Quando se trata de serviços gerenciados do Kubernetes, o Google Kubernetes Engine (GKE) é uma ótima escolha se você procura por uma plataforma de orquestração de contêineres que ofereça escalonabilidade avançada e flexibilidade de configuração. O GKE oferece controle completo sobre todos os aspectos da orquestração de contêineres, desde rede e armazenamento até a forma como a capacidade de observação é configurada. Além disso, ele é compatível em casos de uso de aplicativos com estado. No entanto, caso seu aplicativo não precise desse nível de configuração e monitoramento de cluster, o Cloud Run totalmente gerenciado pode ser a solução certa para você.
O Cloud Run totalmente gerenciado é uma plataforma sem servidor ideal para microsserviços em contêiner sem estado, que não exigem recursos do Kubernetes como namespaces, localização conjunta de contêineres nos pods (arquivos secundários) ou alocação e gerenciamento de nós.
O Cloud Run, uma plataforma gerenciada de computação sem servidor, oferece diversos recursos e benefícios:
Implantação fácil de microsserviços. É possível implantar um microsserviço em contêiner com um único comando, sem a necessidade de outra configuração específica do serviço.
Experiência do desenvolvedor simples e unificada. Cada microsserviço é implementado como uma imagem do Docker, a unidade de implantação do Cloud Run.
Execução sem servidor escalonável. O escalonamento de um microsserviço implantado no Cloud Run gerenciado é feito automaticamente com base na quantidade de solicitações recebidas. Não é necessário configurar nem gerenciar um cluster do Kubernetes completo. Se não houver solicitações, o Cloud Run gerenciado escalonará para zero. Ou seja, nenhum recurso será usado.
Compatibilidade com códigos escritos em qualquer linguagem. O Cloud Run usa contêineres como base. Assim, é possível escrever códigos em qualquer linguagem, usando qualquer binário e biblioteca.
O Cloud Run está disponível em duas configurações: como um serviço totalmente gerenciado do Google Cloud e como o Cloud Run para Anthos (essa opção implanta o Cloud Run no cluster do Anthos GKE). Se você já usa o Anthos, o Cloud Run para Anthos pode implantar contêineres no seu cluster. Assim, é possível acessar tipos de máquinas personalizados, suporte de rede adicional e GPUs para melhorar os serviços do Cloud Run. Os serviços gerenciados do Cloud Run e os clusters do GKE podem ser criados e administrados completamente do console e da linha de comando.
O melhor disso é que é possível mudar sua escolha, alternando do Cloud Run gerenciado ao Cloud Run para Anthos ou vice-versa, sem precisar implementar o serviço novamente.
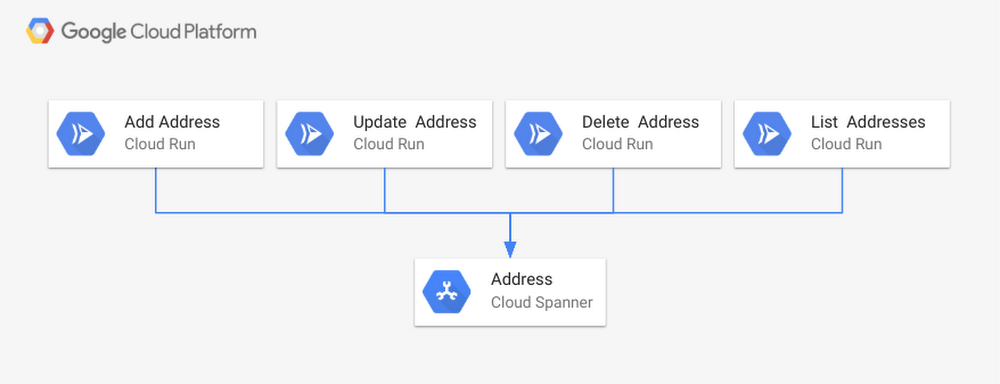
Para ilustrar esses pontos, vejamos um exemplo de caso de uso: um serviço que adiciona, atualiza, exclui e lista endereços.
É possível implementar esse serviço de gerenciamento de endereços por meio da criação de um microsserviço em contêiner para cada operação. Após as imagens terem sido criadas e registradas em um registro de contêiner, você pode implantá-las no Cloud Run gerenciado com apenas um comando. Quando os quatro comandos forem executados (uma implantação para cada microsserviço), o serviço estará ativo e operará em uma plataforma completamente sem servidor. A imagem a seguir mostra a implantação usando o Cloud Spanner como o banco de dados subjacente.
Para casos de uso como esse, o Cloud Run gerenciado é uma ótima escolha porque o serviço de gerenciamento de endereços não exige configurações complexas, de acordo com o que é compatível com o Kubernetes. Além disso, esse serviço não precisa de gerenciamento de cluster 24 horas por dia nem supervisão operacional. A execução desse serviço de gerenciamento de endereços como contêineres no Cloud Run é a melhor estratégia para a carga de trabalho de produção.
Por ser uma plataforma de computação gerenciada, o Cloud Run gerenciado é compatível com configurações essenciais: é possível definir as solicitações simultâneas máximas que um único contêiner recebe, o tamanho da memória de alocação para o contêiner e o tempo limite da solicitação. Não são necessárias configurações nem operações de gerenciamento adicionais.
O Cloud Run gerenciado e o GKE são ofertas poderosas para diferentes casos de uso. Antes de escolher, verifique se entendeu os requisitos de serviço funcionais e não funcionais, como a capacidade de escalonar para zero ou de controlar a configuração detalhada.
Pode ser que você queira usar as duas opções ao mesmo tempo. Uma empresa pode ter aplicativos complexos com base em microsserviços que exijam os recursos avançados de configuração do GKE e outros que, mesmo sem essa necessidade, queiram aproveitar a facilidade de uso e a escalonabilidade do Cloud Run.
Para saber mais sobre o Cloud Run, acesse nosso site e siga o guia rápido.
As primeiras impressões são muito importantes no local de trabalho. Muitas vezes, elas ocorrem por meio de documentos ou apresentações que compartilhamos com outras pessoas. Erros ortográficos ou gramaticais podem causar distrações e fazer com que uma proposta pareça não profissional, algo que todos nós queremos evitar. Estamos focados em oferecer recursos de escrita mais úteis no G Suite para auxiliar você a fazer seu melhor trabalho. Por isso, no começo do ano, apresentamos as novas ferramentas de correção gramatical no Documentos Google para ajudar as pessoas a escrever de forma mais rápida e precisa. Com a ajuda do aprendizado de máquina, já são mais de 100 milhões de sugestões de gramática sinalizadas a cada semana.
