APIs até agora. Ainda resta muito trabalho a ser feito. Nas próximas versões do Android SDK, continuaremos adicionando anotações de nulabilidade às Android APIs que já existem e anotaremos sempre as novas APIs.
Com o Android SDK "ideal para Kotlin", as anotações de nulabilidade do AndroidX (parte da família Jetpack) e do Android KTX, continuamos aprimorando as Android APIs para desenvolvedores que usam o Kotlin. Se você ainda não testou o Kotlin, experimente, porque vale a pena. O Kotlin não só deixa seu código mais conciso, mas também aumenta a estabilidade dos aplicativos.
Divirta-se com o Kotlin!
Por Pete Warden, engenheiro de software
Quando o TensorFlow foi lançado, em 2015, queríamos que ele fosse uma "biblioteca de aprendizado de máquina de código aberto para todos". Para fazer isso, precisamos que ele seja compatível com o maior número possível de plataformas usadas atualmente. Já temos suporte ao Linux, macOS, Windows, iOS e Android há muito tempo. No entanto, apesar do grande esforço de muitos colaboradores, a execução do TensorFlow em um Raspberry Pi foi realmente um grande desafio. Graças à colaboração com a Raspberry Pi Foundation, temos o prazer de informar que a versão mais recente, o TensorFlow 1.9, pode ser instalada com binários pré-compilados usando o sistema de pacotes pip do Python. Se você usa o Raspbian 9 (stretch), pode instalar o TensorFlow executando os dois comandos abaixo em um terminal:
sudo apt install libatlas-base-dev
pip3 install tensorflow
Depois, é só executar python3 em um terminal e usar o TensorFlow normalmente, como em qualquer outra plataforma. Este é um exemplo simples, do tipo "Hello World":
# Python
import tensorflow as tf
tf.enable_eager_execution()
hello = tf.constant(‘Hello, TensorFlow!’)
print(hello)
Se o sistema gerar o resultado abaixo, você poderá começar a desenvolver programas com o TensorFlow:
Hello, TensorFlow!
Vale a pena conferir o site do TensorFlow para obter mais detalhes sobre como instalar e resolver problemas do TensorFlow no Raspberry Pi.
Estamos muito empolgados com isso porque o Raspberry Pi é usado por muitos desenvolvedores inovadores, além de ser amplamente utilizado no ensino de programação. Portanto, facilitar a instalação do TensorFlow ajudará a levar o aprendizado de máquina a novos públicos. Já vimos que plataformas como o DonkeyCar usam o TensorFlow e o Raspberry Pi para criar carrinhos de brinquedo autônomos. Isso nos deixa muito curiosos para ver os projetos que serão criados, agora que reduzimos a dificuldade.
Eben Upton, fundador do projeto Raspberry Pi, diz que "é vital que um ensino de computação moderno englobe conceitos básicos e também assuntos inovadores. Com isso em mente, estamos muito animados por trabalhar com o Google para levar o aprendizado de máquina do TensorFlow à plataforma Raspberry Pi. Estamos ansiosos para ver que aplicativos divertidos as crianças (de todas as idades) criarão". Nós também!
Esperamos que muitos materiais educativos e tutoriais sejam criados para ajudar cada vez mais pessoas a explorar as possibilidades do aprendizado de máquina em um dispositivo tão flexível e acessível.
div { background: conic-gradient(red, yellow, lime, aqua, blue, magenta, red); border-radius: 50% }
margin
padding
border
margin-{block,inline}-{start,end}
padding-{block,inline}-{start,end}
border-{block,inline}-{start,end}-{width,style,color}
-webkit
border-{block,inline}-{start,end}
#gallery { scroll-snap-type: x mandatory; overflow-x: scroll; display: flex; } #gallery img { scroll-snap-align: center; }
env()
viewport-fit
viewport
cover
<meta name="viewport" content="viewport-fit: cover" /> <style> #box { margin-top: env(safe-area-inset-top); margin-left: env(safe-area-inset-left); margin-bottom: env(safe-area-inset-bottom); margin-right: env(safe-area-inset-right); } </style> <div id=box></div>
DedicatedWorker.requestAnimationFrame()
const offscreenCanvas = new OffscreenCanvas(100, 100); const ctx = offscreenCanvas.getContext("2d"); ctx.fillRect(0, 0, 10, 10);
const canvasElement = document.getElementById("mycanvas") const offscreenCanvas = canvasElement.transferControlToOffscreen(); const ctx = offscreenCanvas.getContext("2d"); ctx.fillRect(0, 0, 10, 10);
self.onmessage = function(ev) { const offscreenCanvas = ev.data; const ctx = offscreenCanvas.getContext("2d"); let x = 0; const draw = function() { ctx.clearRect(0, 0, ctx.canvas.width, ctx.canvas.height); ctx.fillRect(x, 0, 10, 10); x = (x + 1) % ctx.canvas.width; requestAnimationFrame(draw); }; draw(0); }
const worker = new Worker("worker.js"); const offscreenCanvas = document.getElementById("canvas").transferControlToOffscreen(); worker.postMessage(offscreenCanvas, [offscreenCanvas]);
Element.toggleAttribute()
Element.classList.toggle
Element.setAttribute()
Array.prototype.flat()
Array.prototype.flatMap()
flat()
KeyboardEvent.code
rtt
downlink
ect
navigator.connection.rtt
navigator.connection.downlink
navigator.connection.effectiveType
ServiceWorkerRegistration.update()
navigator.serviceWorker
SecurityError
my_net_sync
my_resource
await navigator.locks.request('my_resource', async lock => { const url = await look_up_in_database(); const response = await fetch(url); const body = await response.text(); await store_body_in_database(body); });
RTCRtpParameters.headerExtensions
RTCRtpSender.getParameters()
PeerConnection
RTCRtpSender
RTCRtpReceiver
getCapabilities()
HTMLMediaElement.stalled
stalled
document.createTouchList()
Touch()
window.confirm()
false
Nota do editor: o artigo abaixo foi originalmente postado no blog do AddThis por Chad Edmonds, gerente de marketing sênior da AddThis
O AddThis passou a ser gratuito, mas isso não significa que estamos desacelerando o lançamento de mais recursos e funcionalidades incríveis. Recentemente, lançamos os AddThis Inline Share Buttons for AMP e eles já estão prontos para integração a sites compatíveis com o AMP.
