Blog oficial para desenvolvedores que falam português
Apresentação do kit de ferramentas de otimização de modelo do TensorFlow
05/10/2018
Estamos entusiasmados com a apresentação do novo kit de ferramentas de otimização do TensorFlow: um conjunto de técnicas que desenvolvedores iniciantes ou avançados podem usar para otimizar modelos de aprendizado de máquina para implantação e execução.
Esperamos que essas técnicas sejam úteis para otimizar qualquer modelo do TensorFlow para implantação, mas elas são especialmente importantes para desenvolvedores do TensorFlow Lite, que disponibilizam modelos para dispositivos com limitações de memória, energia e armazenamento. Se você ainda não experimentou o TensorFlow Lite, saiba mais clicando
aqui
.
Otimize modelos para reduzir tamanho, latência e consumo de energia com perda de precisão insignificante
A primeira técnica que passamos a oferecer é a quantização pós-treinamento para a ferramenta de conversão do TensorFlow Lite. Essa técnica pode gerar compressão 4 vezes maior e execução 3 vezes mais rápida para os modelos de aprendizado de máquina.
Quantizando os modelos, os desenvolvedores ainda ganham a vantagem de reduzir o consumo de energia. Isso é bastante útil para implantação em dispositivos de borda, além de celulares.
Ativação da quantização pós-treinamento
A técnica de quantização pós-treinamento está integrada à ferramenta de conversão do TensorFlow Lite. E começar a usar é bem fácil: depois de construir o modelo no TensorFlow, os desenvolvedores podem simplesmente ativar o sinalizador "post_training_quantize" na ferramenta de conversão do TensorFlow Lite. Presumindo que o modelo salvo está armazenado em "saved_model_dir", o flatbuffer tflite quantizado pode ser gerado:
