Postagem de Yuqian Li e Shams Zakhour
A velocidade é um valor fundamental para o Flutter. Este artigo destaca as melhorias de desempenho que foram implementadas por membros da comunidade do Flutter a partir do segundo semestre de 2019. Sim, estamos atrasados, mas antes tarde do que nunca!
Caso você tenha contribuído com o desempenho do Flutter em 2020, abordaremos essas atualizações em uma publicação futura. Ao compartilhar estes resultados com você e a comunidade do Flutter, esperamos inspirar a todos a continuar contribuindo!
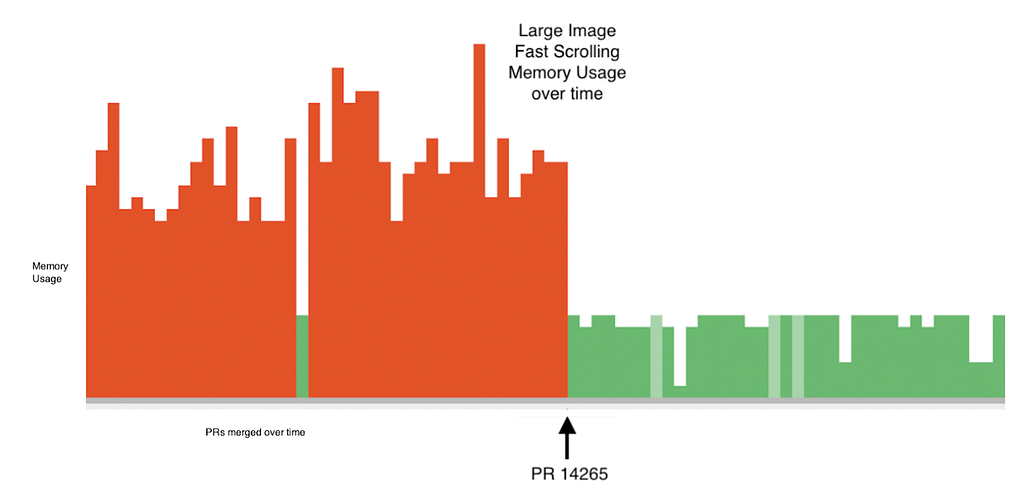
70% de redução de memória na rolagem rápida de imagens grandescolaboradores: liyuqian, dnfield e chinmaygarde
Redução de 40% no uso de CPU/GPU em animações simples para iOScolaboradores: flar, liyuqian, hixie e chinmaygarde
Aceleração de 41% no desempenho do cursorcolaboradores: garyqian, liyuqian e justinmc
Aceleração de 10% para rolagem de lista com a correção do limite do cache de varreduracolaboradores: liyuqian, chinmaygarde, flar, cyanglaz e zsunkun
Aceleração de 37x para o tempo de carregamento de referências em cache (Painel)colaboradores: caseyhillers, tvolkert, digiter e jonahwilliams
Aceleração de 2,3x em APKs de compilaçãocolaboradores: jonahwilliams, blasten, zanderso e xster
Mais de 103 métricas de desempenho registradas por confirmação do mecanismo Fluttercolaboradores: liyuqian, digiter, keyonghan, godofredoc e cbracken
Redução de 20% no tamanho do aplicativocolaboradores: mraleph, alexmarkov, rmacnak-google, mkustermann, sstrickl e aartbik
Aceleração de 108x no desempenho do Dart FFIcolaboradores: dcharkes, mkustermann, sjindel e alexmarkov
10 a 15% de melhoria no desempenho em código restritocolaboradores: aartbik, mkustermann e mraleph
Aceleração de 2,2x no teste do Flutter com o novo serializador incrementalcolaboradores: jensjoha e alexmarkov
Serialização binária do kernel 10% mais rápida, oferecendo dicas em linha ao JIT do Dart VMcolaboradores: jensjoha e johnniwinther
30% de melhoria no desempenho em código pesado assíncronocolaboradores: cskau-g, mkustermann e mraleph
Correção de vazamento de memória ao usar PlatformView no iOS
Mais correções de vazamento de memória no iOS
Início da reformulação das páginas de desempenho no flutter.dev e inclusão de instruções sobre como medir o tamanho do aplicativo.
Correção da primeira lógica de espera e medição de frames
O DevTools adicionou o modo de linha do tempo completo com suporte para rastreamento assíncrono e gravado.
O plugin IntelliJ corrigiu o suporte para 120 FPS
Muitas melhorias no rastreamento da linha do tempo graças ao ByteDance
Aceleração de 1,5–5x para transformações rect e pointcolaboradores: flar, yjbanov e dnfield
N/2–1 poucos frames perdidos na rolagem do iPhone X/Xscolaboradores: liyuqian, chinmaygarde e gaaclarke
15% mais rapidez na inicialização e no encerramento do mecanismo com a inicialização paralelacolaboradores: gaaclarke, chinmaygarde e liyuqian
Inicialização 14,57 ms mais rápida e uso de memória 8 MB menor para aquecimento do sombreadorcolaboradores: gaaclarke, liyuqian e dnfield
Redução de 1,02%-8,04% no tamanho do códigocolaboradores: johnniwinther, aartbik, rmacnak-google, jensjoha, alexmarkov e mkustermann
Aumento de até 2x na taxa de FPS do Fuchsia para o Flutter, com agendamento de frames aprimoradocolaboradores: dreveman, amott, rosswang e mikejurka
Aceleração de 3x para BackdropFilter no iOScolaboradores: lhkbob, liyuqian e flar
Para alcançar altos níveis de melhoria (por exemplo, 3x), o mau desempenho do estado antigo provavelmente foi tão importante quanto o esforço realizado no terceiro trimestre (de julho a setembro) de 2019. Também marcamos algumas melhorias como correções significativas de regressões igualmente importantes. No entanto, somos muito gratos por essas contribuições. Sem elas, ainda teríamos resultados ruins em relação ao desempenho e às regressões. Nossa intenção não é desvalorizar as melhorias menores em detrimento das grandes. Apenas destacamos que não havia um desempenho muito ruim para ser melhorado, o que é também um bom sinal.
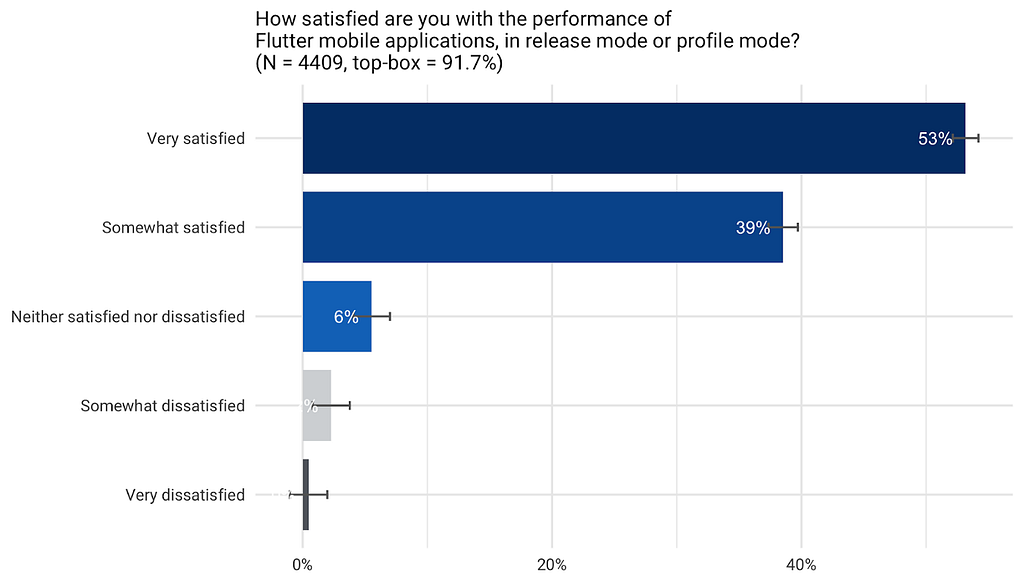
Graças a essas contribuições da nossa comunidade, a proporção de usuários positivamente satisfeitos com o desempenho do Flutter em dispositivos móveis aumentou de 85% no terceiro trimestre de 2019 para 92% em 2020. Apesar do nosso esforço, talvez nem todas as contribuições de desempenho realizadas no terceiro e no quarto trimestres de 2019 tenham sido incluídas nesta atualização. Caso você não tenha encontrado alguma contribuição recente nesta publicação, avise nossa equipe para que possamos inclui-la na próxima atualização.
Esta é a segunda edição de uma série dividida em duas partes sobre as Novidades dos criadores de perfil no Android Studio 4.1. Nossa postagem anterior abordou as Novidades do System Trace.
