Em resposta à pandemia global, a Casa Branca e uma coalizão de grupos de pesquisa publicaram o conjunto de dados de pesquisa aberta sobre a COVID-19 (CORD-19, na sigla em inglês) no Kaggle, a maior comunidade de ciência de dados on-line do mundo. O objetivo de ampliar nossa compreensão sobre os tipos de coronavírus e outras doenças chamou a atenção de muitas pessoas nas áreas de políticas de saúde, pesquisa e comunidade médica. De acordo com este artigo da Nature, o desafio do Kaggle teve mais de 2 milhões de visualizações de página desde o lançamento em meados de março.
O conjunto de dados é disponibilizado gratuitamente para pesquisadores e o público em geral. O acervo com mais de 150 mil artigos acadêmicos, inclui milhares de títulos só sobre a COVID-19, o que torna quase impossível acompanhar todos os textos mais recentes. Além disso, há milhões de publicações médicas com informações que podem aumentar nosso entendimento científico sobre essa e outras doenças. No entanto, boa parte desse material não está originalmente pronto para ser acessado em máquinas e resumir e analisar esse conteúdo usando ferramentas de processamento de linguagem natural pode ser muito complicado.
Assim, iniciou o trabalho da comunidade de inteligência artificial (IA) do Google. Esse grupo de cientistas de dados, formado fora empresa, é conhecido como Especialistas em aprendizado de máquina do Google Developer (ML GDEs, na sigla em inglês). Ele é formado por profissionais de IA altamente qualificados, de todas as partes do mundo. Com o suporte de créditos do Google Cloud e do TensorFlow Research Cloud (TFRC), os ML GDEs começaram a resolver o problema de compreensão da literatura de pesquisa. Embora não sejam especialistas da área de saúde, eles perceberam rapidamente que poderiam contribuir no enfrentamento da crise atual, aplicando o conhecimento de Big Data e IA no campo da biomedicina.
A equipe foi formada em abril com o audacioso nome de “IA versus COVID-19” (aiscovid19.org) e definiu o objetivo de usar o aprendizado de máquina e tecnologias de nuvem de última geração para ajudar os pesquisadores de biomedicina a descobrir mais rapidamente insights na literatura relacionada.
Criação do conjunto de dados
A primeira etapa da equipe ML GDE foi entrar em contato com os pesquisadores de biomedicina para entender melhor os fluxos de trabalho, as ferramentas, os desafios e o mais importante: a “relevância” na literatura médica. Foram descobertos alguns insights comuns:
Existe uma quantidade imensa de informações antigas e novas
Há fontes ambíguas e inconsistentes
A funcionalidade de recuperação das informações é limitada nas ferramentas atuais
A pesquisa usa como base apenas palavras-chave simples
Há vários conjuntos de dados dispersos
O significado das palavras não pode ser compreendido no contexto
Um dos pilares da atual revolução da IA é a capacidade desses sistemas de se tornarem mais precisos à medida que analisam os dados. Em trabalhos recentes (BERT, XLNEt, T5 e GPT3), milhões de documentos são usados para treinar redes neurais de última geração para tarefas de PLN.
Com base nesses insights, a equipe chegou à conclusão de que a melhor forma de ajudar a comunidade de pesquisa era criar um conjunto de dados único com um corpus de documentos bastante amplo e, em seguida, disponibilizar esse conteúdo em formatos que possam ser acessados nas máquinas. Usando como inspiração o movimento Open Access e iniciativas como a Meta, do Instituto Chan Zuckerberg, foi feita uma busca pelo maior número possível de publicações relevantes, exclusivas e gratuitas para reuni-las em um conjunto de dados acessível, projetado especificamente para treinar sistemas de IA.
Apresentação do BREATHE
O Biomedical Research Extensive Archive To Help Everyone (BREATHE) é um banco de dados em grande escala com entradas dos principais repositórios de pesquisa em biomedicina. Esse acervo contém títulos, resumos e textos completos (quando permitido pela licença) de mais de 16 milhões de artigos biomédicos publicados em inglês. A primeira versão foi lançada em junho de 2020, e novas versões são esperadas, já que o corpus de artigos é constantemente atualizado pelos pesquisadores. Coletar artigos escritos originalmente em outros idiomas, além do inglês, está entre as ideias para melhorar o conjunto de dados e o conhecimento específico do domínio que ele tenta capturar.