Avanço das sugestões de gramática com a tradução automática neuralAtualmente, o sistema de correção gramatical do Google usa a tecnologia de tradução automática. Cada sugestão é tratada como uma tarefa de tradução. Nesse caso, o conteúdo é traduzido do idioma da “gramática incorreta” para o idioma da “gramática correta”. Em um nível básico, a tradução automática substitui e reorganiza as palavras de um idioma de origem para um idioma de destino. Por exemplo, a substituição de uma palavra originária do inglês (“hello”) para uma palavra em espanhol (“hola”).
Com os avanços mais recentes da nossa equipe de pesquisa na área de processamento de linguagens, possibilitados pela tradução automática neural, estamos melhorando significativamente a maneira como corrigimos erros linguísticos por meio da correção de gramática neural no Documentos Google.
Como funcionaComo a Correção de erros gramaticais (GEC, na sigla em inglês) pode ser vista como uma “tradução” de sentenças gramaticalmente erradas para frases corretas, é possível aplicar modelos sequenciais desenvolvidos para tradução automática neural a essa tarefa. Para treinar modelos de qualidade, geralmente precisamos de milhões ou bilhões de exemplos de dados paralelos em que cada amostra de treinamento consista em uma sentença no idioma de origem pareada com a tradução no idioma de destino. Ao contrário de outras tarefas de tradução automática (como traduzir do inglês para o francês), há pouquíssimos dados paralelos para GEC. Com o objetivo de superar esse desafio, desenvolvemos dois métodos contrastantes para gerar grandes quantidades de dados paralelos para GEC.
O primeiro método traduz sentenças corretas para algum outro idioma e, em seguida, passa novamente para inglês, causando perda de qualidade.
O segundo método extrai pares origem/destino dos históricos de edição da Wikipédia com uma quantidade mínima de filtros.
Você pode ler mais sobre GEC e algumas das nossas abordagens neste artigo.
Para garantir que seria viável implantar os modelos no Documentos Google sem usar uma quantidade absurda de recursos de computação, usamos Unidades de Processamento de Tensor (TPUs, na sigla em inglês). As TPUs forneceram aumentos substanciais no desempenho de muitos outros produtos do Google, inclusive a Escrita inteligente no Gmail. Além disso, usamos a biblioteca do TensorFlow