<a href="https://medium.com/media/9e358f0041b185aea2b9f26c1fd4b4de/href">https://medium.com/media/9e358f0041b185aea2b9f26c1fd4b4de/href</a>
Nosso
tutorial
mostra detalhadamente como fazer isso. No futuro, também queremos incorporar essa técnica às ferramentas gerais do TensorFlow para que possa ser usada na implantação em plataformas que hoje não contam com o suporte do TensorFlow Lite.
Benefícios da quantização pós-treinamento
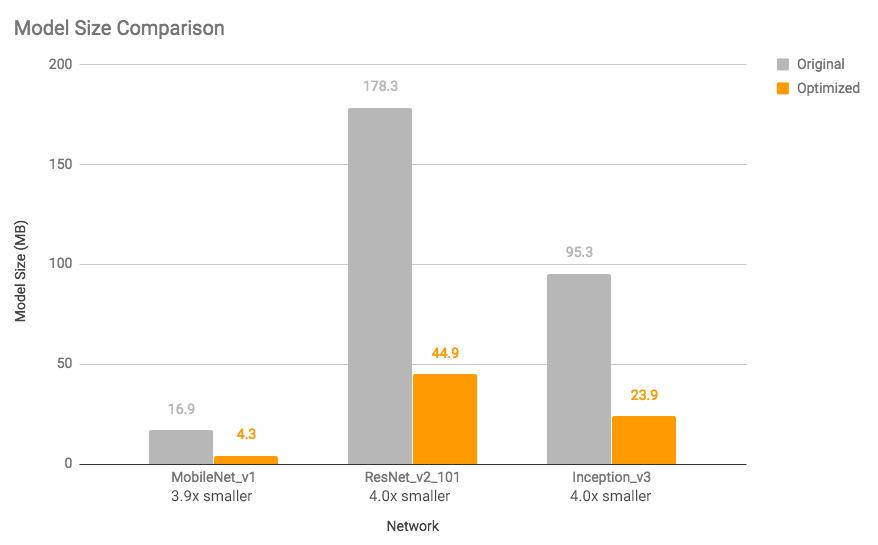
Redução de 4x no tamanho dos modelos
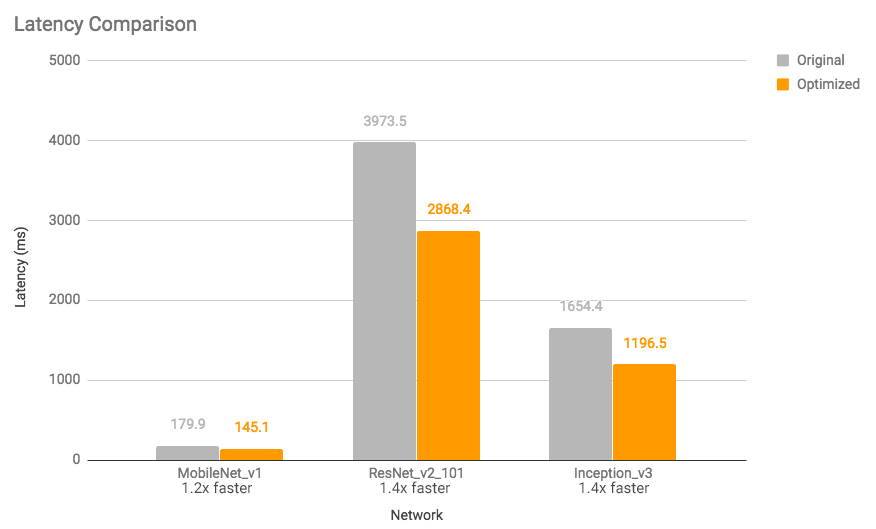
A execução de modelos, compostos principalmente de camadas convolucionais, fica 10% a 50% mais rápida
Modelos baseados em RNN ganham até 3x mais velocidade
Com os requisitos reduzidos de memória e computação, também esperamos que a maioria os modelos consuma menos energia
Nos gráficos abaixo, você pode ver redução de tamanho e o ganho de velocidade de execução de alguns modelos (medições em um Android Pixel 2 usando apenas um núcleo).
Figura 1: Comparação de tamanho dos modelos: os otimizados são praticamente 4x menores
Figura 2: Comparação de latência: modelos otimizados são de 1,2 a 1,4x mais rápidos
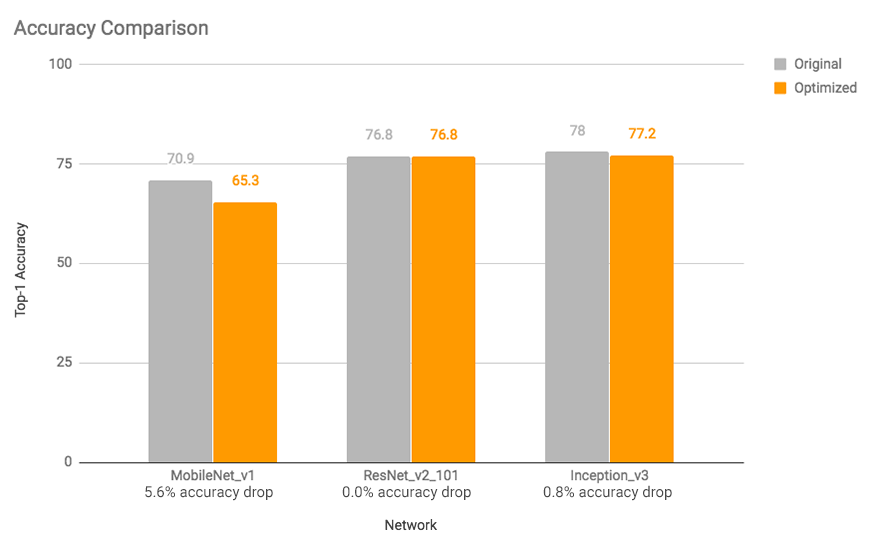
Essas otimizações de velocidade e tamanho afetam pouco a precisão. Em geral, modelos que já são pequenos para a tarefa em questão (como o mobilenet v1 para classificação de imagens) podem sofrer maior perda de precisão. Pensando em muitos desses casos, oferecemos
modelos totalmente quantizados
pré-treinados.