Para os desenvolvedores de C++, fazer a depuração de memória nativa pode ser bastante difícil, principalmente em jogos. Com o Android Studio 4.1, implementamos a capacidade de gravar pilhas de chamadas de alocações de memória nativa no nosso Memory Profiler. A gravação de memória nativa é integrada ao back-end do Perfetto, a solução de instrumentação e rastreamento de desempenho de última geração para Android.
Uma técnica comum ao tentar depurar problemas de memória é entender quais processos alocam ou liberam espaço de armazenamento. Ao ler este artigo, você verá como usar o Native Memory Profiler para rastrear um vazamento, usando o Teste de estresse de emulação de GPU como um exemplo de projeto.
Para acompanhar o processo, faça a clonagem ou o download da amostra em https://github.com/google/gpu-emulation-stress-test.
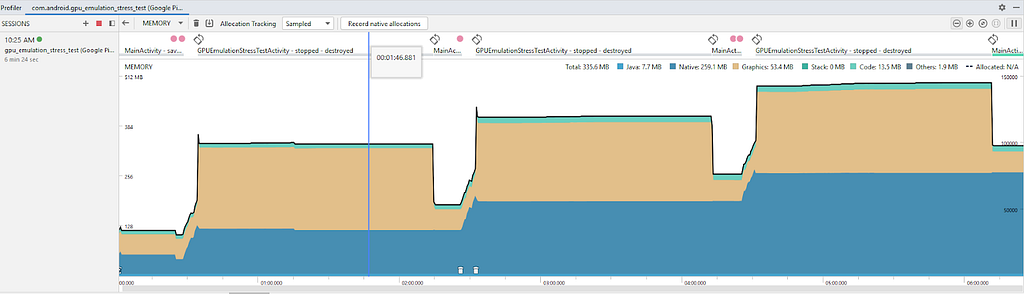
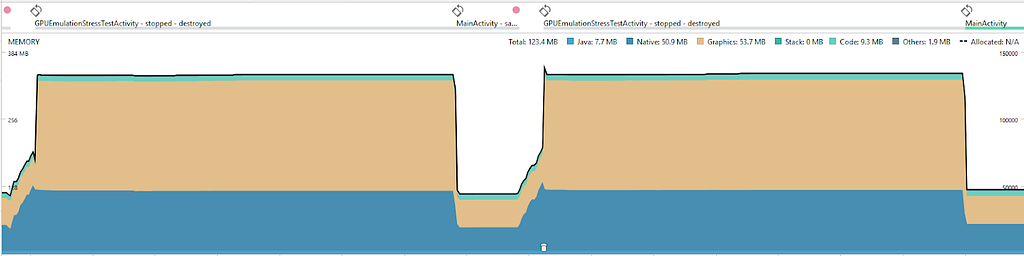
Em geral, quando há suspeita de vazamento de memória, é uma boa ideia começar em um nível superior e observar os padrões na memória do sistema. Para fazer isso, clique no botão de perfil no Android Studio e digite o perfil de memória para ver informações mais detalhadas sobre o rastreamento de memória.
Depois de realizar a simulação algumas vezes, podemos ver alguns padrões interessantes.
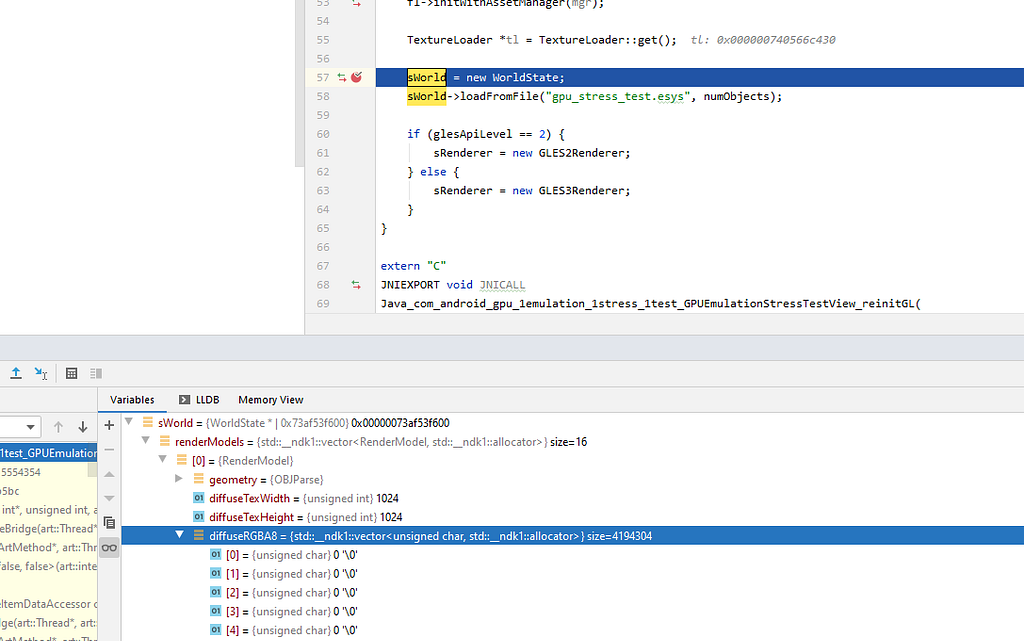
A partir do Android Studio 4.1 Canary 6, podemos capturar uma gravação de alocações de memória nativa para analisar por que a memória não está sendo liberada. Para fazer isso com o aplicativo de emulação de GPU, interrompi o funcionamento do aplicativo em execução e comecei a criar um perfil de uma nova instância. Iniciar o processo em um estado limpo, principalmente quando há uma base de código desconhecida, pode ajudar a definir melhor o foco do trabalho. No criador de perfil de memória, capturei uma gravação de alocação nativa durante toda a demonstração da emulação de GPU. Para fazer isso, reinicie o aplicativo selecionando Executar-> Perfil “aplicativo”. Depois que o aplicativo for iniciado e a janela de perfil for aberta, clique no perfil de memória e selecione "gravar alocação nativa”
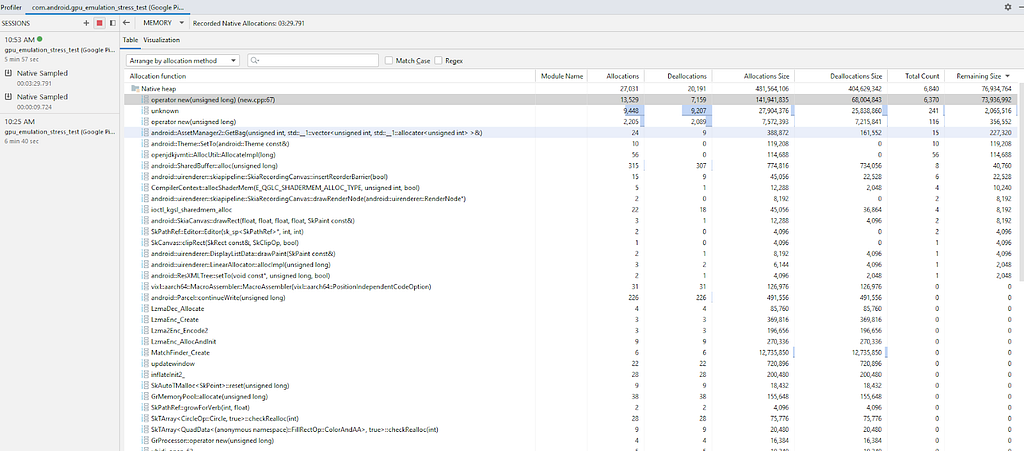
A visualização da tabela é útil para jogos/aplicativos que usam bibliotecas implementando os próprios alocadores, com o destaque de chamadas de malloc feitas fora das novas.
Quando uma gravação é carregada, os dados são apresentados pela primeira vez em uma tabela. A tabela mostra as funções folha chamando malloc. Além do nome da função, a tabela mostra o módulo, a contagem, o tamanho e o delta. Essas informações são amostradas para que seja possível capturar somente algumas chamadas malloc/liberadas. Isso depende em grande parte da taxa de amostragem, que será discutida mais adiante.
