Está se tornando cada vez mais simples e útil tornar o aprendizado de máquina (ML, na sigla em inglês) parte dos processos de negócios, mas a execução de jobs de ML pode ser dispendiosa. Por exemplo, você pode programar de forma periódica, geralmente diária, execuções de treinamento e ajuste ou realizar regularmente experimentos de ajuste de hiperparâmetro em larga escala. No entanto, essas execuções normalmente não precisam terminar em uma janela de tempo fixa. Se você tiver alguma flexibilidade de tempo e disponibilidade, as VMs preemptivas com GPUs podem ser uma tática útil para reduzir significativamente os custos.
Nesta postagem, mostraremos como usar
VMs preemptivas provisionadas com GPU ao executar jobs do
Kubeflow Pipelines para fazer exatamente isso. Também veremos como você pode usar o
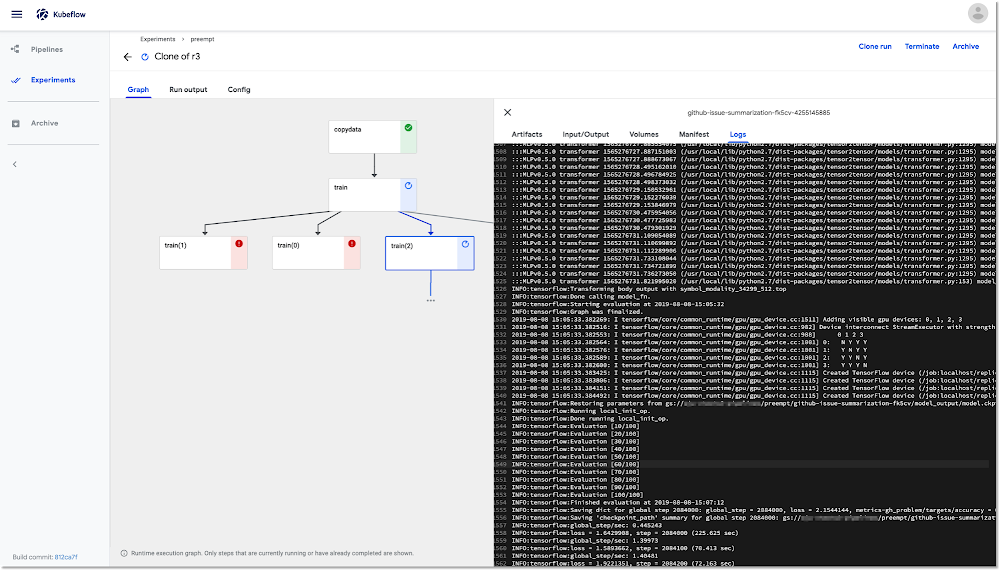
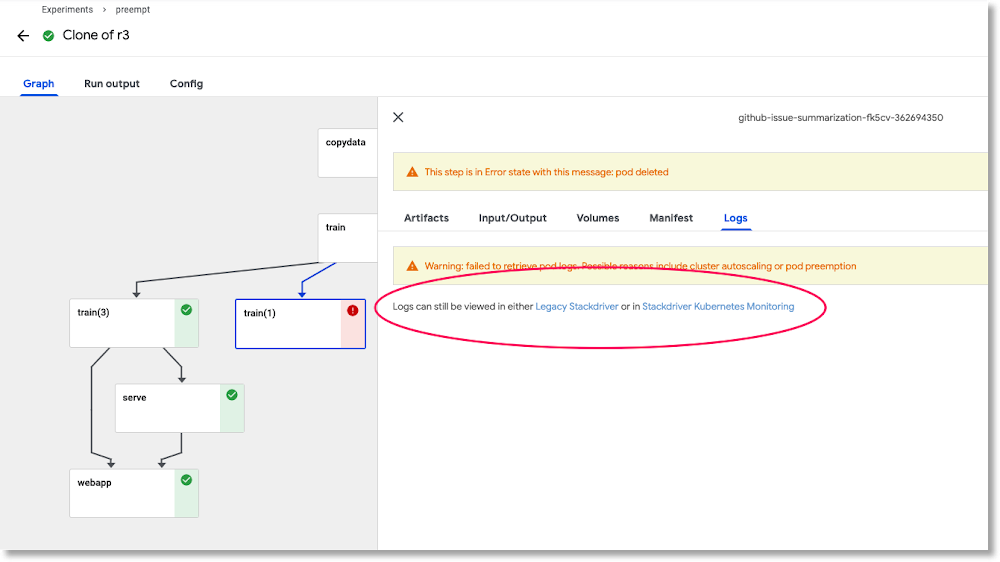
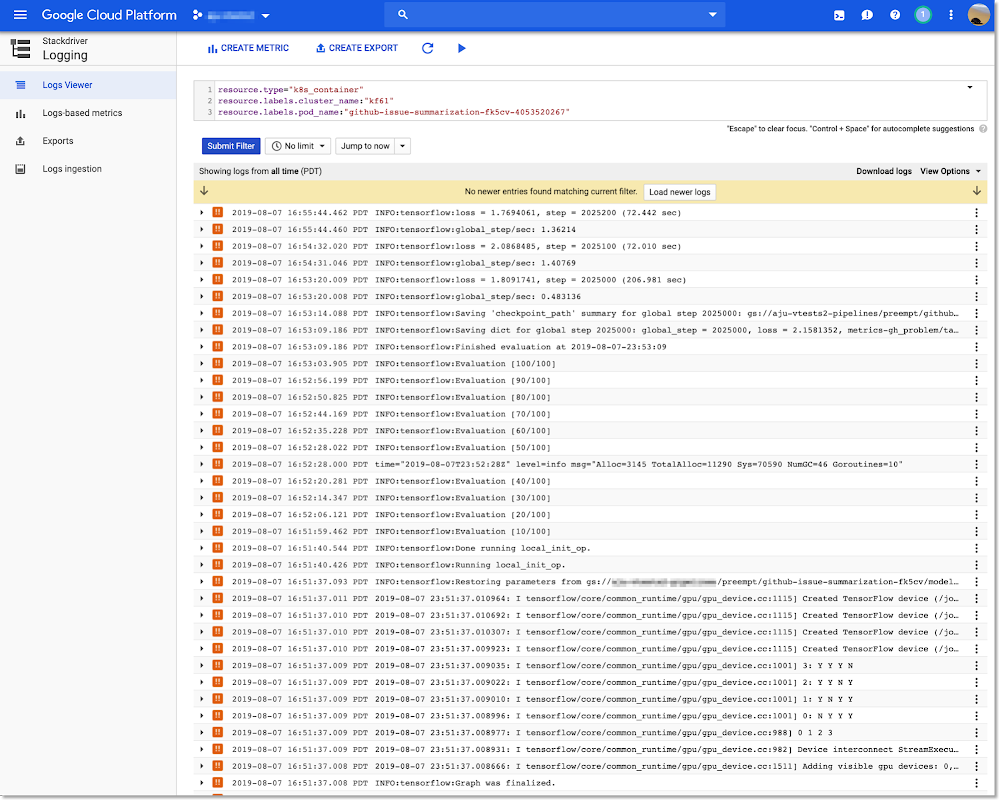
Stackdriver Monitoring para inspecionar registros das operações de canal atuais e finalizadas.
VMs preemptivas são instâncias de
VM do Compute Engine que duram no máximo 24 horas e não fornecem garantias de disponibilidade. Por isso, elas têm um preço menor que o das VMs padrão do Compute Engine. Com o
Google Kubernetes Engine (GKE), é fácil configurar um cluster ou pool de nós
que use VMs preemptivas. É possível configurar um pool de nós com
GPUs anexadas às instâncias preemptivas. Esses nós funcionam da mesma maneira que os nós comuns habilitados para GPU, mas as GPUs persistem apenas durante a vida útil da instância.