Figura 3: Comparação de precisão: modelos otimizados apresentam queda insignificante de precisão, exceto os mobilenet
Com o tempo, esperamos continuar melhorando esses resultados. Não deixe de ler o guia de
otimização de modelos
para conhecer as medições mais recentes.
Como a quantização pós-treinamento funciona?
Internamente, executamos otimizações (também chamadas de quantizações) reduzindo a precisão dos parâmetros (ou seja, pesos da rede neural) das representações de ponto flutuante de 32 bits do tempo de treinamento para números inteiros de 8 bits, muito menores e mais eficientes. Veja o guia de
quantização pós-treinamento
para saber mais.
Com essas otimizações, conseguimos unir as definições de operação de precisão reduzida no modelo resultante com implementações de kernel que usam uma combinação de matemática de ponto flutuante e de ponto fixo. Dessa forma, os cálculos mais pesados são executados com mais velocidade e menor precisão, mas os mais delicados são executados com alta precisão. Normalmente, o resultado é uma perda de precisão final nula ou insignificante para a tarefa, mas um ganho de velocidade substancial sobre a execução de ponto-flutuante pura. Nas operações em que não haja um kernel "híbrido" correspondente, ou quando o Tookit julgue necessário, os parâmetros serão reconvertidos para a maior precisão de ponto flutuante para a execução. Acesse a página
quantização pós-treinamento
para ver uma lista de operações híbridas compatíveis.
Trabalho futuro
Continuaremos a aprimorar a quantização pós-treinamento e trabalharemos em outras técnicas que facilitem a otimização de modelos. Essas técnicas serão integradas aos fluxos de trabalho relevantes do TensorFlow para facilitar seu uso.
A quantização pós-treinamento é o primeiro resultado obtido com o toolkit de otimização que estamos desenvolvendo. Contamos com o feedback dos desenvolvedores.
Registre os problemas no
GitHub
e faça perguntas no
Stack Overflow
.
Agradecimentos
Gostaríamos de agradecer a Raghu Krishnamoorthi, Raziel Alvrarez, Suharsh Sivakumar, Yunlu Li, Alan Chiao, Pete Warden, Shashi Shekhar, Sarah Sirajuddin e Tim Davis pelas contribuições essenciais. Mark Daoust ajudou a criar o
tutorial de colaboração
. Billy Lamberta e Lawrence Chan ajudaram na criação do
site
.
Nenhum comentário :
Postar um comentário
Labels
+page
1
20th Century Fox
1
A/B
1
Action
1
Action Console
1
Actions
3
Actions Console
1
Actions on Google
1
ActiveQA
1
Adaptive Battery
1
AddThis
1
ADK
1
ADL
1
Admin do Firebase
1
AdMob
6
Ads
2
AdWords
1
AdX
1
AI
4
algoritmo
1
AMP
6
AMP Linker
1
AMP Project
1
Analytics API
1
Android
58
Android 8.0 Oreo
1
Android 8.1
1
Android ADK
2
Android API
2
Android App Bundle