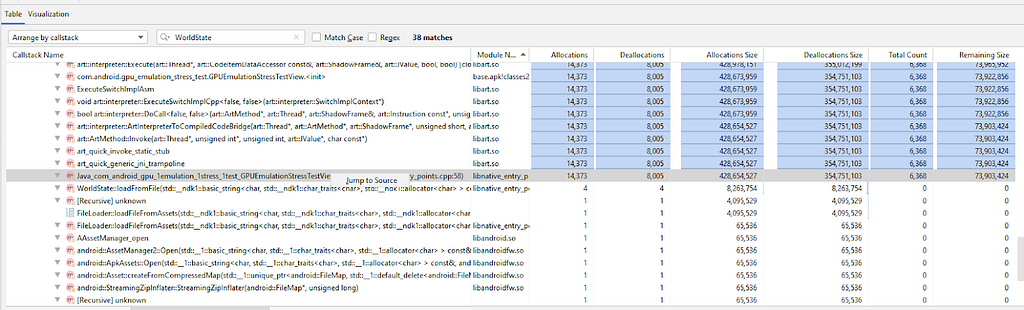
Também é útil saber de onde essas funções que alocam memória estão sendo chamadas. Existem duas maneiras de visualizar essas informações. A primeira é alterando o menu suspenso "Organizar por método de alocação" para "Organizar por pilha de chamadas". A tabela mostra uma árvore de pilhas de chamadas, semelhante ao esperado em uma gravação de CPU. Se o projeto atual tiver símbolos, o que é comum em versões depuráveis, eles serão escolhidos e usados automaticamente. Caso você esteja criando um APK externo, consulte este guia. Isso permite que você clique com o botão direito do mouse em uma função e escolha “Ir para a fonte”.
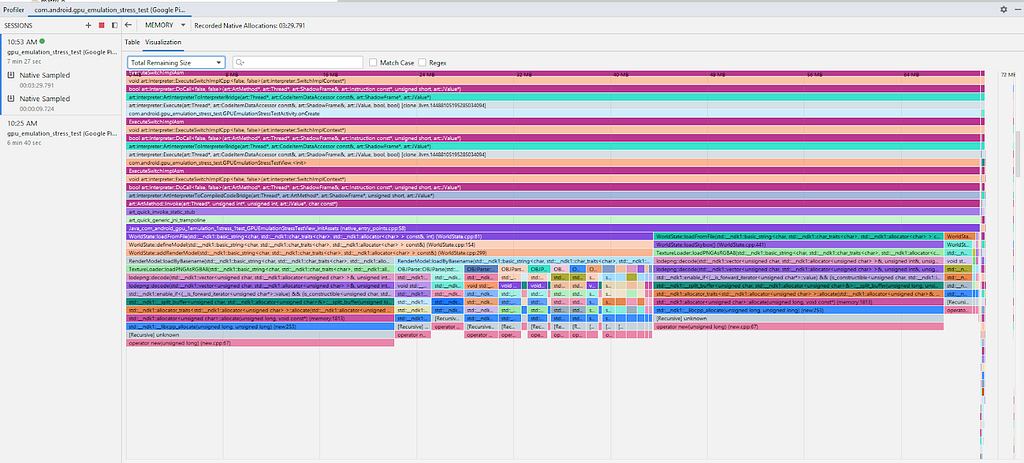
Também adicionamos uma nova visualização do diagrama de chamas para os criadores de perfis de memória, permitindo que você veja rapidamente quais pilhas de chamadas alocam mais memória. Isso é útil em especial quando há uma pilha de chamadas muito profunda.
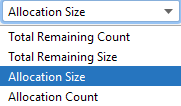
Há quatro maneiras de classificar esses dados ao longo do eixo X:
A partir daqui, podemos clicar com o botão direito do mouse nas pilhas de chamadas e selecionar "Ir para a fonte" para acessar a linha de código responsável pela alocação. No entanto, ao analisar a visualização com atenção, notamos que o pai comum, WorldState, é responsável por vários vazamentos. Para validar isso, você pode filtrar os resultados.
Assim como na visualização da tabela, o gráfico pode ser filtrado usando a barra de filtros. Ao usar um filtro, os dados no gráfico são atualizados de maneira automática para mostrar somente as pilhas de chamadas com funções que correspondem à palavra/regex pesquisada.
Às vezes, as pilhas de chamadas ficam muito longas ou simplesmente não há espaço suficiente para exibir o nome da função na tela. Para ajudar nesse processo, use a tecla CTRL + a roda do mouse para aumentar/diminuir o zoom ou clique no gráfico e use os comandos W, A, S, D para navegar.
Adicionar um ponto de interrupção e realizar a emulação rapidamente duas vezes revela que, na segunda execução, provocamos o vazamento substituindo o ponteiro da primeira execução.
Para fazer uma correção rápida da amostra, podemos excluir “world” após a marcação de conclusão, criando novamente um perfil do aplicativo para validar a alteração.
Terminamos no ponto em que começamos ao analisar as estatísticas de memória de nível superior. A validação dessa exclusão de “sWorld” no final da simulação libera os 70 MB mantidos na primeira execução.
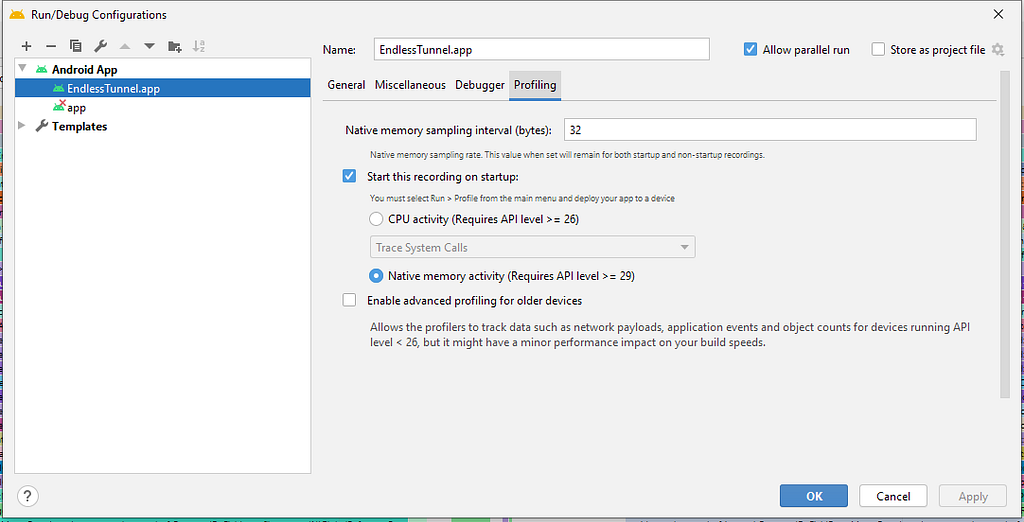
A amostra acima mostra como o rastreamento de memória nativa pode ser usado para encontrar e corrigir vazamentos de memória. Outro uso comum do rastreamento de memória nativa é entender em que processos a memória é usada durante a inicialização do aplicativo. No Android Studio 4.1, também adicionamos a capacidade de capturar gravações de memória nativa desde a inicialização do aplicativo. Você pode acessar o recurso na caixa de diálogo "Configurações de execução/depuração" da guia "Criação de perfil".
Você pode personalizar o intervalo de amostragem ou gravar memória na inicialização, usando a caixa de diálogo “Configuração de execução”.
Aqui você também pode alterar a taxa de amostragem para novas capturas. Usar uma taxa de amostragem menor pode gerar um grande impacto no desempenho geral, já que escolher uma opção maior talvez resulte na perda de algumas alocações. Diferentes taxas de amostragem funcionam para tipos distintos de problemas de memória.
Com o novo criador de perfis de memória nativa, ficou mais fácil encontrar vazamentos e entender em que processos a memória é mantida. Experimente o criador de perfis de memória nativa no Android Studio 4.1 e compartilhe seu feedback sobre nosso rastreador de bugs. Para ver mais dicas e orientações, confira também nossa palestra realizada no início deste ano no Google for Games Summit sobre práticas recomendadas e ferramentas de memória do Android.
Postado por Alex Musil, diretor de gerenciamento de produtos do Google Play
Esta postagem do blog faz parte de uma série semanal que usa a hashtag #11WeeksOfAndroid. A cada semana, exploramos uma área importante do Android para que você não perca nenhum detalhe. Nesta semana, destacamos o tópico distribuição e monetização de apps no Google Play. Veja abaixo algumas informações úteis que separamos para você.
Agradecemos sua participação nestes dias das 11 semanas de Android, em que nos concentramos nos processos de distribuição e monetização de apps. Com os desenvolvimentos que anunciamos, você pode aproveitar as incríveis melhorias na plataforma Android, que foram destacadas por nós desde a semana 1.
O Google Play faz uma parceria com desenvolvedores para oferecer experiências digitais incríveis a bilhões de usuários do Android. Desde o começo, nos comprometemos em fornecer as ferramentas e os insights necessários para você alcançar mais usuários e expandir sua empresa. Nesta semana, lançamos novos recursos e melhoramos os existentes. Tudo isso para ajudar você a continuar maximizando seu sucesso.