Existem diversos conjuntos de dados específicos sobre a COVID-19, mas os diferenciais do BREATHE são os seguintes:
Tamanho: contém várias fontes diferentes
Legibilidade por máquina
Acesso público e gratuito
Hospedagem de armazenamento escalonável, fácil de analisar e com bom custo-benefício por meio do Google BigQuery
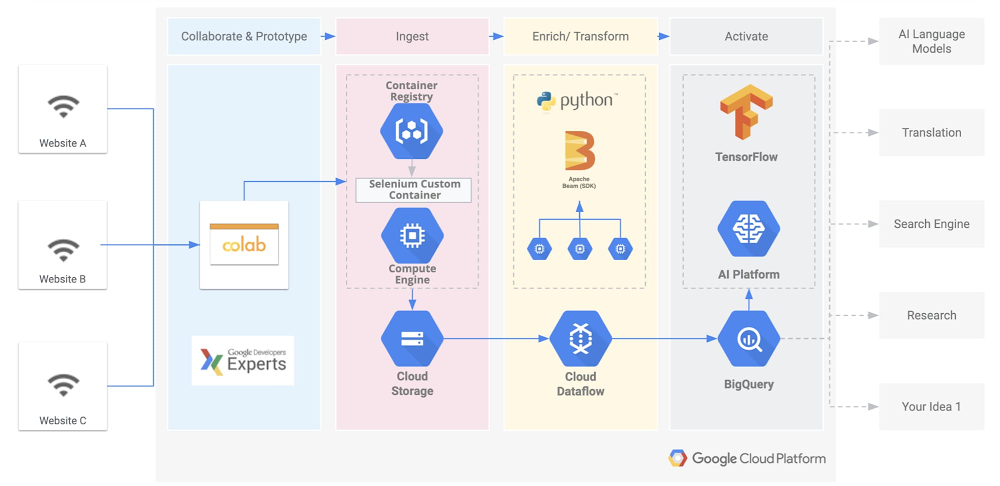
Abordagem de desenvolvimento do BREATHE
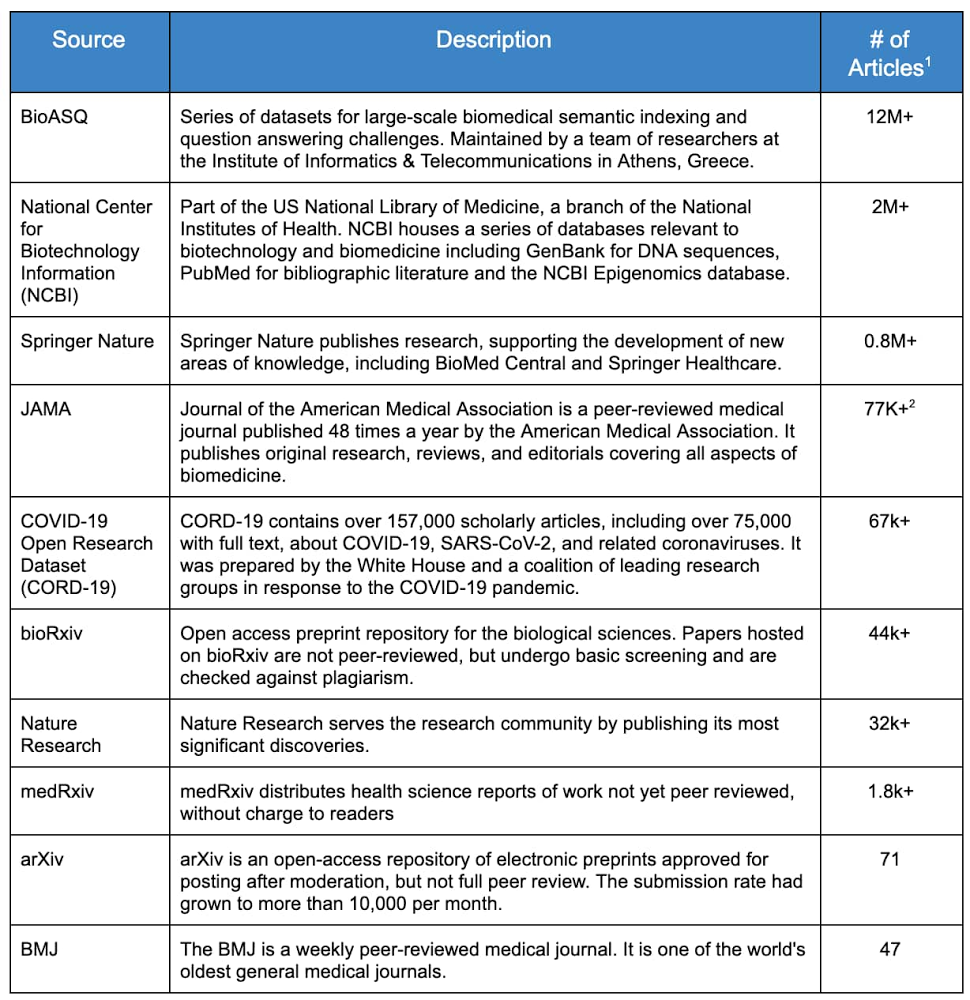
A equipe ML GDE identificou os dez principais arquivos da Web, ou “fontes”, com material em potencial. Três fatores principais foram usados como base: a disponibilidade, a quantidade e a qualidade dos dados. Essas fontes estão listadas na Tabela 1.
Tabela 1: arquivos médicos


2 comentários :
Google's AI theme leverages cloud technology to create the BREATHE dataset, which assists biomedical researchers in navigating large volumes of medical literature, much like how poppy playtime chapter 3 challenges players to solve complex puzzles in an immersive environment.
This article was a game-changer for me. Govt Cash Assistance Through 8171 Ehsaas Thanks!
Postar um comentário