de código aberto do Google, Lingvo. Com ela, foi possível testar facilmente alterações de modelagem e otimizar de forma cuidadosa como as sugestões seriam geradas pelos núcleos de TPU.
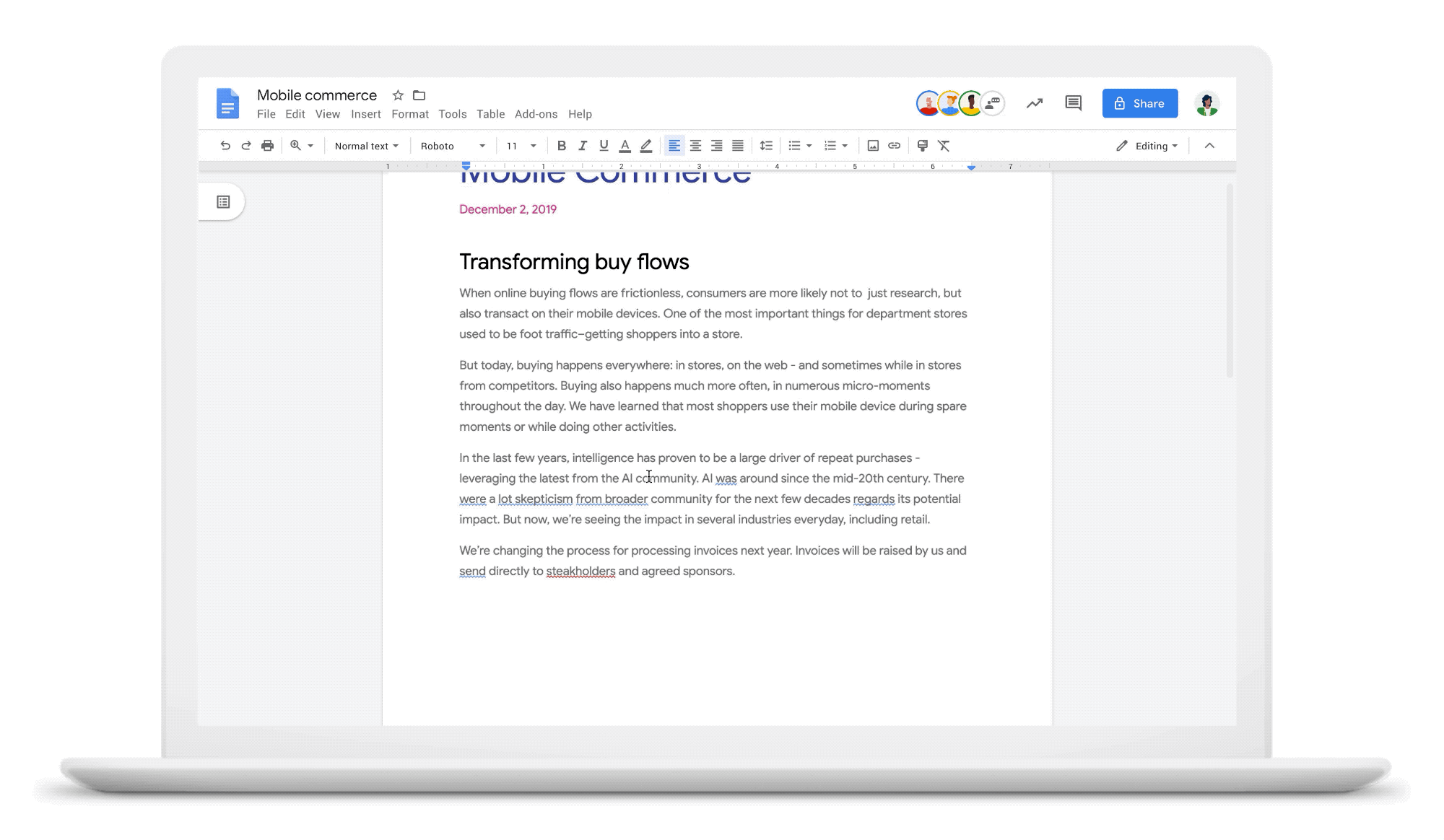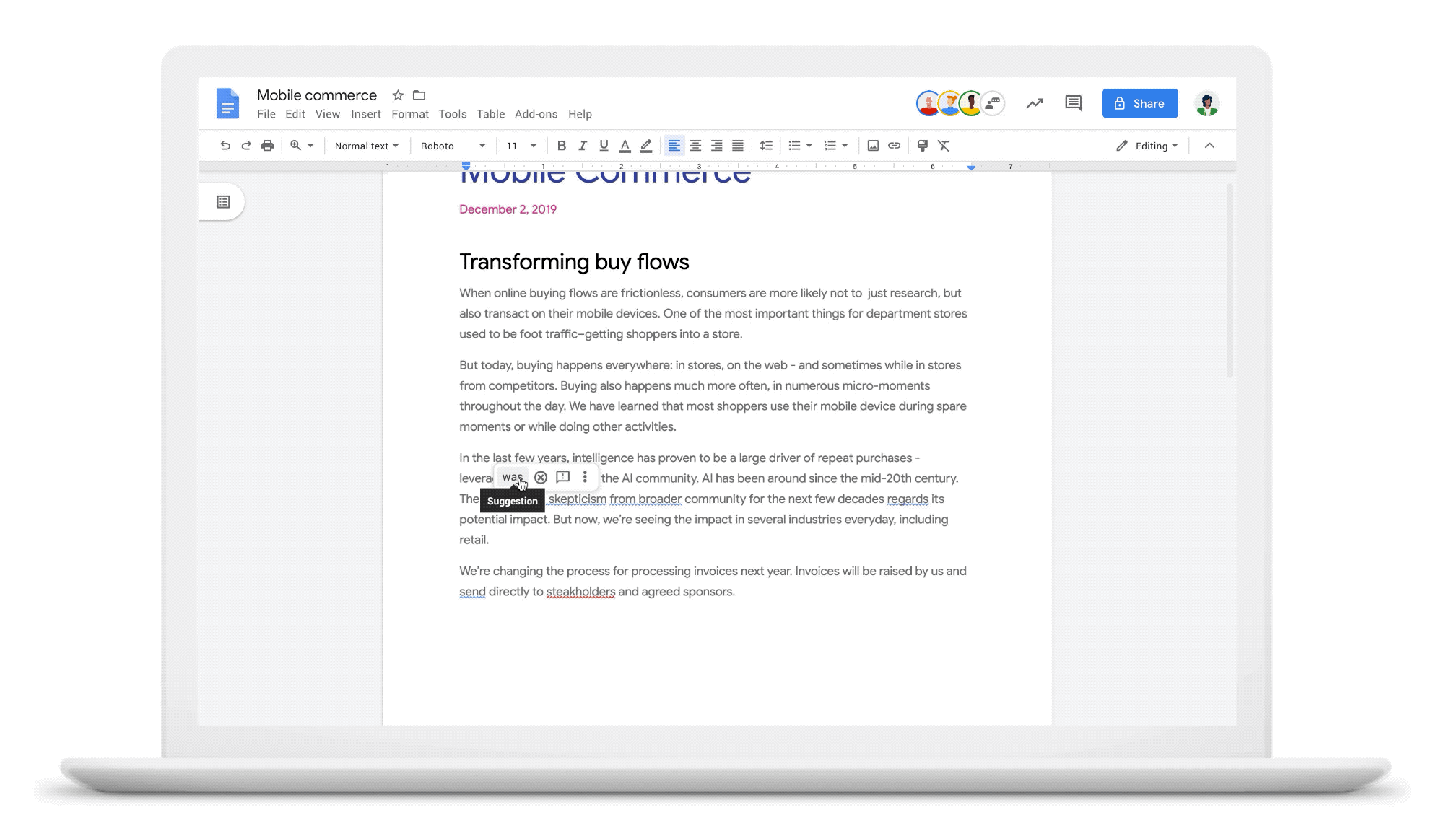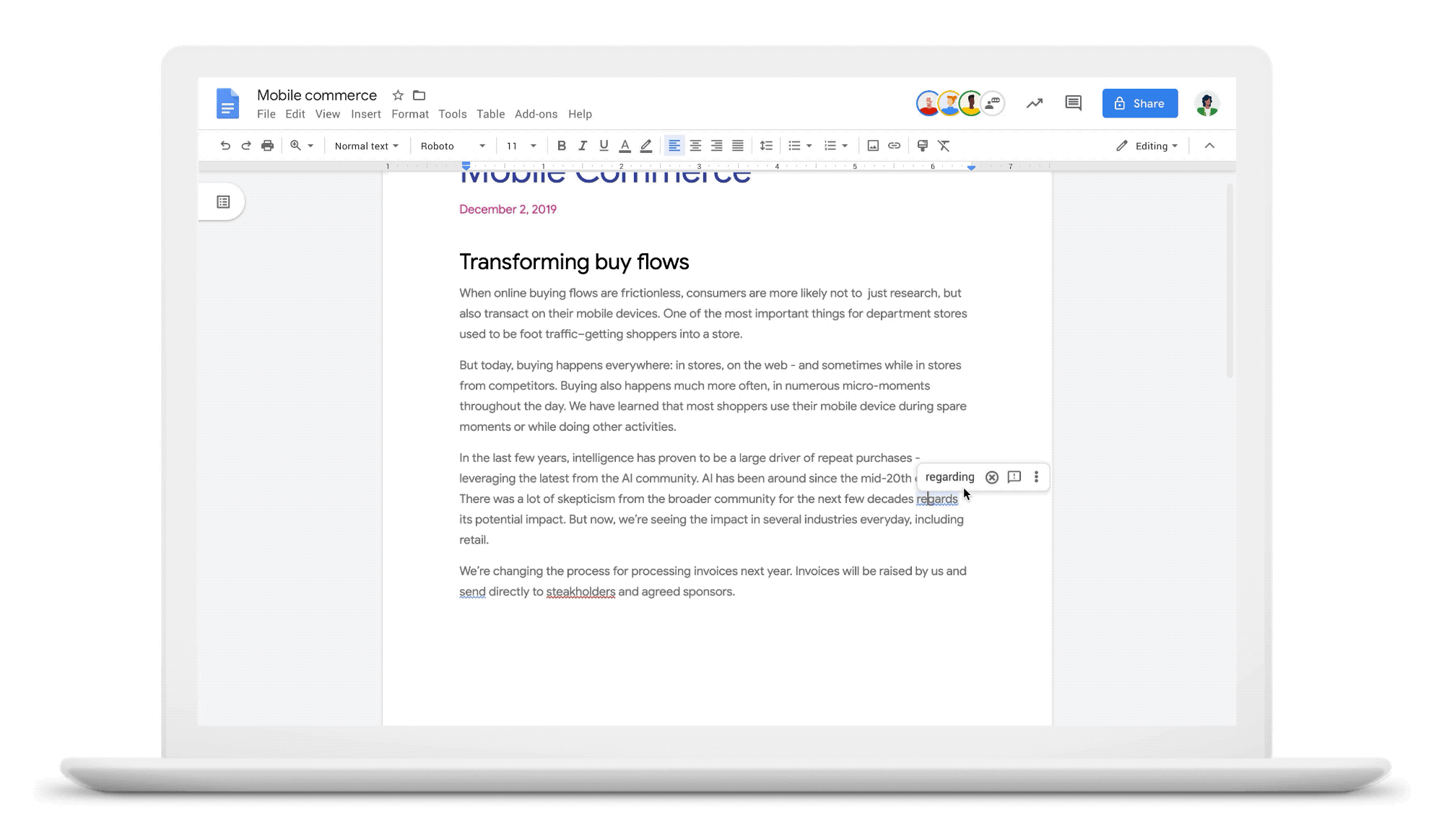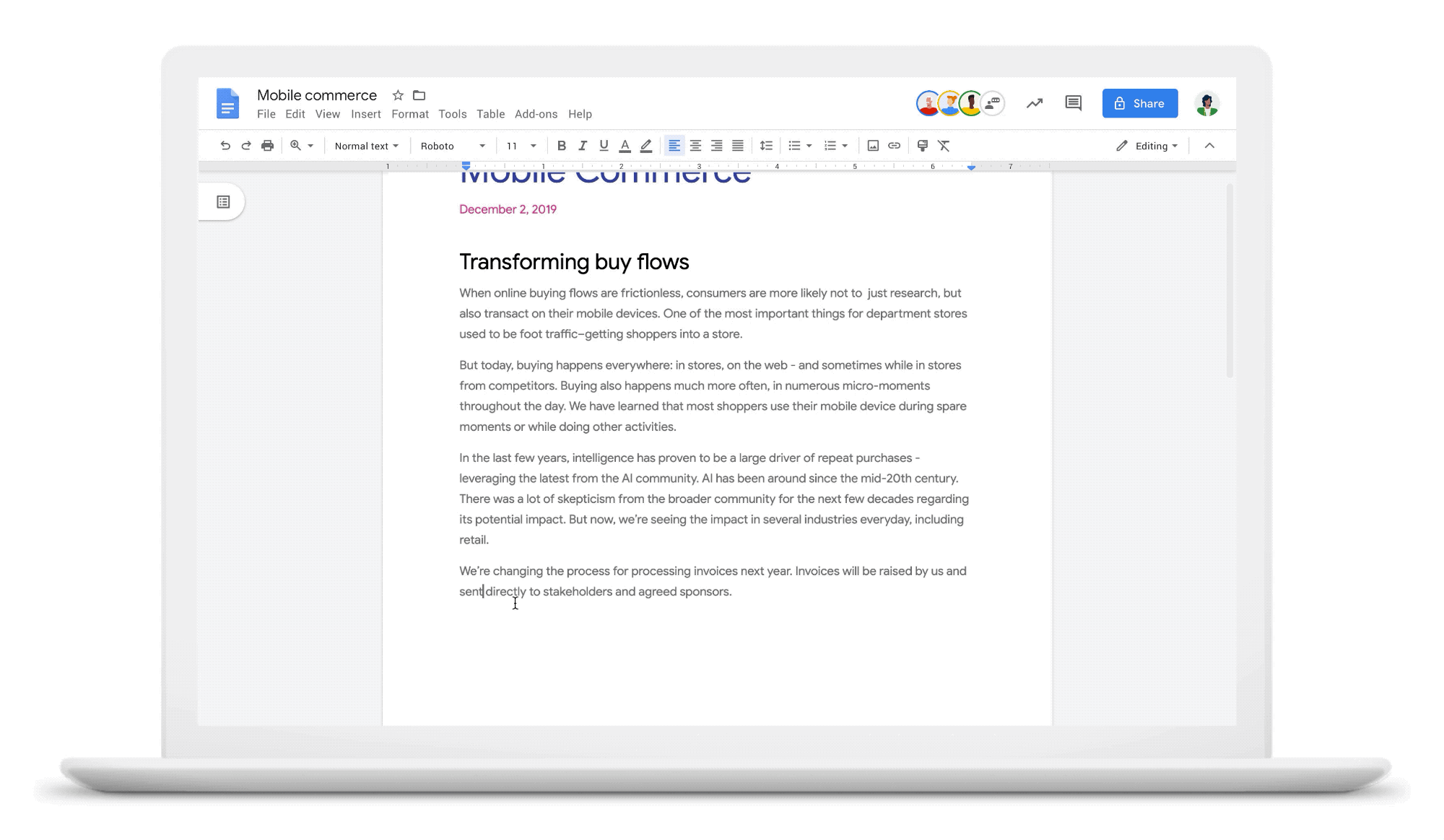
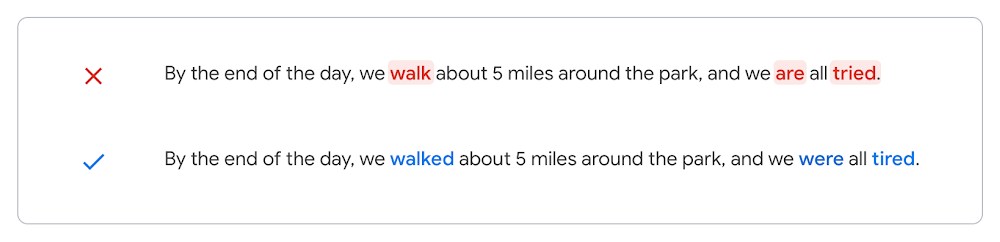
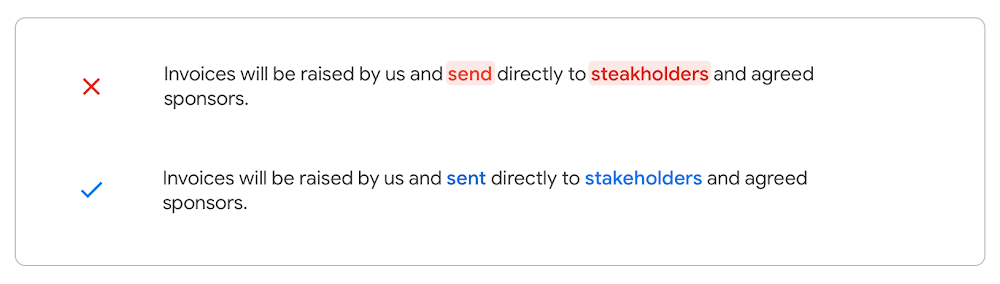
O que isso significa para os redatoresQual o significado disso para você? Ao aplicar modelos de tradução automática neural à correção gramatical, conseguimos corrigir muitos outros erros gramaticais que você pode cometer enquanto escreve. Para lançar essas melhorias, fizemos muitos testes com o objetivo de garantir que as mudanças sejam mais úteis. Veja alguns exemplos do nosso processo de avaliação que demonstram os recursos da correção de gramática neural:
Qual o tempo verbal mesmo?
O correto é “steak” ou “stake”?
A mudança para o método de tradução automática neural apresenta um aumento notável no resultado de sugestões de correção gramatical no Documentos Google. Esperamos que essa atualização possa continuar facilitando sua escrita.