Agradecemos a todos que já compartilharam feedback sobre a versão Beta do novo Google Play Console, lançada há alguns meses em play.google.com/console. Enquanto seguimos atualizando a versão Beta, fizemos vários lançamentos importantes:
No início desta semana, organizamos três webinars para deixar você a par das novidades e das mudanças em relação à versão clássica do Play Console. Se tiver perdido as sessões ao vivo, assista aos vídeos sob demanda abaixo.
Caso você seja um iniciante, ouça o engenheiro-chefe do Google Play Console, Dan White, para conhecer os novos recursos, como o Inbox, a política de status, o conteúdo do app e as funcionalidades aprimoradas de gerenciamento de equipe.
Para fazer um lançamento com confiança, confira este webinar com o designer de UX do Google Play, Matt McGriskin, que explica os novos fluxos de trabalho de teste e publicação.
Por fim, se você quiser expandir seu público, veja o que o engenheiro do Google Play, Ryan Fanelli, tem a dizer e conheça práticas recomendadas de otimização para app store e uma visão geral sobre os relatórios de novas aquisições.
Você também pode participar do nosso curso sobre o Play Console na Play Academy. E, se ainda não tiver feito isso, use a Verificação em duas etapas para fazer login no Google Play Console, o que será uma exigência ainda neste ano.
Ficamos felizes em ver tantas pessoas usando o Android App Bundle para lançar apps e jogos. Por meio de melhorias recentes, seguimos tornando os pacotes de apps a melhor opção de formato de publicação disponível.
Se você ainda não migrou para o pacote de apps, publicamos algumas Perguntas frequentes sobre a assinatura de apps do Google Play — necessária para pacotes de apps —, além de orientações sobre como testar seu pacote de apps. Confira nossa postagem do blog para saber mais sobre as melhorias recentes nos processos de desenvolvimento, teste e publicação com pacotes de apps.
Conforme anunciamos no lançamento da versão Beta do Android 11, exigiremos que os novos apps sejam publicados usando o formato de Android App Bundle no Google Play na segunda metade de 2021. Isso significa que também suspenderemos o uso dos arquivos de expansão de APK (OBBs) e tornaremos o Play Asset Delivery a opção padrão para a publicação de jogos com mais 150 MB.
As classificações e as avaliações são um ponto de contato importante com os usuários. Por isso, muitos de vocês solicitaram que os usuários pudessem deixar uma avaliação diretamente no app. Tornamos isso possível com a In-App Review API. Escolha quando solicitar uma avaliação aos usuários e receba feedback no momento certo. A In-App Review API está disponível na Play Core Library.
Também lançamos uma amostra unificada de APIs da Play Core, que inclui avaliações e atualizações no app, além de instalações de módulos de recursos sob demanda. Aprenda a usar essas APIs com nosso artefato de extensões Kotlin da Play Core Library, que facilita o trabalho dos desenvolvedores que usam essa linguagem.
Fizemos muitas atualizações no Google Play Commerce com o objetivo de desenvolver a confiança do usuário por meio de experiências de pagamento mais claras e fáceis. As políticas de confiança do usuário anunciadas em abril oferecem mais transparência, experiências de avaliação mais seguras e processos de cancelamento simplificados.
Lançamos também a Play Billing Library 3, que oferece suporte a pagamentos à vista, uma melhor experiência de resgate de código promocional para assinatura, atribuição de compra e muito mais. A Play Billing Library 3 será obrigatória para todos os novos apps a partir de 2 de agosto de 2021.
Para mais informações, confira esta sessão com Mrinalini Loew, gerente de projetos em equipe no Google Play Commerce.
Além disso, demos início a uma série de seis artigos no Google Play Faturamento que você pode acompanhar aqui no Medium.
O Google Play Pass permite que os desenvolvedores gerem uma receita adicional e conectem-se com públicos não explorados ao oferecer experiências sem anúncios e compras no aplicativo. Desde o lançamento em setembro do ano passado, o Google Play Pass adicionou mais de 200 títulos ao catálogo, de quebra-cabeças e jogos de corrida até apps de serviços e adequados para crianças. Além disso, nesta semana estamos empolgados para comemorar a estreia mundial de Super Glitch Dash e Element como os títulos mais recentes dos "Lançamentos no Google Play Pass".
O catálogo expandido oferece experiências do usuário mais completas e um fluxo de receita sustentável para desenvolvedores que utilizam um modelo inovador de pagamento. Além disso, os títulos do Google Play Pass geram uma receita 2,5 vezes maior em comparação com os lucros exclusivos da Play Store nos Estados Unidos.
No mês passado, disponibilizamos o Google Play Pass em nove novos mercados e oferecemos aos usuários a opção de começar com uma assinatura anual ou com o plano mensal existente. Hoje, anunciamos que os desenvolvedores com assinaturas no app podem indicar os próprios títulos para fazer parte do Google Play Pass. Se você estiver criando uma experiência incrível para os usuários do Google Play, saiba mais e demonstre interesse em participar do programa.
Se você procura uma maneira fácil de conhecer os destaques desta semana, confira o guia sobre distribuição e monetização de apps. Teste seu conhecimento sobre os principais pontos para receber um selo virtual com edição limitada.
Agradecemos sua participação nessas 11 semanas de Android! Esperamos que esses recursos e anúncios recentes sejam úteis e potencializem seu sucesso no Google Play.
Acesse toda a playlist do conteúdo de vídeo usando #11WeeksOfAndroid e saiba mais sobre as publicações de cada semana. Continuaremos a destacar novas áreas a cada semana. Então, fique por dentro e nos siga no Twitter e no YouTube. Agradecemos por você compartilhar essa experiência conosco.
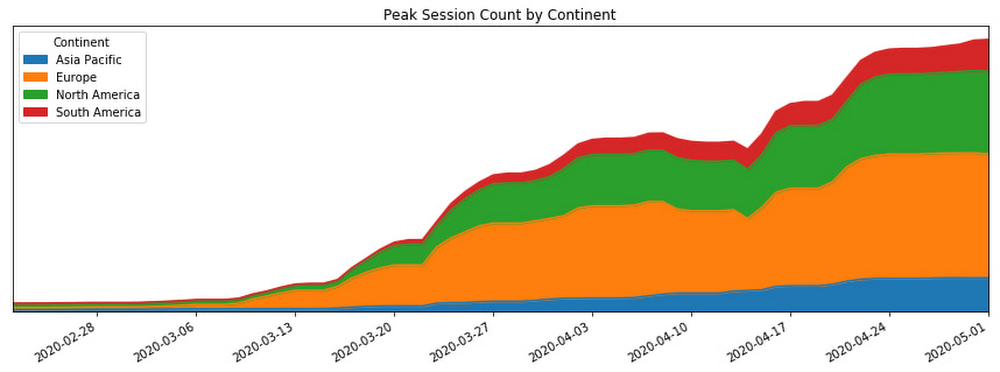
A pandemia de COVID-19 impôs o distanciamento físico no mundo todo, fazendo com que muitas pessoas recorressem a videoconferências on-line para manter o contato social, educacional e profissional. Conforme mostrado no gráfico abaixo, essa mudança gerou um grande aumento no número de novos usuários do Google Meet.
Nesta postagem, explicarei como garantimos que a capacidade de serviço disponível do Meet antecedesse o uso 30 vezes maior durante a pandemia de COVID-19. Além disso, contarei o que fizemos para tornar esse crescimento sustentável, em termos técnicos e operacionais, aproveitando as diversas práticas recomendadas de engenharia de confiabilidade de sites (SRE, na sigla em inglês).
Aos poucos, o mundo se tornou mais consciente da pandemia de COVID-19, e as pessoas começaram a adaptar as rotinas diárias. O impacto crescente do vírus sobre os hábitos de trabalho, estudos e socialização com amigos e familiares gerou um aumento na procura por serviços de contato virtual, como o Google Meet. Em 17 de fevereiro, a equipe de SRE do Meet começou a receber páginas relacionadas a questões de capacidade regional.
As páginas eram sintomáticas ou alertas de caixa-preta, como "Falhas de muitas tarefas" e “Transferência de carga excessiva". Como os serviços do Google são desenvolvidos com redundância, esses alertas não indicavam problemas em andamento visíveis aos usuários. No entanto, logo ficou claro que o uso do produto na Ásia apresentava uma tendência acentuada de aumento.