O
Kubeflow é um projeto de código aberto dedicado a fazer as implantações de fluxos de trabalho de aprendizado de máquina no
Kubernetes simples, portáteis e escalonáveis. O
Kubeflow Pipelines é uma plataforma para criar e implantar fluxos de trabalho portáteis e escalonáveis de aprendizado de máquina com base em contêineres do Docker.
Se você estiver executando o Kubeflow no GKE, agora é fácil
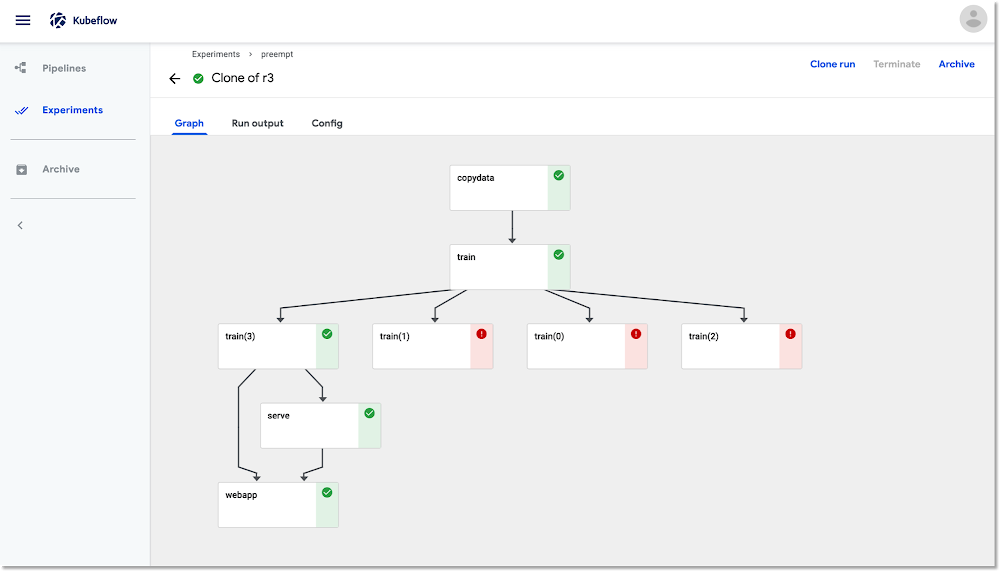
definir e operar o Kubeflow Pipelines, no qual uma ou mais etapas (componentes) do canal são realizadas em nós preemptivos, reduzindo o custo da execução de um job. Para conseguir resultados corretos ao usar VMs preemptivas, as etapas que você identifica como preemptivas precisam ser
idempotentes (ou seja, se você realizar uma etapa diversas vezes, ela terá o mesmo resultado), ou o ponto de verificação deverá funcionar para que a etapa possa continuar de onde parou, caso seja interrompida.
Por exemplo, a cópia de um diretório do
Google Cloud Storage terá os mesmos resultados se for interrompida e executada novamente, assumindo que o diretório de origem não seja alterado. Uma operação para treinar um modelo de aprendizado de máquina (por exemplo, uma execução de treinamento do TensorFlow) normalmente é configurada para o ponto de verificação periodicamente. Assim, se o treinamento for interrompido por preempção, poderá simplesmente continuar de onde parou quando a etapa for reiniciada. A maioria das bibliotecas de ML facilita o suporte ao ponto de verificação. Portanto, se seu canal do Kubeflow inclui etapas de treinamento de modelo, elas são ótimas candidatas para execução em nós preemptivos habilitados para GPU.


Um comentário :
Your post saved me so much time. How Ehsaas Program Compares to BISP Thank you for this!
Postar um comentário