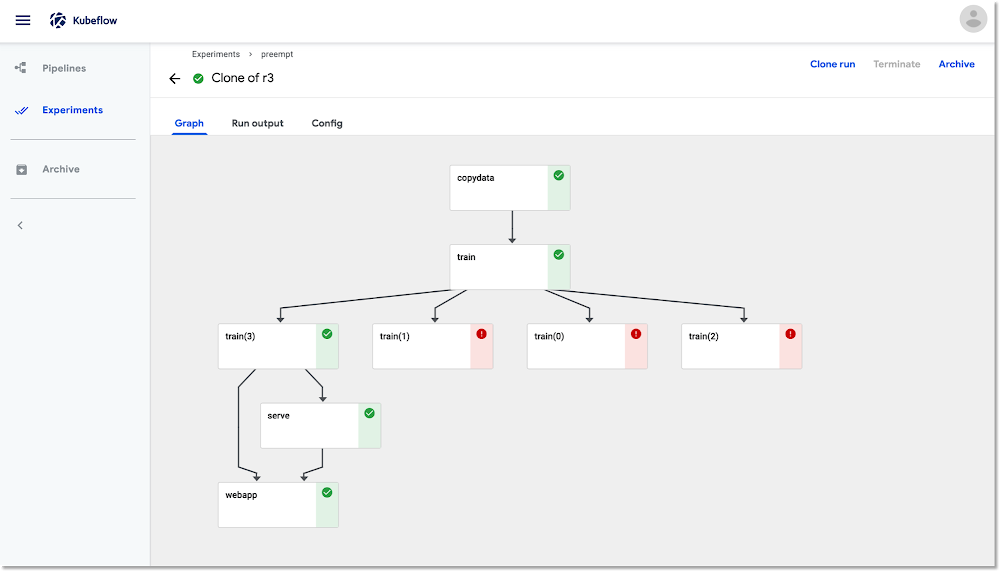
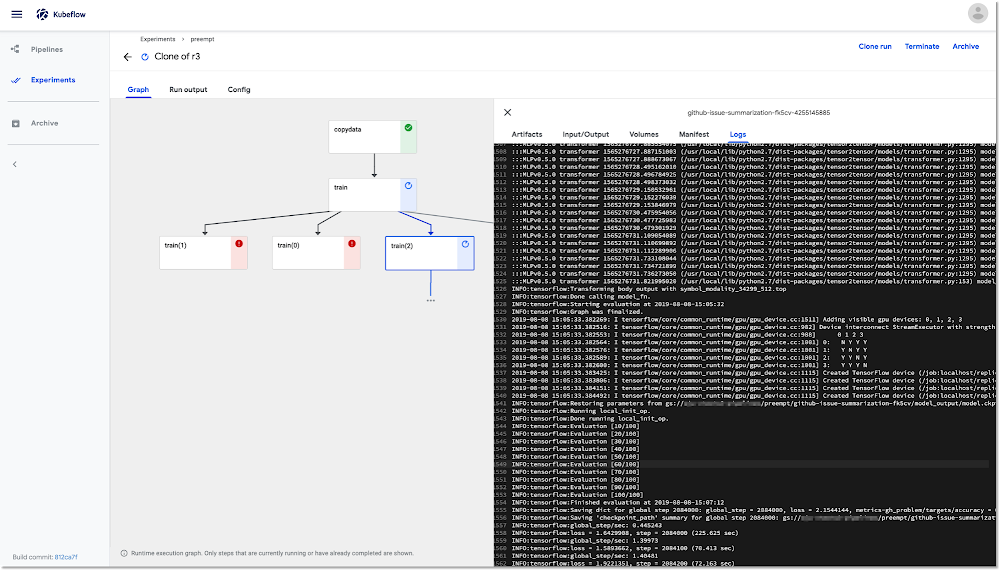
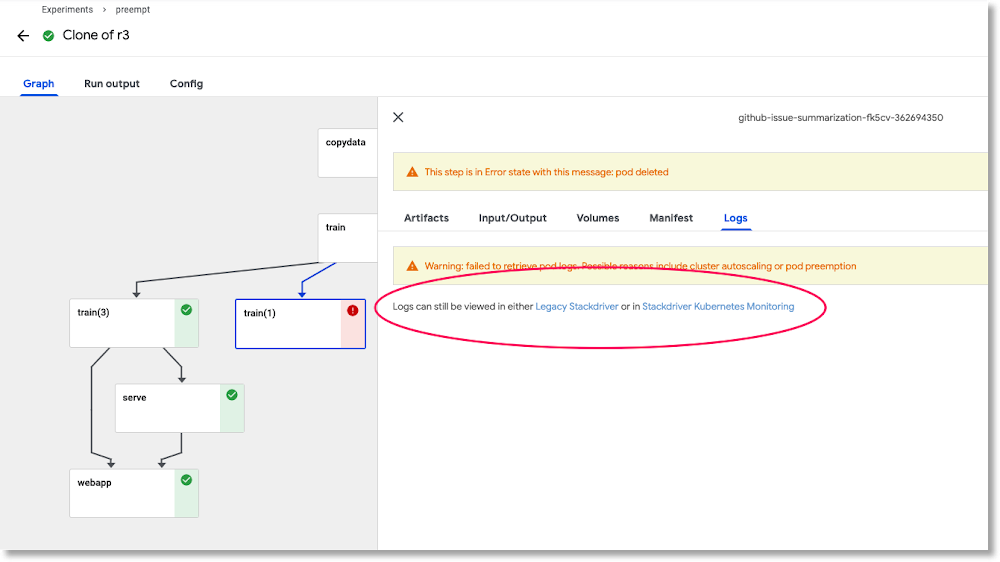
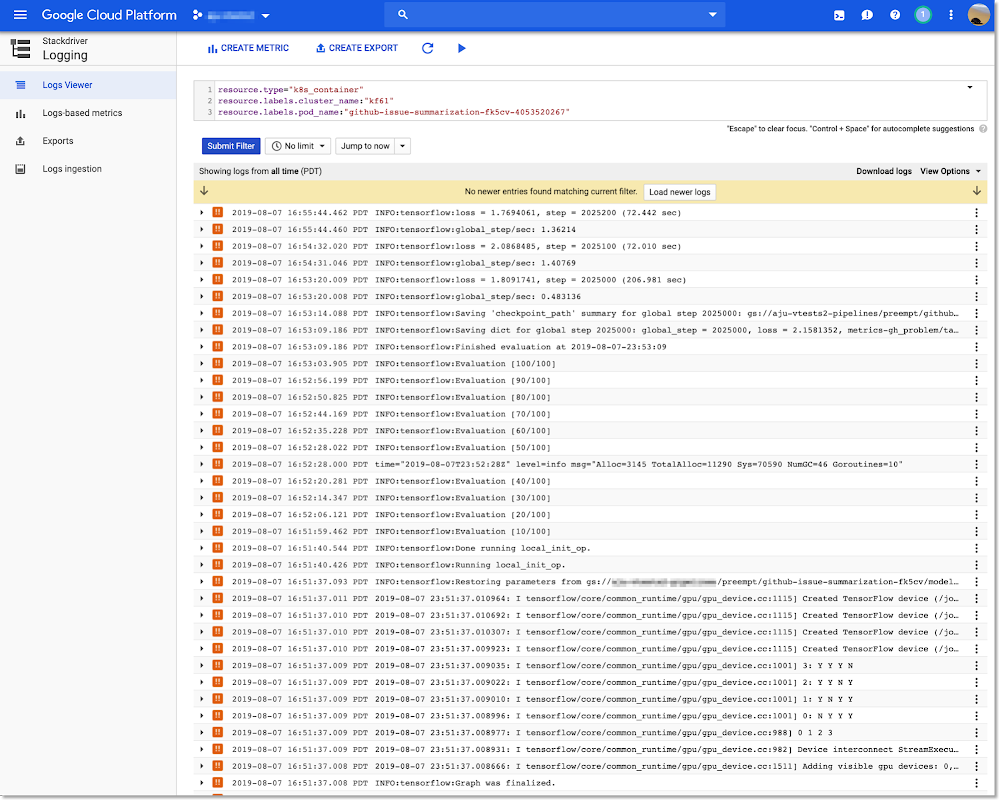
use_preemptible_nodepool()
copydata
train
train(2)
"invisible"
"activatable"
autofocus
font-optical-sizing
list-style-type
disc
decimal
::before
list-style-position
Worklet.addModule()
AbortError
SyntaxError
self.serviceWorker
self.serviceWorker.state
error
load
<script>
A Hugging Face é a startup líder em PLN com mais de mil empresas, incluindo Bing, Apple e Monzo, usando a biblioteca da organização em processos de produção. Todos os exemplos usados neste tutorial estão disponíveis no Colab. Encontre os links nas seções correspondentes.
A Hugging Face é uma startup focada no PLN e tem uma grande comunidade que trabalha em código aberto, usando especialmente a biblioteca Transformers. A 🤗/Transformers é uma biblioteca baseada em python que expõe uma API para o uso de diversas arquiteturas de transformação conhecidas, como BERT, RoBERTa, GPT-2 ou DistilBERT. Esses recursos geram resultados de ponta em diferentes tarefas do PLN, como classificação de texto, extração de informações, resposta a perguntas e geração de texto. Essas arquiteturas são pré-treinadas com vários conjuntos de pesos. Para dar os primeiros passos com a Transformers, você só precisa instalar o pacote pip:
pip install transformers
A biblioteca teve um crescimento veloz no PyTorch e foi portada recentemente para o TensorFlow 2.0, oferecendo uma API que funciona com a API fit do Keras, o TensorFlow Extended e TPUs 👏. Esta postagem do blog é dedicada ao uso da biblioteca Transformers com o TensorFlow. Com a API do Keras e o TPUStrategy do TensorFlow, é possível ajustar um modelo de transformação de última geração.
A Transformers é baseada no conceito de modelos de transformação pré-treinados. Esses modelos de transformação têm diferentes formas, tamanhos e arquiteturas e incluem maneiras próprias de aceitar dados de entrada: via tokenização.
A biblioteca é baseada em três classes principais: configuração, tokenização e modelo.
A vantagem da biblioteca Transformers está no uso de uma API simples e independente de modelo. O carregamento de um modelo pré-treinado, junto com o tokenizador, pode ser feito usando algumas linhas de código. Veja um exemplo de carregamento de modelos BERT e GPT-2 do TensorFlow, bem como os tokenizadores relacionados:
Os pesos são transferidos por download do intervalo S3 da Hugging Face e armazenados em cache localmente na sua máquina. Os modelos estão prontos para inferências ou podem ser ajustados, se necessário. Vejamos como isso funciona na prática.
Graças a alguns métodos disponíveis na biblioteca Transformer, ficou mais fácil ajustar um modelo. As partes a seguir são criadas da seguinte forma:
Criamos um notebook do Colab para ajudar você com o processo de codificação. Aproveitaremos o pacote tensorflow_datasets para o carregamento de dados. O Tensorflow-dataset oferece um tf.data.Dataset, que pode ser alimentado no nosso método glue_convert_examples_to_features.
Esse método utilizará o tokenizador para tokenizar a entrada e adicionar tokens especiais no início e no final das sequências, caso eles sejam exigidos pelo modelo (como [SEP], [CLS], </s> ou <s>, por exemplo). Isso retornará um tf.data.Dataset contendo as entradas com recursos.
Em seguida, podemos usar uma ordem aleatória desse conjunto de dados e agrupá-lo em lotes de 32 unidades usando os métodos padrão tf.data.Dataset.
Treinar um modelo usando o método fit do Keras nunca foi tão simples. Agora que temos a configuração do canal de entrada, podemos definir os hiperparâmetros e chamar o método fit do Keras com nosso conjunto de dados.
Usar uma estratégia oferece a você um controle maior sobre o que acontece durante o treinamento. Ao alternar entre estratégias, o usuário pode selecionar a forma distribuída usada para treinar o modelo: de várias GPUs a TPUs.
Até o momento, o TPUStrategy é a única maneira certeira de treinar um modelo em uma TPU usando o TensorFlow 2. Criar um loop personalizado usando uma estratégia é ainda mais útil, já que as estratégias podem ser facilmente alternadas, e o treinamento em várias GPUs não exige quase mudanças no código.
A configuração desse loop é um pouco trabalhosa. Por isso, aconselhamos você a abrir o notebook do Colab a seguir para ter uma melhor compreensão do assunto em questão. Você não encontrará detalhes sobre a tokenização como na primeira edição, mas verá como criar um canal de entrada que será usado pelo TPUStrategy.
O recurso usa o intervalo do Google Cloud Platform para hospedar dados, devido à complexidade do gerenciamento de TPUs em sistemas de arquivos locais. O notebook do Codelab está disponível aqui.
A principal vantagem da biblioteca Transformers é seu modelo de API simples e independente. Ao atuar como um front-end para modelos que geram resultados avançados em PLN, ela facilita muito a alternância entre modelos de acordo com a tarefa em questão.