Os especialistas em SRE começaram a trabalhar com a equipe de planejamento de capacidade para encontrar recursos adicionais que pudessem ajudar no gerenciamento desse aumento de acesso, mas ficou claro que precisávamos começar um planejamento com antecedência, caso a epidemia se espalhasse para outras regiões.
Como era de se esperar, assim que a Itália iniciou o período de lockdown contra a COVID-19, o uso do Meet começou a aumentar no país.
Nesse ponto, começamos a elaborar nossa resposta. Como de costume, a equipe de SRE começou declarando um incidente, e demos início a nossa resposta relacionada ao risco de capacidade global.
Porém, é importante destacar que, embora tenhamos abordado esse desafio usando nossa estrutura de gerenciamento de incidentes testada e comprovada, naquele ponto não estávamos próximos nem prestes a ter uma interrupção do serviço. Não houve um impacto na experiência do usuário. A maioria dos efeitos sociais da pandemia de COVID-19 eram desconhecidos ou muito difíceis de prever. Nossa missão era abstrata: precisávamos evitar interrupções no que havia se tornado um produto essencial para um grande número de novos usuários, enquanto escalonávamos o sistema, sem saber o quanto ele cresceria e quando se estabilizaria.
Além disso, toda a equipe (junto com o restante do Google) estava em processo de transição para um período indefinido de trabalho remoto devido à pandemia de COVID-19. Embora a maioria dos nossos fluxos de trabalho e das ferramentas já estivesse acessível fora dos nossos escritórios, havia outros desafios associados à execução virtual de um incidente de longa data.
Como não podíamos sentar juntos para conversar, percebemos que era importante gerenciar os canais de comunicação de maneira proativa, garantindo que todos tivéssemos acesso às informações necessárias para atingir nossos objetivos. Muitos de nós também enfrentaram desafios adicionais não relacionados ao trabalho, como cuidar de amigos e familiares durante a adaptação à nova realidade. Embora esses fatores tenham criado obstáculos extras para nossa resposta, estratégias como atribuir e eleger substitutos, além de gerenciar proativamente propriedades e canais de comunicação, nos ajudaram a superar as dificuldades.
Mesmo assim, seguimos usando nossa abordagem de gerenciamento de incidentes. Começamos nossa resposta global definindo um Comandante de Incidentes, um Líder de Comunicações e um Líder de Operações, tanto na América do Norte quanto na Europa, para que tivéssemos cobertura 24 horas por dia.
Como um dos Comandantes de Incidentes Gerais, minha função era semelhante à de um roteador de informações com estado, ainda que com opiniões, influência e poder de tomada de decisão. Coletei informações de status sobre quais problemas táticos persistiam, quais ações estavam sendo executadas e por quem e identifiquei os contextos que afetavam nossa resposta (por exemplo, as respostas dos governos à pandemia de COVID-19). Depois disso, enviei o trabalho para as pessoas que poderiam ajudar. Detectei e explorei as áreas de incerteza, tanto para a definição de problemas, por exemplo, “Pode ser um problema executar o serviço com 50% de utilização da CPU na América do Sul?”, quanto para as possíveis soluções, "Como vamos acelerar nosso processo de ativação?”. Assim, pude coordenar nosso esforço de resposta geral e garantir que todas as tarefas necessárias fossem encaminhadas às pessoas certas.
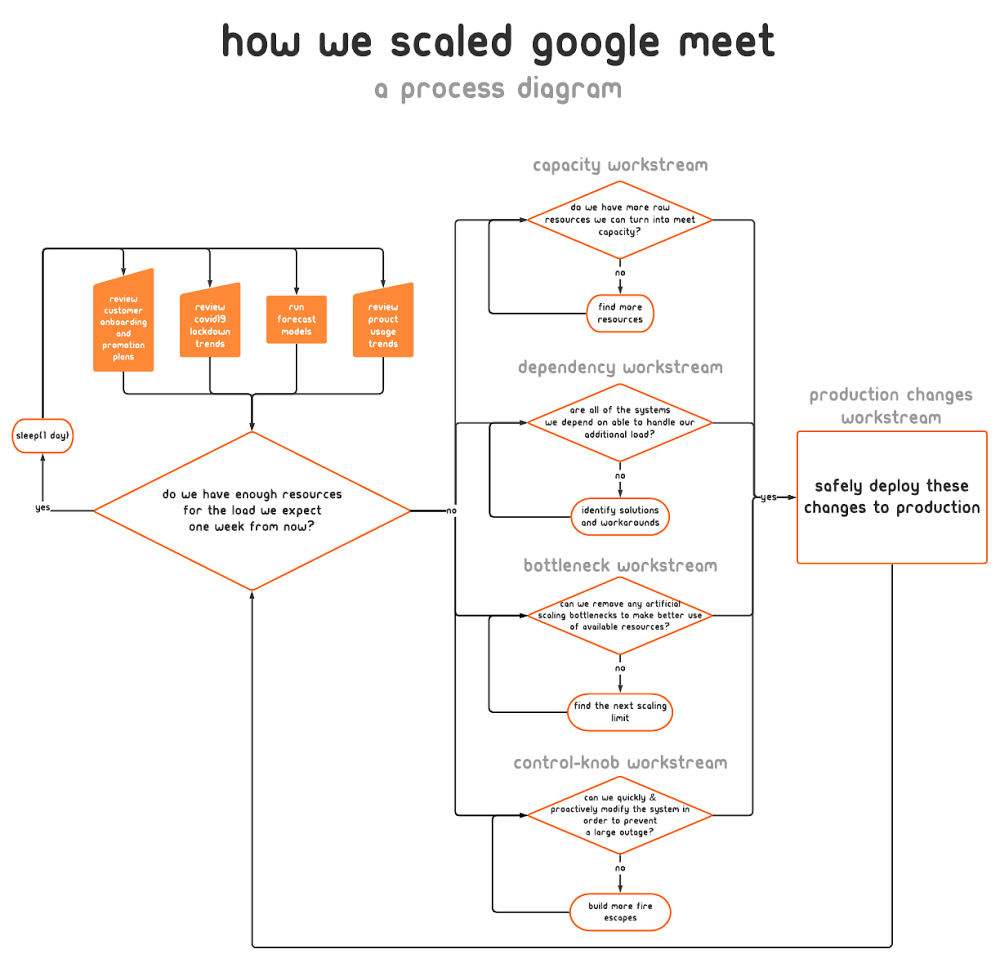
Não demorou muito para percebemos que o escopo da nossa missão era enorme e que a natureza da nossa resposta seria de longa duração. Para manter um escopo gerenciável para cada colaborador, dividimos nossa resposta em uma série de fluxos de trabalho semi-independentes. Nos casos em que os escopos se sobrepunham, a interface entre os fluxos de trabalho era novamente definida.
Montamos os seguintes fluxos de trabalho, visíveis no diagrama acima:
Para responder ao incidente, reavaliamos continuamente a adequação da nossa estrutura operacional atual. O objetivo era ter a estrutura necessária para operar de modo eficiente, mas nada além disso. Quando as pessoas têm uma estrutura muito reduzida, elas tomam decisões sem ter as informações corretas. Porém, com estrutura demais, elas passam todo o tempo planejando reuniões.
Esse projeto era uma maratona, e não uma corrida de velocidade. Durante todo o tempo, verificávamos regularmente se alguém precisava de ajuda ou necessitava fazer uma pausa. Isso foi essencial para prevenir o esgotamento durante um incidente tão longo.
Para ajudar a prevenir a exaustão, cada pessoa em uma função de resposta ao incidente designou outro colega como "substituto". O substituto comparecia às mesmas reuniões que o responsável principal, assim como tinha acesso a todos os documentos relevantes, listas de e-mails e salas de bate-papo. Além disso, esse colega fazia perguntas para estar totalmente informado caso tivesse que assumir o controle principal sem muito aviso prévio. Essa abordagem se tornou útil quando algumas das pessoas encarregadas ficava doente ou precisava de uma pausa, já que o substituto tinha as informações de que precisava para trabalhar com rapidez e eficácia.
A equipe de resposta tentava descobrir a melhor forma de coordenar o fluxo de informações e fazer o trabalho necessário para resolver o incidente, mas a maioria das pessoas envolvidas estava, na verdade, lidando com o risco na produção.
Nosso principal requisito técnico era manter a quantidade de capacidade de serviço do Meet disponível regionalmente antes que houvesse a demanda do usuário. Com os mais de 20 data centers do Google operando em todo o mundo, tínhamos uma infraestrutura robusta para aproveitar. Rapidamente, usamos os recursos brutos existentes, o que foi suficiente para quase dobrar a capacidade de serviço disponível do Meet.
