Nesta postagem, explicarei como garantimos que a capacidade de serviço disponível do Meet antecedesse o uso 30 vezes maior durante a pandemia de COVID-19. Além disso, contarei o que fizemos para tornar esse crescimento sustentável, em termos técnicos e operacionais, aproveitando as diversas práticas recomendadas de engenharia de confiabilidade de sites (SRE, na sigla em inglês).
Alertas antecipados
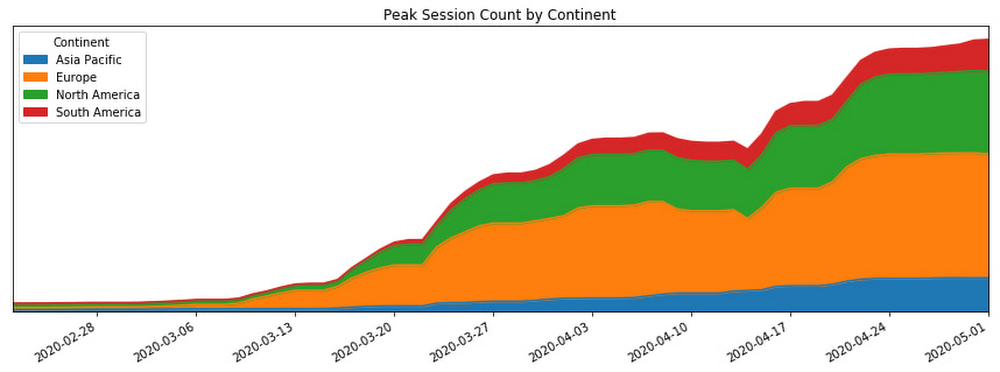
Aos poucos, o mundo se tornou mais consciente da pandemia de COVID-19, e as pessoas começaram a adaptar as rotinas diárias. O impacto crescente do vírus sobre os hábitos de trabalho, estudos e socialização com amigos e familiares gerou um aumento na procura por serviços de contato virtual, como o Google Meet. Em 17 de fevereiro, a equipe de SRE do Meet começou a receber páginas relacionadas a questões de capacidade regional.
As páginas eram sintomáticas ou alertas de caixa-preta, como "Falhas de muitas tarefas" e “Transferência de carga excessiva". Como os serviços do Google são desenvolvidos com redundância, esses alertas não indicavam problemas em andamento visíveis aos usuários. No entanto, logo ficou claro que o uso do produto na Ásia apresentava uma tendência acentuada de aumento.
Os especialistas em SRE começaram a trabalhar com a equipe de planejamento de capacidade para encontrar recursos adicionais que pudessem ajudar no gerenciamento desse aumento de acesso, mas ficou claro que precisávamos começar um planejamento com antecedência, caso a epidemia se espalhasse para outras regiões.
Como era de se esperar, assim que a Itália iniciou o período de lockdown contra a COVID-19, o uso do Meet começou a aumentar no país.
Um incidente não tradicional
Nesse ponto, começamos a elaborar nossa resposta. Como de costume, a equipe de SRE começou declarando um incidente, e demos início a nossa resposta relacionada ao risco de capacidade global.
Porém, é importante destacar que, embora tenhamos abordado esse desafio usando nossa estrutura de gerenciamento de incidentes testada e comprovada, naquele ponto não estávamos próximos nem prestes a ter uma interrupção do serviço. Não houve um impacto na experiência do usuário. A maioria dos efeitos sociais da pandemia de COVID-19 eram desconhecidos ou muito difíceis de prever. Nossa missão era abstrata: precisávamos evitar interrupções no que havia se tornado um produto essencial para um grande número de novos usuários, enquanto escalonávamos o sistema, sem saber o quanto ele cresceria e quando se estabilizaria.
Além disso, toda a equipe (junto com o restante do Google) estava em processo de transição para um período indefinido de trabalho remoto devido à pandemia de COVID-19. Embora a maioria dos nossos fluxos de trabalho e das ferramentas já estivesse acessível fora dos nossos escritórios, havia outros desafios associados à execução virtual de um incidente de longa data.