Como exemplo, veja o script completo para ajustar BERT em uma tarefa de classificação idiomática (MRPC):
No entanto, em um ambiente de produção, a memória é escassa. Você poderia usar um modelo menor e mudar para DistilBERT, por exemplo. Para isso, basta alterar as duas primeiras linhas para as novas opções:
Como uma plataforma que hospeda mais de 10 arquiteturas de transformação, a 🤗/Transformers facilita o uso, o ajuste e a comparação dos modelos que transfiguraram o aprendizado detalhado para o campo do PLN. O recurso funciona como back-end para muitos aplicativos descendentes que utilizam modelos de transformação e é usado nos processos de produção em diversas empresas diferentes. Se você tiver perguntas ou questões, use nosso repositório do GitHub.
Kevin Chyn, biblioteca do Android
Curtis Belmonte, biblioteca do Android
Com o lançamento do Android 10 (API de nível 29), os desenvolvedores agora podem usar a API biométrica, parte da biblioteca AndroidX Biometric, para todas as necessidades de autenticação do usuário no dispositivo. A equipe da biblioteca e segurança do Android adicionou diversos recursos significativos à biblioteca AndroidX Biometric.Com isso, todo o comportamento biométrico do Android 10 é disponibilizado a todos os dispositivos que executam o Android 6.0 (API de nível 23) ou versões posteriores. A API é compatível com vários formatos de autenticação biométrica. Com ela, os desenvolvedores podem verificar com muito mais facilidade se determinado dispositivo tem sensores biométricos. Caso não haja nenhum sensor biométrico, a API permitirá que os desenvolvedores especifiquem se querem usar as credenciais do dispositivo nos aplicativos.
Os recursos não beneficiam apenas os desenvolvedores. Fabricantes de dispositivos e OEMs também têm bastante a comemorar. A biblioteca agora oferece uma API otimizada e padronizada para OEMs integrarem suporte a todos os tipos de sensores biométricos nos dispositivos. Além disso, a biblioteca tem suporte integrado para autenticação facial no Android 10. Assim, os fornecedores não precisam criar uma implementação personalizada.
A classe FingerprintManager foi introduzida no Android 6.0 (API de nível 23). Atualmente, e até o Android 9 (API de nível de 28), a API era compatível somente com sensores de impressão digital e sem IU. Os desenvolvedores precisavam criar uma IU de impressão digital própria.
FingerprintManager
Com base no feedback dos desenvolvedores, o Android 9 introduziu uma política da IU de impressão digital padronizada. O BiometricPrompt também foi introduzido para abranger mais sensores além da impressão digital. Além de fornecer uma IU segura e familiar para autenticação do usuário, isso permitiu que uma pequena superfície de API mantida pelos desenvolvedores acessasse a variedade de hardware biométrico disponível em dispositivos OEM. Agora, os OEMs podem personalizar a IU com os recursos e a iconografia necessários para expor novas biometrias, como contornos de sensores em exibição. Com isso, os desenvolvedores de aplicativos não precisam se preocupar em executar implementações personalizadas específicas de dispositivos para autenticação biométrica.
BiometricPrompt
Ou seja, no Android 10, a equipe introduziu alguns recursos essenciais para transformar a API biométrica em um balcão único para a autenticação do usuário no aplicativo. Com o BiometricManager, os desenvolvedores podem verificar se um dispositivo é compatível com a autenticação biométrica. Além disso, o método setDeviceCredentialAllowed() foi adicionado para oferecer aos desenvolvedores a opção de usar o PIN, o padrão ou a senha de um dispositivo em vez da credencial biométrica, caso faça sentido para o aplicativo.
BiometricManager
setDeviceCredentialAllowed()
A equipe incluiu todos os recursos biométricos do Android 10 à dependência Gradle do androidx.biometric. Assim, uma interface única e consistente é disponibilizada até o Android 6.0 (API de nível 23).
androidx.biometric
A dependência Gradle do androidx.biometric é uma biblioteca de suporte para as classes Biometric da biblioteca Android. Na API 29 e versões posteriores, a biblioteca usa as classes em android.hardware.biometrics e FingerprintManager até a API 23 e a credencial de confirmação até a API 21. Devido à variedade de APIs, é altamente recomendado usar a biblioteca de suporte androidx, independentemente do nível de API executado no seu aplicativo.
Biometric
android.hardware.biometrics
androidx
Para usar a API biométrica no seu aplicativo, siga as etapas abaixo:
$biometric_version é a versão mais recente da biblioteca
$biometric_version
def biometric_version= '1.0.0-rc02' implementation "androidx.biometric:biometric:$biometric_version"
O BiometricPrompt precisa ser recriado todas as vezes que houver a criação de Activity/Fragment. Isso precisa ser feito no onCreate() ou onCreateView() para que BiometricPrompt.AuthenticationCallback possa começar a receber os callbacks adequadamente.
Activity
Fragment
onCreate()
onCreateView()
BiometricPrompt.AuthenticationCallback
Para verificar se o dispositivo é compatível com a autenticação biométrica, adicione a lógica a seguir:
val biometricManager = BiometricManager.from(context) if (biometricManager.canAuthenticate() == BiometricManager.BIOMETRIC_SUCCESS){ // TODO: show in-app settings, make authentication calls. }
O construtor BiometricPrompt requer um Executor e um objeto AuthenticationCallback. Com o Executor, é possível especificar um thread que será usado para a execução dos callbacks.
Executor
AuthenticationCallback
O AuthenticationCallback tem três métodos:
onAuthenticationSucceeded()
onAuthenticationError()
onAuthenticationFailed()
O snippet a seguir mostra uma maneira de implementar o Executor e como instanciar o BiometricPrompt:
private fun instanceOfBiometricPrompt(): BiometricPrompt { val executor = ContextCompat.getmainExecutor(context) val callback = object: BiometricPrompt.AuthenticationCallback() { override fun onAuthenticationError(errorCode: Int, errString: CharSequence) { super.onAuthenticationError(errorCode, errString) showMessage("$errorCode :: $errString") } override fun onAuthenticationFailed() { super.onAuthenticationFailed() showMessage("Authentication failed for an unknown reason") } override fun onAuthenticationSucceeded(result: BiometricPrompt.AuthenticationResult) { super.onAuthenticationSucceeded(result) showMessage("Authentication was successful") } } val biometricPrompt = BiometricPrompt(context, executor, callback) return biometricPrompt }
A instanciação do BiometricPrompt precisa ser concluída no início do ciclo de vida do fragmento ou da atividade (por exemplo,em onCreate ou onCreateView). Isso garante que a instância atual sempre receberá adequadamente os callbacks de autenticação.
onCreate
onCreateView
Após ter um objeto BiometricPrompt, chame biometricPrompt.authenticate(promptInfo) para solicitar a autenticação ao usuário. Se o aplicativo exigir que o usuário autentique usando uma biometria forte ou precisar executar operações criptográficas no repositório de chaves, use authenticate(PromptInfo, CryptoObject).
biometricPrompt.authenticate(promptInfo)
authenticate(PromptInfo, CryptoObject)
Essa chamada mostrará a IU adequada ao usuário, com base no tipo da credencial biométrica usada para autenticação, como impressão digital, rosto ou íris. Como desenvolvedor, você não precisa saber qual o tipo de credencial é usado para autenticação, a API cuida disso tudo para você.