Vamos rever o histórico? O projeto AMP (encabeçado pelo Google e outras empresas) é uma iniciativa de código aberto, cuja sigla significa Accelerated Mobile Pages (páginas móveis aceleradas). O objetivo do projeto é aprimorar a experiência de navegação web em dispositivos móveis, acelerando a carga das páginas web e garantindo que sejam exibidas de forma harmoniosa. A configuração de páginas para usar o AMP oferece outras vantagens, como maior tráfego de plataformas que exibem links para sites AMP (por exemplo, o Google e o Twitter). Saiba mais sobre como criar uma página AMP aqui.
Estamos felizes por participar da iniciativa para aprimorar o ecossistema de conteúdo, e acreditamos que os usuários terão com o AMP a mesma funcionalidade de outras plataformas. É por isso que somos um dos primeiros plug-ins de terceiros a ser disponibilizado como um componente do AMP.
Tudo pronto para começar? Leia nosso artigo na Academy ou assista ao nosso vídeo no YouTube para saber como instalar os AddThis Inline Share Buttons em um site AMP.
Nos próximos meses, lançaremos mais recursos para o AMP, além de uma documentação de suporte mais completa. Enquanto isso, se tiver alguma dúvida ou quiser fazer algum comentário sobre o plug-in, entre em contato com a nossa equipe de suporte.
Postado por Chad Edmonds, gerente de marketing sênior da AddThis
Postado por Mary Chen, gerente de marketing de produtos, e Ralfi Nahmias, gerente de produto do Dialogflow
Hoje, na Google Cloud Next ‘18, o Dialogflow está lançando diversos novos recursos beta para ampliar a capacidade de conversação do suporte ao cliente e das centrais de contato. Vamos ver como usar três desses recursos com o Google Assistente para melhorar a experiência de atendimento ao cliente das Actions.
Não é fácil criar Actions, ou ações, de conversação para casos em que há muito conteúdo, como para respostas a perguntas frequentes ou de base de conhecimento. Normalmente, esse tipo de conteúdo é denso e desestruturado, o que torna a modelagem precisa de intent demorada e propensa a erros. O recurso Knowledge Connectors do Dialogflow simplifica o processo de desenvolvimento porque entende e organiza automaticamente perguntas e respostas dentro do conteúdo fornecido. Esse recurso pode adicionar milhares de respostas extraídas diretamente da Action de conversação criada com o Dialogflow, o que permite que você se dedique a coisas mais divertidas, como criar experiências sofisticadas e envolventes para os usuários.
Experimente o Knowledge Connectors neste exemplo de oficina de bicicletas
Quando os usuários interagem com o Google Assistente por meio de texto, é comum e natural cometer erros ortográficos e gramaticais. Quando esses erros de digitação ocorrem, as Actions podem não entender a intenção do usuário, o que compromete a qualidade da experiência de acompanhamento. Com o Automatic Spelling Correction, as Actions criadas usando o Dialogflow podem corrigir automaticamente erros ortográficos, melhorando muito a correspondência entre intent e entidade. O Automatic Spelling Correction usa tecnologia similar à usada no Pesquisa Google e em outros produtos Google.
Use o Automatic Spelling Correction para melhorar a correspondência entre intent e entidade
Agora, a Action pode ser usada como agente de telefone virtual por meio da integração do novo Phone Gateway do Dialogflow. Atribua um telefone ativo a uma Action criada com o Dialogflow para que ela comece imediatamente a receber chamadas. O Phone Gateway permite implementar facilmente agentes virtuais, sem necessidade de incorporar diversos serviços exigidos para criar aplicativos para celular.
Configure o Phone Gateway em 3 passos simples
O Knowledge Connectors, o Automatic Spelling Correction e o Phone Gateway são gratuitos para agentes da Standard Edition (até um determinado limite). Se você é uma empresa, clique aqui para ver mais opções.
Estamos ansiosos para ver as Actions que você criará com esses novos recursos do Dialogflow. Criamos uma Action de pergunta frequente do Cloud Next, ideal para você experimentar os novos recursos:
Mas se você ainda está começando a desenvolver para o Google Assistente, participe da nossa palestra no Cloud Next nesta quinta-feira, às 9h. Até lá, on-line ou pessoalmente!
"Estamos muito animados e ansiosos pela chegada do Engenheiro de nuvem associado ao mercado. Com ele, poderemos escolher diversos perfis de profissional na empresa para promover maior conhecimento e especialização nas tecnologias do Google Cloud em toda a gama de serviços gerenciados que oferecemos." – Luvlynn McAllister, diretor de estratégia de vendas e operações empresariais da Rackspace