1
Android Dev Summit
1
Android Developers
23
Android Marshmallow
1
Android N
3
Android Nougat
2
Android P
3
Android P Beta 2
1
Android Preview
1
Android SDK
1
android studio
8
Android Studio 3.2
1
android wear
2
AndroidDev
6
AndroidX
1
Announcement
2
AoG
1
AoGDevs
1
api
15
API 25
1
API 28
1
APIs
4
Aplicativos
4
app
1
App Engine
1
Apple
1
apply
1
Apps
9
AR
1
ARCore
3
artificial intelligence
1
AsyncTask
1
AUC
1
AutoAugment
1
Avro
1
Awareness API
1
Biblioteca do Google
1
Big Data
1
BigQuery
1
BiometricPrompt
1
bitcode
1
Borg
1
Bot
1
bytecode Dalvik
1
C++
1
câmera
1
CameraDevice
1
Canal Beta
1
canary
1
câncer de próstata
1
Capital One
1
Cast
1
CFI
1
Chrome
8
Chrome 68
1
Chrome Dev Summit
1
Chrome DevTools
1
Chrome OS
2
Chromecast
1
Chromium
2
CI
1
CLI
1
Cloud
6
Cloud Computing
1
Cloud Console
1
Cloud Dataflow
1
Cloud Developers
2
Cloud DLP
1
Cloud Firestore
1
Cloud Messaging
1
Cloud ML Engine
1
Cloud Scheduler
1
Cloud Shell
1
Cloud Source Repositories
1
Cloud Spanner
2
CodeSchool
1
código aberto
2
Compute Engine
1
ConfigMap
1
Container Builder
1
CPU
2
Crash Reporting
2
Crashlytics
3
credential api
1
criptografia
1
CSS
3
CSS Grid Layout
1
CSV
1
CTA
1
Curitiba
1
Dart API
1
Data Validation
1
DBAs
1
DCGAN
1
Desenvolvedores Google
11
Desenvolvimento
3
DevBusBrasil
1
DevBytes
2
Developer Bus
1
Developer Preview
1
developer quiz
1
DevFest
3
DevFest16
1
DevFest18
1
DevFestW
1
DFP
2
Dialogflow
1
DLP
1
DLS
1
documentação
1
Dragon Ball Legends
1
E2E
1
eclipse
1
end-to-end-encryption
1
Estimator
1
Estimators API
1
estudantes
1
Eventos
15
Famílias multilíngue
1
FCM
2
Featured
1
Firebase
24
Firebase Analytics
6
Firebase App Indexing
2
Firebase Cloud Messaging
5
Firebase Crashlytics
2
Firebase Dynamic Links
3
Firebase In-App Messaging
1
Firebase Invites
2
Firebase Lab
1
Firebase Links Dinamicos
1
Firebase Notifications
3
Firebase Remote Config
1
Flutter
3
FRR
1
G+
1
game
1
game dev
3
Games
2
games services
1
GCloud
3
GCM
1
GCP
7
GDD
7
GDE
1
GDEs
1
GDG
12
GDG Curitiba
1
GDG Floripa
1
GDG OpenSampa
1
GDG Porto Alegre
1
GDG Recife
1
GDG SP
3
GDGs
1
GDL
1
Git
1
GitHub
1
GNMT
1
Google
3
Google Ad Manager
1
Google AI
1
Google Analytics
1
Google Assistant
1
Google Assistente
3
Google Brain
2
Google Cast SDK
1
google clou
1
Google Cloud
17
Google Cloud Certified
1
Google Cloud Healthcare API
1
Google Cloud Platform
3
google code-in
1
Google Developer Advocate
1
Google Developer Expert
1
Google Developers
11
Google Fotos
1
Google I/O
6
Google Play
16
Google Play Games services
1
Google Play Protect
1
Google Play Services
4
Google Slides
1
Google Speech
1
google summer of code
1
Google+
2
Google+ sign-in
1
Googlers
1
GPU
2
GSuites
1
GUI
1
Hackathon
1
Hangouts
1