Essa chamada requer um objeto BiometricPrompt.PromptInfo. Um PromptInfo é onde você define o texto exibido na solicitação: como o título, subtítulo e a descrição. Sem um PromptInfo, não fica claro ao usuário final qual aplicativo está solicitando a credencial biométrica. Com o PromptInfo também é possível especificar se será permitido que dispositivos incompatíveis com a autenticação biométrica concedam acesso por meio das credenciais do dispositivo, como senha, PIN ou padrão usados para desbloquear o dispositivo.
BiometricPrompt.PromptInfo
PromptInfo
Veja este exemplo de loop de declaração PromptInfo:
private fun getPromptInfo(): BiometricPrompt.PromptInfo { val promptInfo = BiometricPrompt.PromptInfo.Builder() .setTitle("My App's Authentication") .setSubtitle("Please login to get access") .setDescription("My App is using Android biometric authentication") .setDeviceCredentialAllowed(true) .build() return promptInfo }
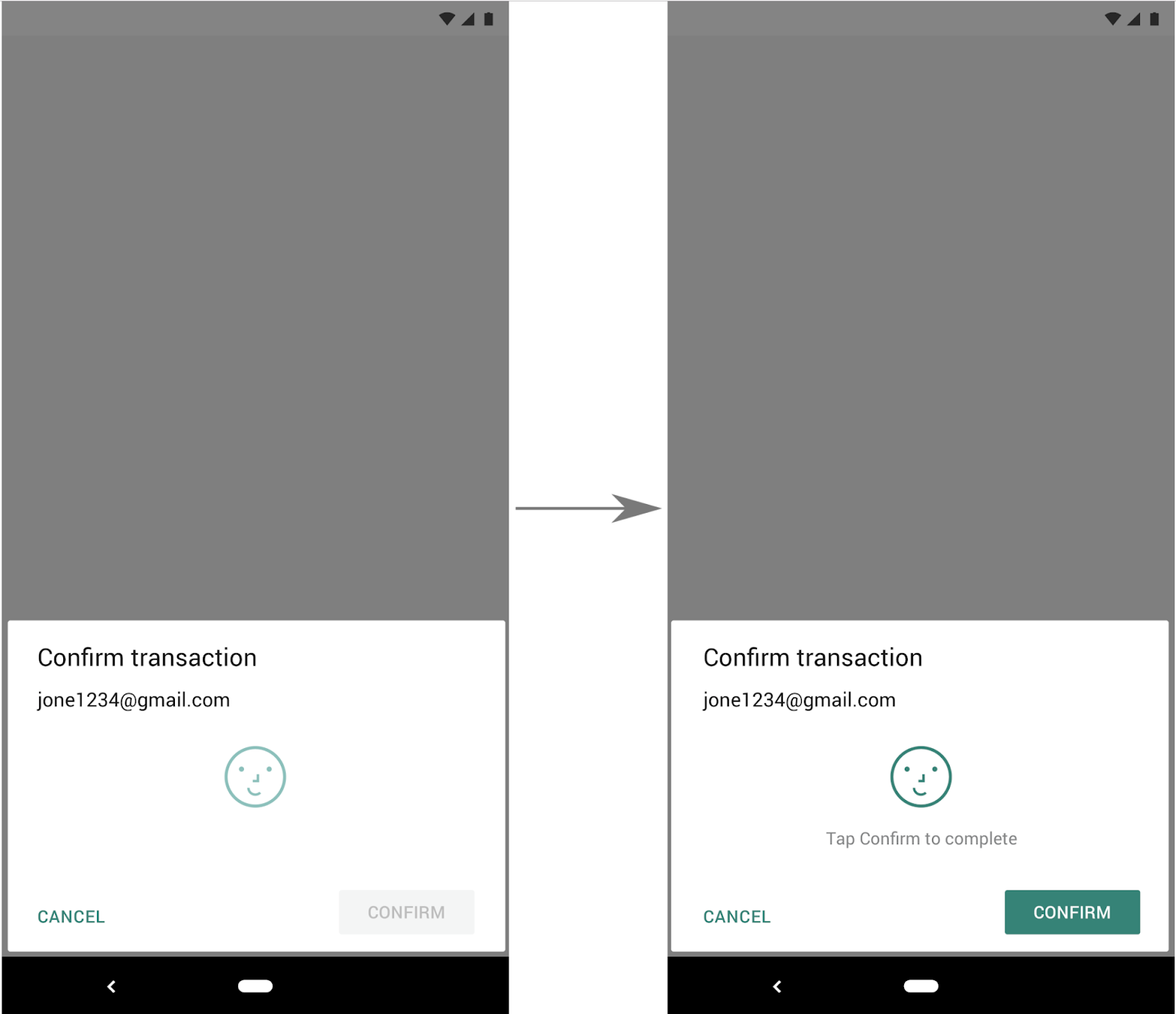
Para ações que requerem uma etapa de confirmação, como transações e pagamentos, recomendamos usar a opção padrão: setConfirmationRequired(true). Ela adicionará um botão de confirmação à IU, conforme exibido na Imagem 2.
setConfirmationRequired(true)
setConfirmationRequired(false)
Agora que já realizou todas as etapas obrigatórias, solicite a autenticação do usuário.
val canAuthenticate = biometricManager.canAuthenticate() if (canAuthenticate == BiometricManager.BIOMETRIC_SUCCESS) { biometricPrompt.authenticate(promptInfo) } else { Log.d(TAG, "could not authenticate because: $canAuthenticate") }
Está tudo pronto! Agora você pode executar a autenticação, usando credenciais biométricas, em qualquer dispositivo que opere no Android 6.0 (API de nível 23) ou versões posteriores.
Como o ecossistema continua a evoluir rapidamente, a equipe da biblioteca do Android pensa constantemente em formas de oferecer suporte a longo prazo para OEMs e desenvolvedores. Devido à IU com base no sistema consistente da biblioteca biométrica, os desenvolvedores não precisam se preocupar com requisitos específicos do dispositivo, e os usuários têm uma experiência mais confiável.
Será ótimo receber feedback de desenvolvedores e OEMs sobre como fortalecer, simplificar a utilização e melhorar o suporte de diversos casos de uso.
Para ver exemplos detalhados que exibem casos de uso adicionais e demonstram como você pode integrar essa biblioteca ao seu aplicativo, confira nosso repositório. Ele contém aplicativos de amostra funcionais que usam a biblioteca. Também é possível ler o guia do desenvolvedor associado e a referência da API para saber mais.