Anteriormente, contávamos com tendências históricas para estabelecer a quantidade de capacidade adicional que precisaríamos provisionar. Porém, como não podíamos mais depender da extrapolação de dados históricos, foi preciso começar a provisionar a capacidade com base em previsões preditivas. Com o objetivo de traduzir essas estruturas para que nossa equipe de mudanças pudesse agir na produção, o fluxo de trabalho de capacidade precisava usar o modelo de uso para definir a quantidade de CPU e RAM adicionais que seriam necessárias. Mais tarde, a criação desse modelo de tradução nos permitiu acelerar o processo de aumento da capacidade disponível na produção, ao ensinar como nossas ferramentas e recursos de automação deveriam interpretá-lo.
Logo ficou claro que apenas dobrar o tamanho da nossa capacidade não seria o suficiente, por isso, começamos a trabalhar com uma previsão de crescimento de 50 vezes, o que antes era impensável.
Além de escalonar nossa capacidade, também trabalhamos na identificação e remoção de ineficiências da nossa pilha de serviços. Para isso, agrupamos grande parte desse trabalho em algumas categorias: ajuste de sinalizadores binários, alocações de recursos e reescrita do código para uma execução mais barata.
Tornar nossas instâncias de servidor mais eficientes em termos de recursos foi um esforço multidimensional. Essa meta pode ser resumida como "a maioria das solicitações gerenciadas com o menor custo de recursos, sem sacrificar a experiência do usuário ou a confiabilidade do sistema".
Estas foram algumas das perguntas que fizemos durante esse processo de investigação:
Podemos executar menos servidores com maiores reservas de recursos para reduzir a sobrecarga computacional?
Estamos reservando mais RAM ou CPU do que precisamos? Podemos usar melhor esses recursos para outras tarefas?
Temos largura de banda de saída suficiente na extremidade da nossa rede para disponibilizar streams de vídeo em todas as regiões?
Podemos reduzir a quantidade de memória e CPU necessária para uma determinada instância do servidor com subconjuntos dos servidores de back-end em uso?
Embora nossos novos formatos e configurações de servidor fossem qualificados, neste ponto, valeu a pena reavaliar a estrutura. Com o crescimento do acesso ao Meet, as características de uso também mudaram, como a duração de uma reunião, o número de participantes da sessão e as formas de compartilhar o tempo de áudio.
Como o serviço Meet exigia cada vez mais recursos brutos, começamos a notar que uma porcentagem significativa dos nossos ciclos de CPU era gasta em sobrecarga de processos, como manter as conexões para monitorar sistemas e os balanceadores de carga ativos, em vez de lidar com solicitações.
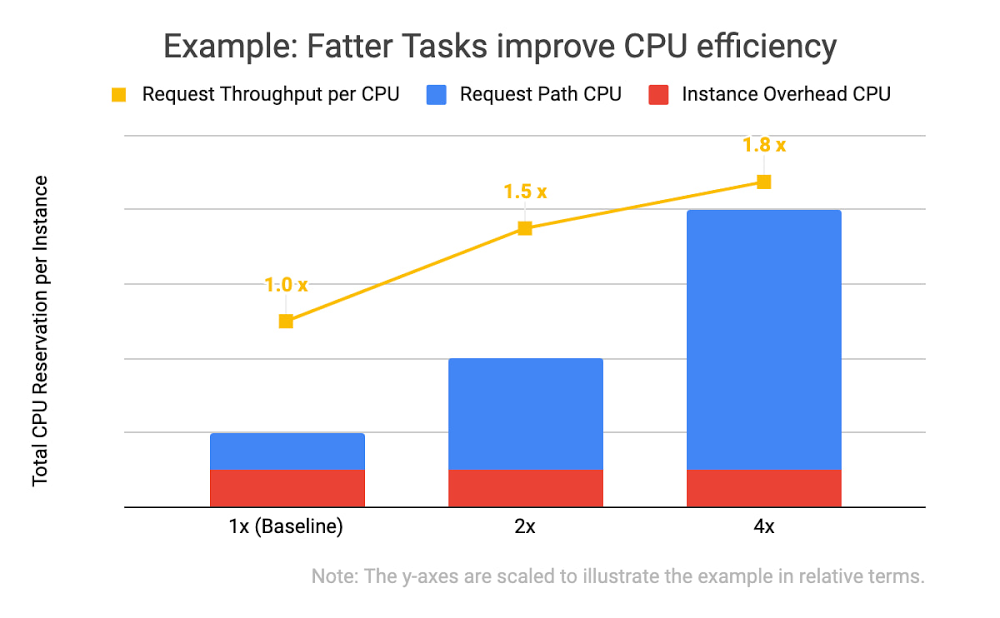
Para aumentar a taxa de capacidade ou o "número de solicitações processadas por CPU a cada segundo", aumentamos a especificação de recursos dos nossos processos em termos de reserva de CPU e RAM. Isso pode ser chamado de execução de tarefas “mais pesadas”.
Nos dados de exemplo acima, você perceberá dois pontos importantes: que todas as três especificações de instância têm a mesma sobrecarga computacional (em vermelho) e que, quanto maior a reserva geral de CPU de uma instância, maior será a capacidade de solicitação (em amarelo) Usando a mesma quantidade total de CPU alocada, uma instância com a forma de 4x pode gerenciar 1,8 vezes mais solicitações do que as quatro instâncias com a forma da linha de base. Isso ocorre porque a sobrecarga computacional (como gerenciar entradas de registro de depuração persistentes, verificar se os canais de conexão de rede ainda estão ativos e inicializar classes) não é escalonada linearmente com o número de solicitações recebidas e gerenciadas pela tarefa.
Continuamos tentando dobrar as reservas das nossas tarefas de serviço, enquanto cortamos pela metade o número de tarefas na nossa frota, até atingirmos uma limitação de escalonamento.
É claro que precisávamos testar e qualificar cada uma dessas mudanças. Para isso, usamos ambientes canários a fim de garantir que essas mudanças se comportassem conforme o esperado e não apresentassem nem atingissem quaisquer limitações não descobertas anteriormente. Assim como fazemos com as novas versões dos nossos servidores, atestamos a qualificação, identificando que não houve qualquer regressão funcional ou de desempenho e que os efeitos desejados das mudanças foram de fato realizados na produção.
Também fizemos melhorias funcionais na nossa base de código. Por exemplo, reescrevemos um cache distribuído na memória para flexibilizar o processo de divisão das entradas nas instâncias de tarefa. Isso nos permitiu armazenar mais entradas em uma única região quando aumentamos o número de instâncias de servidor em um cluster.
Embora nossa confiança nas previsões de crescimento de uso estivesse melhorando, sabíamos que elas ainda não eram 100% precisas. O que aconteceria se ficássemos sem capacidade de atendimento em uma região? O que aconteceria se saturássemos um link de rede específico? O objetivo do fluxo de trabalho do botão de controle era fornecer respostas satisfatórias, se não ideais, para esse tipo de pergunta. Precisávamos de um plano aceitável para qualquer imprevisto que afetasse nossos consoles.
Um grupo começou a trabalhar para identificar e desenvolver mais controles de produção e planos de emergência, tudo o que esperávamos não precisar colocar em prática. Como exemplo, esses botões nos permitiriam fazer o downgrade rapidamente da resolução de vídeo padrão de alta definição para definição padrão quando alguém participasse de uma conferência do Meet. Essa mudança nos daria algum tempo para fazer correções usando os outros fluxos de trabalho (melhorias de provisionamento e eficiência) sem degradação substancial do produto. Dessa forma, os usuários ainda poderiam atualizar a qualidade do vídeo para alta definição se quisessem.
Ter uma variedade de controles instrumentados, testados e prontos para uso nos garantiu mais tempo para solucionar problemas, caso as previsões dos piores cenários possíveis não fossem precisas, além de nos dar um pouco de paz de espírito.
Essa resposta estruturada envolveu um grande número de Googlers em várias funções. Isso significava que, para continuar avançando na resolução do incidente, também precisávamos de coordenação séria e comunicações intencionais.
Realizamos reuniões diárias entre nossos dois fusos horários para nos conectar com Googlers em Zurique, Estocolmo, Kirkland (Washington) e Sunnyvale (Califórnia). Nossos líderes de comunicações forneciam atualizações regulares para várias partes interessadas, incluindo a equipe de produto, executivos e as equipes de infraestrutura e operações de suporte ao cliente para que cada setor tivesse informações de status atualizadas ao tomarem as próprias decisões. Os líderes do fluxo de trabalho usaram o Documentos Google para manter os arquivos de status compartilhados sempre atualizados com conjuntos de riscos, pontos de contato, esforços contínuos de mitigação e notas de reuniões mais recentes.
