Na Zalando Research, assim como na maioria dos departamentos de pesquisa de IA, sabemos da importância da agilidade nos testes e na criação de protótipos. Com os conjuntos de dados ficando cada vez maiores, é bom saber como treinar modelos de aprendizado profundo com velocidade e eficiência usando os recursos compartilhados disponíveis.
A API Estimators do TensorFlow é útil para treinar modelos em ambientes distribuídos com várias GPUs. Aqui, apresentaremos esse fluxo de trabalho treinando um estimador personalizado criado com tf.keras para o pequeno conjunto de dados Fashion-MNIST. Depois mostraremos um caso de uso mais prático.
Nota: a equipe do TensorFlow também está trabalhando em um recurso novo e incrível (no momento da criação deste artigo, ainda está na fase de master) que permite treinar um modelo tf.keras sem precisar transformá-lo em um estimador, usando apenas algumas poucas linhas de código a mais. Esse fluxo de trabalho também é ótimo. Abaixo, nos limitaremos à Estimators API. Escolha o que for melhor para você.
TL;DR: na essência, o que queremos lembrar é que um tf.keras.Model pode ser treinado com a API tf.estimator convertendo-o em um objeto tf.estimator.Estimator pelo método tf.keras.estimator.model_to_estimator. Depois da conversão, podemos aplicar as ferramentas que o Estimators oferece para treinar em diferentes configurações de hardware.
Você pode baixar o código desta postagem neste bloco de anotações e executá-lo por conta própria.
import osimport time
#!pip install -q -U tensorflow-gpuimport tensorflow as tf
import numpy as np
Usaremos o conjunto de dados Fashion-MNIST, uma substituição direta do MNIST, que contém milhares de imagens em escala de cinza dos artigos de moda da Zalando. Obter os dados de treinamento e teste é bem simples:
(train_images, train_labels), (test_images, test_labels) = tf.keras.datasets.fashion_mnist.load_data()
Queremos converter os valores de pixels dessas imagens de um número entre 0 e 255 em um número entre 0 e 1 e converter o conjunto de dados para o formato [B,H,W,C], onde "B" é o número de imagens do lote, "H" e "W" são a altura e o comprimento, e "C" é o número de canais (1 para escala de cinza) do nosso conjunto:
TRAINING_SIZE = len(train_images)TEST_SIZE = len(test_images)
train_images = np.asarray(train_images, dtype=np.float32) / 255# Convert the train images and add channelstrain_images = train_images.reshape((TRAINING_SIZE, 28, 28, 1))
test_images = np.asarray(test_images, dtype=np.float32) / 255# Convert the test images and add channelstest_images = test_images.reshape((TEST_SIZE, 28, 28, 1))
Depois, precisamos converter os rótulos de um ID de número inteiro (por exemplo, 2 ou suéter) para uma codificação tipo one-hot (por exemplo, 0,0,1,0,0,0,0,0,0,0). Para fazer isso, usaremos a função tf.keras.utils.to_categorical:
# How many categories we are predicting from (0-9)LABEL_DIMENSIONS = 10
train_labels = tf.keras.utils.to_categorical(train_labels, LABEL_DIMENSIONS)
test_labels = tf.keras.utils.to_categorical(test_labels, LABEL_DIMENSIONS)
# Cast the labels to floats, needed latertrain_labels = train_labels.astype(np.float32)test_labels = test_labels.astype(np.float32)
Criaremos nossa rede neural usando a API Keras Functional. O Keras é uma API de alto nível para criar e treinar modelos de aprendizado profundo que é intuitiva, modular e fácil de ampliar. O tf.keras é a implementação do TensorFlow para essa API e oferece suporte a recursos como execução antecipada, canais tf.data e estimadores.