Hangouts Chat
1
HDR
1
High Quality Apps
2
HTML5
6
HTTP
3
HTTPS
2
HttpURLConnection
2
I/O
1
IA
2
Illusive Images
1
ImageReader
1
In-App Messaging
1
Inglês
1
Instant Apps
1
inteligencia artificial
1
IntelliJ REPL
1
IntentService
1
Interoperabilidade
1
IO Extended
1
IO13
1
iOS
9
IU
2
Java
1
Java 8
1
javascript
2
JPEG
1
JSON
2
Kaggle
1
kernel
1
Keyboard Map API
1
Knowledge Connectors
1
Kotlin
6
Kotlin da Udacity
1
Kubernetes
5
LangID
1
Launchpad
1
launchpad accelerator
2
Learning Augmentation
1
LEGO
1
Listas
1
ListFragment
1
LLVM
1
LTO
1
Machine Learning
2
Meetup
2
mensagens
1
Mentoria
1
Messaging
2
microsserviços
1
ML
2
ML Kit
1
Mobile
3
Mobile Ads SDK
1
Monetização
3
Monetize
3
MySQL
1
Native
1
Navigation Architecture Component
1
NES
1
Neto Marin
2
Next Level Apps
2
Next Level Tips
2
NNLM
1
Node.js
2
Notificações
1
novembro azul
1
Number Genie
1
Nuvem Profissional
1
OAuth
2
OAuth2
1
Open Images Extended
1
open source
3
Options Menu
1
Options Menu virtual
1
Orkut
2
Payment Request
1
pesquisa
1
PHA
1
Phone Gateway
1
PII
1
pixel
1
Play Academy
1
Play Console
1
Play Services
1
Playtime 2018
1
plug-in AMP
1
Porto Alegre
1
Preact
1
PRIV
1
program
1
progressive web apps
2
Push Notification
2
Python
1
QA
1
RA
2
Raspberry Pi
1
RBDMS
1
React
1
recording apis
1
remarketing
1
Remote Config
2
research
4
ResultReceiver
1
reward
1
RNN
2
Robolectric 4.0
1
RV
1
Sceneform
1
SDK
4
SDK Manager
3
Security
2
Server
1
service worker
1
sign-in
1
Sliding Tabs
1
Smartronix
1
social
6
Spark
1
SRE
1
Stack
1
Stack Overflow
1
Startups
2
Storage
2
story
1
Support Library
1
SurfaceView
1
Svelte
1
switch
1
Tag Manager
1
Tag Manager 360
1
tensorflow
5
TensorFlow Hub
2
TensorFlow Lite
1
TensorFlow Transform
1
Test Lab
2
Testes
1
TF Hub
2
tf.keras
1
TFDV
1
TFX
1
TI essencial
1
toolkit
1
tradução
1
TTS
1
Udacity
1
Universal Apps
1
Universal Sentence Encoder
1
user experience
1
ux
1
VectorDrawable
1
Velostrata
1
Volley
1
vr
2
vulnerabilidades
1
vulnerabilidades do Google
1
vulnerability
1
web
2
web dev
2
WebKit
1
webservice
3
when
1
WordPress
1
WorkerDOM
1
YouTube
4
YouTube API
1
YUV
1
Zomato
1
Archive
2022
nov.
out.
jul.
jun.
mai.
abr.
mar.
fev.
jan.
2021
dez.
nov.
out.
set.
ago.
jul.
jun.
mai.
abr.
mar.
fev.
jan.
2020
dez.
nov.
out.
set.
ago.
jul.
jun.
mai.
abr.
mar.
fev.
jan.
2019
dez.
nov.
out.
set.
ago.
jul.
jun.
mai.
abr.
2018
dez.
nov.
out.
set.
ago.
jul.
jun.
mai.
abr.
mar.
fev.
2017
ago.
jul.
jun.
mai.
abr.
mar.
jan.
2016
dez.
nov.
out.
set.
ago.
jul.
mai.
mar.
2014
jul.
jun.
abr.
mar.
fev.
2013
dez.
nov.
out.
set.
ago.
jul.
jun.
mai.
mar.
fev.
jan.
2012
nov.
jul.
jun.
mai.
abr.
mar.
2011
nov.
set.
ago.
jul.
jun.
Feed
Follow @googledevbr






Nenhum comentário :
Postar um comentário