Essa abordagem funcionou muito bem para fazer as coisas andarem, mas logo começou a parecer um fardo. Precisávamos estender nosso ciclo de planejamento de dias para semanas, a fim de reduzir significativamente a quantidade de tempo gasto na coordenação e aumentar o tempo investido na mitigação do nosso problema.
Nossa primeira tática foi criar modelos de previsão melhores e mais confiáveis. Essa maior previsibilidade nos permitiria estabilizar a meta de aumento na capacidade de atendimento para toda a semana, em vez de focar somente no dia seguinte.
Também trabalhamos para reduzir a quantidade de trabalho necessária para aumentar a capacidade adicional de serviço. Nossos processos, assim como os sistemas em operação, precisavam ser automatizados.
Nesse ponto, escalonar a pilha de serviços do Meet era nossa operação mais trabalhosa, já que isso significava manter diversas pessoas atualizadas sobre as previsões mais recentes, além de gerenciar diferentes recursos e ferramentas (às vezes instáveis) envolvidos em certas operações.
Conforme descrito no diagrama do ciclo de vida acima, a resposta para automatizar essas tarefas foi fazer melhorias incrementais. Primeiro, documentamos as tarefas e depois começamos a automatizar partes delas até que, finalmente, no cenário ideal, o software pudesse concluir a tarefa do início ao fim sem intervenção manual.
Para conseguir isso, tivemos a ajuda de vários especialistas em automação de dentro e de fora da organização do Meet para gerenciar o problema. Confira alguns dos itens incluídos no trabalho:
Tornar nossos serviços de produção mais responsivos a alterações em um arquivo de configuração autorizado e registrado
Aumentar as ferramentas comuns para oferecer suporte a alguns dos requisitos de sistema exclusivos do Meet (por exemplo, maior largura de banda e rede de menor latência)
Ajustar verificações de regressão que se tornaram mais instáveis com o crescimento do sistema em escala
Com a automatização e a codificação dessas tarefas, vimos uma redução significativa nas operações manuais necessárias para ativar o Meet em um novo cluster ou implantar uma nova versão binária para liberar melhorias de desempenho. Ao final desse incidente de escalonamento, fomos capazes de automatizar totalmente nossa área de cobertura de capacidade do job por zona e por serviço, o que impediu centenas de invocações de ferramentas de linha de comando realizadas manualmente. Isso liberou tempo e energia para que nossos engenheiros trabalhassem em alguns dos problemas mais difíceis (mas igualmente importantes).
Nesse ponto do escalonamento das nossas operações, podíamos usar transferências "off-line" entre sites via e-mail, reduzindo ainda mais o número de reuniões a serem atendidas. Com uma estratégia sólida e um caminho estruturado, decidimos passar para um modo de execução mais tático.
Logo depois, diminuímos nossa estrutura relacionada ao incidente e começamos a operar o trabalho restante como faríamos com qualquer projeto de longo prazo.
No momento em que encerramos nosso incidente, o Meet tinha mais de 100 milhões de participantes de reuniões por dia. Alcançar esse resultado sem problemas não foi simples nem fácil: os cenários que a equipe do Meet explorou durante os testes de resposta a desastres e incidentes antes da pandemia de COVID-19 não abrangiam a extensão nem a escala dos requisitos de aumento de capacidade que encontramos. Como consequência, tivemos que formular nossa resposta rapidamente.
Houve muitos imprevistos ao longo do caminho, já que era necessário equilibrar os riscos de uma maneira diferente da que normalmente fazemos durante as operações padrão. Como exemplo, implantamos um novo código de servidor para produção com menos tempo de preparação da versão canário, pois teríamos que fazer as correções de desempenho antes de ficarmos sem capacidade regional disponível.
Uma das habilidades mais importantes que aprimoramos ao longo desse esforço de dois meses foi a capacidade de catalogar, quantificar e qualificar riscos e recompensas de uma forma flexível. Todos os dias, tínhamos acesso a novas informações sobre os lockdowns provocados pela pandemia de COVID-19, os planos de novos clientes para começar a usar o Meet e a capacidade de produção disponível. Às vezes, essas novas informações tornavam obsoleto o trabalho que tínhamos iniciado no dia anterior.
O tempo era essencial. Por isso, não podíamos tratar cada item de trabalho com a mesma prioridade ou urgência, mas também não podíamos deixar de proteger nossos próprios modelos de previsão. Esperar por informações perfeitas não era uma opção em nenhum momento. Então, o melhor que podíamos fazer era estruturar nosso caminho o máximo possível, enquanto tomávamos decisões rápidas, mas calculadas, com os dados que tínhamos.
Todo esse trabalho só foi possível porque contamos com a participação de pessoas experientes, colaborativas e versáteis em diversas equipes e funções — SREs, desenvolvedores, gerentes de produto, gerentes de programa, engenheiros de rede e suporte ao cliente —, que trabalharam juntas para tornar o projeto realidade.
Acabamos o processo preparados para o que seria nossa próxima missão: disponibilizar o Meet gratuitamente para todos com uma conta do Google. Normalmente, abrir o produto para os consumidores teria sido um evento dramático de escalonamento por si só, mas depois do intenso trabalho que já havíamos feito, estávamos prontos para o próximo desafio.
Postado por Dom Elliott e Yafit Becher, gerentes de produtos do Google Play
Em pouco mais de dois anos, o Android App Bundle se tornou o padrão ouro para publicação no Google Play. Atualmente, mais de 600 mil aplicativos e jogos usam o pacote de aplicativos na faixa de produção, representando mais de 40% de todos os lançamentos no Google Play. Os pacotes de aplicativos são usados por 50% dos principais desenvolvedores do Google Play — como a Adobe, que usou o recurso para reduzir o tamanho do Adobe Acrobat Reader em 20%.
Recentemente, lançamos o Play Asset Delivery (PAD). Esse recurso oferece os grandes benefícios dos pacotes de aplicativos e permite que os desenvolvedores melhorem a experiência do usuário enquanto cortam os custos de entrega e reduzem o tamanho dos jogos. A Gameloft usou o PAD para melhorar a retenção de usuários e viu um aumento de 10% no número de novos jogadores em comparação ao seu sistema de entrega de recursos anterior.
Para quem estiver fazendo a migração, publicamos algumas Perguntas frequentes sobre a assinatura de aplicativos do Google Play — necessária para pacotes de aplicativos —, além de orientações sobre como testar seu pacote de aplicativos. Continue a leitura para saber mais sobre as melhorias recentes nos processos de desenvolvimento, teste e publicação com pacotes de aplicativos.
Entrega de recursos do Google Play
A opção de pacotes permite o desenvolvimento de aplicativos modulares usando módulos de recursos dinâmicos com diversas opções de entrega personalizáveis. Agora, você pode reduzir o tamanho dos recursos em módulos dinâmicos e de base quando estiver desenvolvendo aplicativos modulares. Essa funcionalidade é um pedido antigo dos desenvolvedores e pode resultar em uma redução significativa do tamanho dos seus aplicativos. Você pode encontrar o recurso na versão Canary do Android Studio 4.2, com esta sinalização experimental: android.experimental.enableNewResourceShrinker=true.
android.experimental.enableNewResourceShrinker=true
Agora, ao processar pacotes de aplicativos em APKs de distribuição, os módulos de tempo de instalação serão combinados automaticamente por padrão (a partir do bundletool 1.0.0). Isso significa que você pode separar seu aplicativo em módulos durante o desenvolvimento enquanto reduz o número de APKs distribuídos para cada dispositivo. O resultado é a aceleração dos processos de download e instalação do seu aplicativo. Se quiser evitar a fusão, defina uma “sinalização removível” para os módulos de tempo de instalação. Assim, será possível desinstalar um módulo no dispositivo após ele ter sido usado. É recomendável remover módulos grandes quando eles não forem mais necessários, já que reduzir o tamanho do seu aplicativo pode diminuir a probabilidade de desinstalação.
A dependência de recurso a recurso já está disponível em versão estável no Android Studio 4.0, permitindo que você especifique quando um módulo de recurso dinâmico depende de outro módulo de recurso. A capacidade de definir esse relacionamento garante que seu aplicativo tenha os módulos necessários para desbloquear funcionalidades adicionais, resultando em menos solicitações e uma modularização mais simples.
Sabemos que testar a entrega do seu aplicativo é fundamental para você avaliar a futura experiência dos seus usuários. Com o compartilhamento interno de aplicativos, você pode fazer upload de versões de teste para o Google Play e receber um link compartilhável para o download do seu aplicativo. Ao fazer o download usando este link, você terá acesso a um binário idêntico ao aplicativo disponibilizado para os usuários no lançamento do Google Play.