Como não podíamos sentar juntos para conversar, percebemos que era importante gerenciar os canais de comunicação de maneira proativa, garantindo que todos tivéssemos acesso às informações necessárias para atingir nossos objetivos. Muitos de nós também enfrentaram desafios adicionais não relacionados ao trabalho, como cuidar de amigos e familiares durante a adaptação à nova realidade. Embora esses fatores tenham criado obstáculos extras para nossa resposta, estratégias como atribuir e eleger substitutos, além de gerenciar proativamente propriedades e canais de comunicação, nos ajudaram a superar as dificuldades.
Mesmo assim, seguimos usando nossa abordagem de gerenciamento de incidentes. Começamos nossa resposta global definindo um Comandante de Incidentes, um Líder de Comunicações e um Líder de Operações, tanto na América do Norte quanto na Europa, para que tivéssemos cobertura 24 horas por dia.
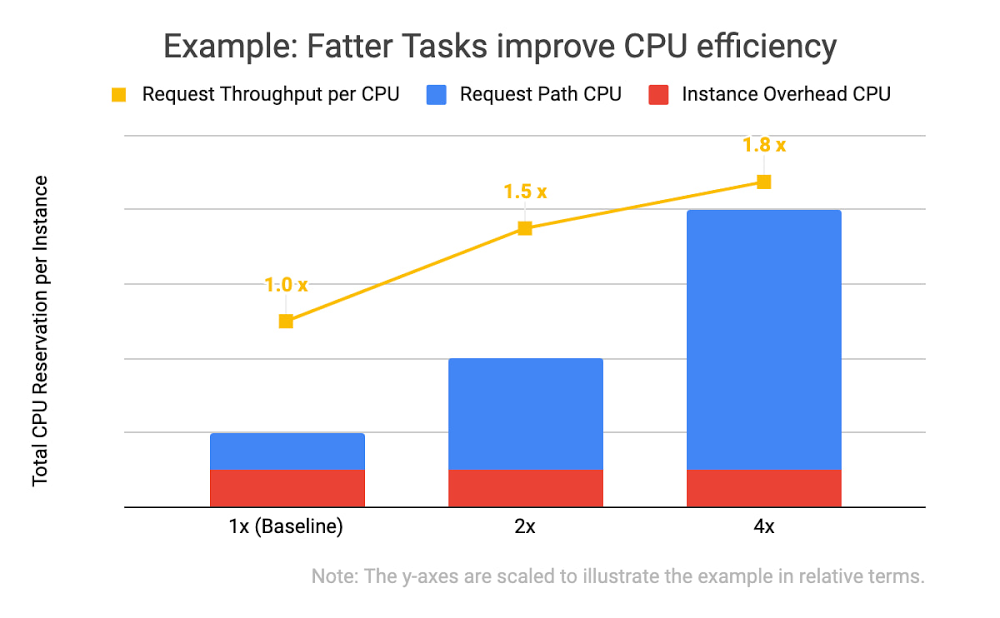
Como um dos Comandantes de Incidentes Gerais, minha função era semelhante à de um roteador de informações com estado, ainda que com opiniões, influência e poder de tomada de decisão. Coletei informações de status sobre quais problemas táticos persistiam, quais ações estavam sendo executadas e por quem e identifiquei os contextos que afetavam nossa resposta (por exemplo, as respostas dos governos à pandemia de COVID-19). Depois disso, enviei o trabalho para as pessoas que poderiam ajudar. Detectei e explorei as áreas de incerteza, tanto para a definição de problemas, por exemplo, “Pode ser um problema executar o serviço com 50% de utilização da CPU na América do Sul?”, quanto para as possíveis soluções, "Como vamos acelerar nosso processo de ativação?”. Assim, pude coordenar nosso esforço de resposta geral e garantir que todas as tarefas necessárias fossem encaminhadas às pessoas certas.