Para a arquitetura, usaremos os ConvNets. Em um nível bem resumido, os ConvNets são pilhas de camadas convolucionais (Conv2D) e camadas de agrupamento, ou pooling (MaxPooling2D). Mas o mais importante é que, para cada exemplo de treinamento, eles recebem tensores 3D de formato (altura, largura e canais). No caso de imagens em escala de cinza, começam com channels=1 e retornam um tensor 3D.
Portanto, depois da parte do ConvNet, precisaremos nivelar (Flatten) o tensor e adicionar camadas de densidade (Dense) em que a última retorna um vetor de tamanho LABEL_DIMENSIONS com a ativação de tf.nn.softmax:
inputs = tf.keras.Input(shape=(28,28,1)) # Returns a placeholder
x = tf.keras.layers.Conv2D(filters=32, kernel_size=(3, 3), activation=tf.nn.relu)(inputs)
x = tf.keras.layers.MaxPooling2D(pool_size=(2, 2), strides=2)(x)
x = tf.keras.layers.Conv2D(filters=64, kernel_size=(3, 3), activation=tf.nn.relu)(x)
x = tf.keras.layers.Flatten()(x)
x = tf.keras.layers.Dense(64, activation=tf.nn.relu)(x)predictions = tf.keras.layers.Dense(LABEL_DIMENSIONS, activation=tf.nn.softmax)(x)
Agora, podemos definir o nosso modelo, selecionar o otimizador (escolhemos um do TensorFlow, e não do tf.keras.optimizers) e compilá-lo:
model = tf.keras.Model(inputs=inputs, outputs=predictions)
optimizer = tf.train.AdamOptimizer(learning_rate=0.001)
model.compile(loss='categorical_crossentropy', optimizer=optimizer, metrics=['accuracy'])
Para criar um estimador no modelo Keras compilado, chamamos o método model_to_estimator. Veja que o estado inicial do modelo Keras é preservado no estimador criado.
Ok, mas o que os estimadores têm de tão bom assim? Podemos começar com o seguinte:
E como fazemos para treinar nosso modelo tf.keras simples para usar várias GPUs? Podemos usar o paradigma tf.contrib.distribute.MirroredStrategy, que faz replicação no gráfico com treinamento síncrono. Veja esta conversa no treinamento de Distributed TensorFlow para saber mais sobre essa estratégia.
Essencialmente, cada GPU de worker tem uma cópia da rede e recebe um subconjunto dos dados com os quais calcula os gradientes locais e, em seguida, espera que todos os workers terminem de maneira síncrona. Depois, os workers comunicam seus gradientes locais entre si com uma operação "Ring All-reduce" que, normalmente, é otimizada para reduzir a largura de banda da rede e aumentar a produtividade. Quando todos os gradientes chegarem, cada worker calculará a média deles e atualizará o seu parâmetro. A próxima etapa começará em seguida. Isso é ideal em casos com várias GPUs em um único nó conectado por alguma interconexão de alta velocidade.
Para usar essa estratégia, primeiro criamos um estimador no modelo tf.keras compilado e atribuímos a ele a configuração MirroredStrategy pelo RunConfig. Por padrão, essa configuração usará todas as GPUs, mas você também pode definir uma opção num_gpus para usar um número específico de GPUs:
NUM_GPUS = 2
strategy = tf.contrib.distribute.MirroredStrategy(num_gpus=NUM_GPUS)config = tf.estimator.RunConfig(train_distribute=strategy)
estimator = tf.keras.estimator.model_to_estimator(model, config=config)
Para canalizar os dados para os estimadores, precisamos configurar uma função de importação de dados que retorne um conjunto tf.data de lotes (imagens,rótulos) dos nossos dados. A função abaixo recebe matrizes "numpy" e retorna o conjunto dados por um processo de ETL.