Play Asset Delivery
O Play Asset Delivery estende o formato do pacote de aplicativos, permitindo que você empacote até 2 GB de recursos de jogos junto com o binário em um único artefato publicado no Google Play. O PAD permite que jogos com mais de 150 MB substituam os arquivos de expansão legados (OBBs) e contem com o Google Play para manter os recursos atualizados, assim como você faz com o binário do jogo. O recurso também gerencia a compactação e a aplicação de patch delta, reduzindo o tamanho do download e fazendo com que o jogo seja atualizado mais rapidamente.
<id="imgCaption"> O conteúdo de um Android App Bundle com um módulo de base, dois módulos de recursos dinâmicos e dois pacotes de recursos.
É possível escolher um dos três modos de entrega, dependendo de quando você quer que os recursos sejam disponibilizados aos usuários. Escolha entre as opções install-time, em que os recursos aparecem como parte da instalação inicial do jogo, on-demand, em que eles só são entregues mediante solicitação, ou fast-follow, que aciona um download adicional imediatamente após a instalação do jogo ser concluída, mesmo que o usuário não abra o aplicativo. Com o fast-follow, você reduz o tempo até a primeira interação e disponibiliza os recursos aos usuários o mais rápido possível.
Nos próximos meses, lançaremos o direcionamento de formato de compactação de textura. Essa ferramenta permite que você inclua vários recursos de formato de compressão de textura e use nossa tecnologia para fornecer as funcionalidades no formato mais avançado compatível com o dispositivo solicitante.
Saiba mais nesta sessão do Game Developer Summit e leia a documentação para ver as opções de integração para Unity, Unreal Engine, Gradle, Native, além do suporte para Java.
Distribuição de excelência do Google Play
O Google Play oferece bilhões de aplicativos, jogos, atualizações e módulos de recursos dinâmicos todos os meses para usuários do Android em milhares de tipos de dispositivos ao redor do mundo. Investimos muito tempo e energia para garantir que seu conteúdo seja entregue da maneira mais perfeita e eficiente possível, evitando que processos complexos impactem a experiência do usuário.
Por exemplo, recentemente fizemos upgrade do serviço de download usado pelo Google Play. Por si só, essa mudança acelerou a instalação de pacotes de aplicativos em uma média de 6% e aumentou a conclusão global de instalações em 1%, resultando em milhões de novas instalações para desenvolvedores todas as semanas.
Também estamos lançando várias melhorias na distribuição de módulos de recursos dinâmicos. Isso inclui permitir a instalação quando seu aplicativo estiver em uma versão VISIBLE ou posterior, reduzir o limite gratuito que aciona erros de armazenamento insuficiente e remover a confirmação do usuário em recursos dinâmicos grandes via Wi-Fi. Essas alterações aumentaram em 12% o número de downloads de módulos adiados. Os aplicativos que usam recursos dinâmicos se beneficiarão dessas mudanças automaticamente.
Requisito para novos aplicativos no segundo semestre de 2021
Trabalhamos de maneira contínua para tornar os pacotes de aplicativos um formato de publicação melhor que os APKs no Google Play. Com o novo explorador, você pode gerenciar todos os seus pacotes de aplicativos em um só lugar. Você pode fazer o download e conferir os APKs de entrega exatos gerados pelo Google Play, bem como um APK universal assinado (um APK único instalável que inclui todo o código e recursos necessários para dispositivos compatíveis) que pode ser usado em outros canais de distribuição.
Estamos entusiasmados em ver o recurso de pacotes ser adotado pelo ecossistema de aplicativos e jogos e ansiosos para continuar aprimorando essa funcionalidade. Conforme anunciamos no evento do Android 11, para nos ajudar a investir em melhorias futuras, exigiremos que os novos aplicativos e jogos sejam publicados usando o formato de Android App Bundle no Google Play no segundo semestre de 2021. No mesmo período, suspenderemos o uso dos arquivos de expansão de APK (OBBs) legados, tornando o Play Asset Delivery a opção padrão para publicar jogos com mais de 150 MB. Também exigiremos que as experiências instantâneas sejam publicadas por meio de pacotes de aplicativos específicos, suspendendo o uso do formato ZIP legado.
Agradecemos aos que já migraram para o Android App Bundle e especialmente a todos aqueles que compartilharam feedback conosco. Esses comentários nos ajudam a moldar o futuro dos pacotes de aplicativos e a melhorar a tecnologia para todos. Por isso, continue compartilhando sua opinião.
Esta postagem do blog foi útil para você? Avalie!
★ ★ ★ ★ ★
Postado por Scott Lin, gerente de produtos do Google Play
Para muitos desenvolvedores, as classificações e as avaliações são um ponto de contato importante com os usuários. Todos os dias, milhões de avaliações são compartilhadas no Google Play, oferecendo insights valiosos aos desenvolvedores sobre o que os usuários gostam e o que precisa de melhorias. Os usuários também contam com a publicação de classificações e avaliações para decidir quais são os aplicativos e jogos mais adequados para eles.
Nos últimos dois anos, o Google Play lançou vários recursos para facilitar a postagem de comentários dos usuários e simplificar a interação e a resposta dos desenvolvedores. Por exemplo, os usuários agora podem fazer avaliações na página inicial do Google Play. Também lançamos a página "Reviews" em "My Apps & Games” para que os usuários possam postar e gerenciar avaliações em um só lugar.
No entanto, um dos recursos mais solicitados pelos desenvolvedores era permitir que os usuários fizessem avaliações diretamente no aplicativo, sem precisar voltar à página de detalhes do produto. Por isso, hoje, estamos felizes em anunciar o lançamento da nova In-App Review API para atender a essa necessidade.
A API permite que os desenvolvedores escolham quando solicitar comentários durante a experiência do usuário com o aplicativo. Para receber um feedback útil e completo, a melhor opção é deixar que os usuários naveguem o tempo suficiente pelo aplicativo antes de solicitar uma avaliação. No entanto, não interrompa os usuários no meio de uma tarefa nem em momentos em que eles precisem interagir com o aplicativo, já que o fluxo de avaliação controlará a ação na tela.
Os usuários agora podem compartilhar classificações e avaliações diretamente no seu aplicativo.
A In-App Review API oferece suporte a avaliações públicas e privadas para aplicativos na versão Beta.
A API faz parte da Play Core Library, que é distribuída para Java/Kotlin, C++ e Unity. Com esse recurso, você pode solicitar uma avaliação e iniciar o fluxo de feedback sem que os usuários saiam do aplicativo.
Conheça as quatro principais etapas de integração:
Independentemente de o usuário fazer ou não uma avaliação, o aplicativo precisará continuar em funcionamento sem alterar o fluxo de operação. A In-App Review API foi projetada para uma integração perfeita com a navegação dos usuários.
Você pode ver a In-App Review API em ação na nossa amostra recém-publicada. O exemplo exibe a chamada da API por meio da biblioteca de extensões Kotlin, Play Core KTX, além de outras APIs da Play Core, como atualizações no aplicativo e instalações de módulos de recursos sob demanda.
Com a API, os usuários podem compartilhar facilmente insights valiosos sobre seu aplicativo.
Confira a opinião de alguns dos nossos parceiros que participaram do programa de acesso antecipado:
"Com uma integração rápida e fácil das novas alterações da In-App Review API, vimos um aumento quase imediato nas avaliações e classificações positivas." - Chris Scoville, gerente de engenharia da Calm
- Chris Scoville, gerente de engenharia da Calm
"A nova In-App Review API permite que nossos clientes façam avaliações sem sair do aplicativo. Desde a implementação da API, vimos nossas classificações de 5 estrelas aumentar em 4 vezes." - Nathaniel Khuana, arquiteto técnico da Tokopedia
- Nathaniel Khuana, arquiteto técnico da Tokopedia
"Uma semana depois de implementarmos as avaliações no aplicativo, alcançamos nossa classificação mais alta de todos os tempos." - Welly Chandra, gerente de produtos associado da Traveloka
- Welly Chandra, gerente de produtos associado da Traveloka
Entendemos que o melhor feedback é honesto e imparcial. Por isso, projetamos um recurso independente, que não exige solicitações adicionais além da invocação da API. Também colocamos limites máximos para garantir que os usuários não recebam um número excessivo de solicitações, caso decidam não deixar uma avaliação.
Incentivamos os desenvolvedores a explorar a integração da In-App Review API para aproveitar um feedback de qualidade que somente os usuários dedicados podem fornecer. Depois de receber esse feedback, você pode acessar as diversas ferramentas de classificação e avaliação disponíveis no Google Play Console para analisar os comentários e responder diretamente às preocupações dos usuários.