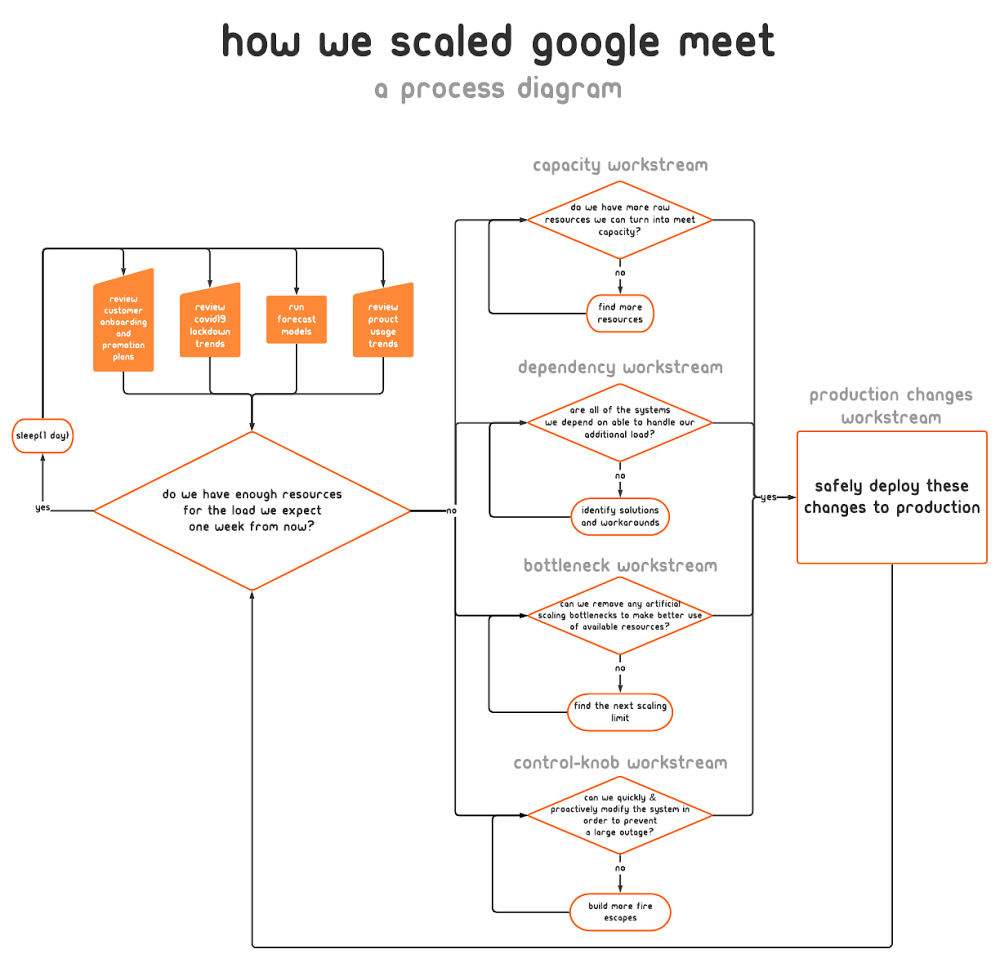
Não demorou muito para percebemos que o escopo da nossa missão era enorme e que a natureza da nossa resposta seria de longa duração. Para manter um escopo gerenciável para cada colaborador, dividimos nossa resposta em uma série de fluxos de trabalho semi-independentes. Nos casos em que os escopos se sobrepunham, a interface entre os fluxos de trabalho era novamente definida.



2 comentários :
OLÁ! Muitíssimo obrigado a todos vocês que trabalharam incansavelmente para produzir uma forma de facilitar a vida das pessoas que estão em isolamento!
Sou professora de educação especial, alunos com deficiência, e não entendia nada, nadinha de encontros virtuais. Porém, a necessidade de ficarmos em casa e lecionar ao mesmo tempo nos "obrigou" a aprender a utilizar várias ferramentas digitais . Estou feliz com o pouco que aprendi, mas pretendo continuar a busca por conhecimento digital.
Parabéns a todos pelo trabalho realizado, e obrigada por disponibilizá-lo para nós professores brasileiros. Meus sinceros agradecimentos à todos vocês da Google.
Your content is always insightful and helpful. Govt Policies on Ehsaas Program 8171 Appreciate it!
Postar um comentário