Veja que, no fim, também chamamos o método "prefetch", que carrega os dados em buffer para as GPUs enquanto elas estão treinando, preparando o próximo lote e esperando pelas GPUs, em vez de fazer as GPUs esperarem os dados a cada iteração. Pode ser que a GPU ainda não seja totalmente utilizada, e, para melhorar isso, podemos usar versões combinadas das operações de transformação, como "shuffle_and_repeat", em vez de duas operações distintas, mas eu considerei apenas o caso mais simples.
def input_fn(images, labels, epochs, batch_size): # Convert the inputs to a Dataset. (E) ds = tf.data.Dataset.from_tensor_slices((images, labels))
# Shuffle, repeat, and batch the examples. (T) SHUFFLE_SIZE = 5000 ds = ds.shuffle(SHUFFLE_SIZE).repeat(epochs).batch(batch_size) ds = ds.prefetch(2)
# Return the dataset. (L) return ds
Primeiro, definiremos uma classe SessionRunHook para registrar os momentos de cada iteração do método do gradiente descendente estocástico:
class TimeHistory(tf.train.SessionRunHook): def begin(self): self.times = []
def before_run(self, run_context): self.iter_time_start = time.time()
def after_run(self, run_context, run_values): self.times.append(time.time() - self.iter_time_start)
Agora, chegamos na parte boa! Podemos chamar a função "train" do nosso estimador fornecendo a "input_fn" que definimos (com o tamanho do lote e o número de eras para as quais queremos treinar) e uma instância de TimeHistory por meio do argumento "hooks":
time_hist = TimeHistory()
BATCH_SIZE = 512EPOCHS = 5
estimator.train(lambda:input_fn(train_images, train_labels, epochs=EPOCHS, batch_size=BATCH_SIZE), hooks=[time_hist])
Graças ao nosso hook de temporização, agora podemos usá-lo para calcular o tempo total do treinamento, além da média de imagens que treinamos por segundo (a produtividade média):
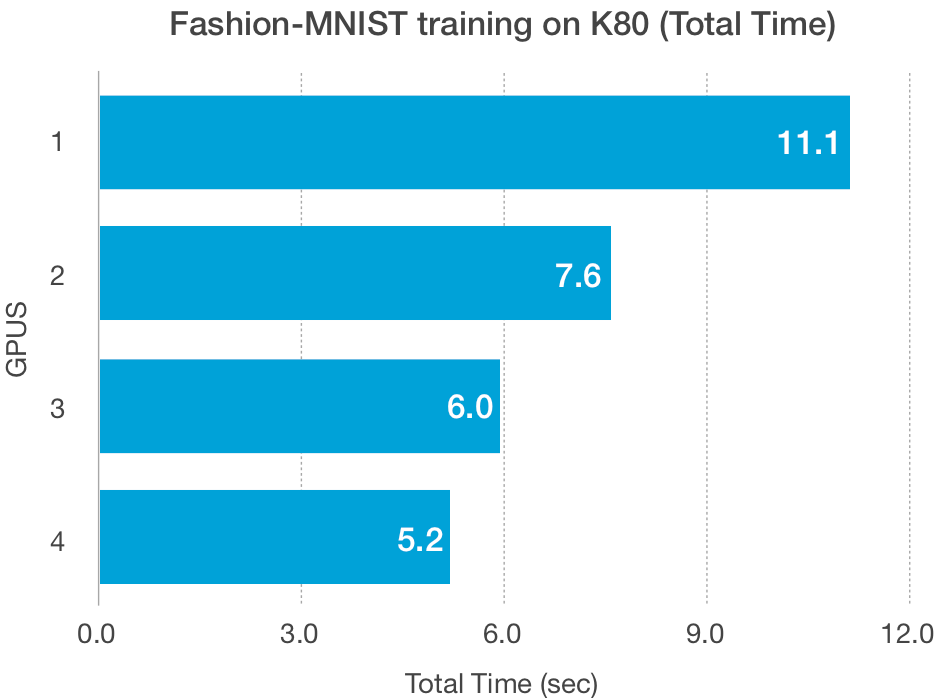
total_time = sum(time_hist.times)print(f"total time with {NUM_GPUS} GPU(s): {total_time} seconds")
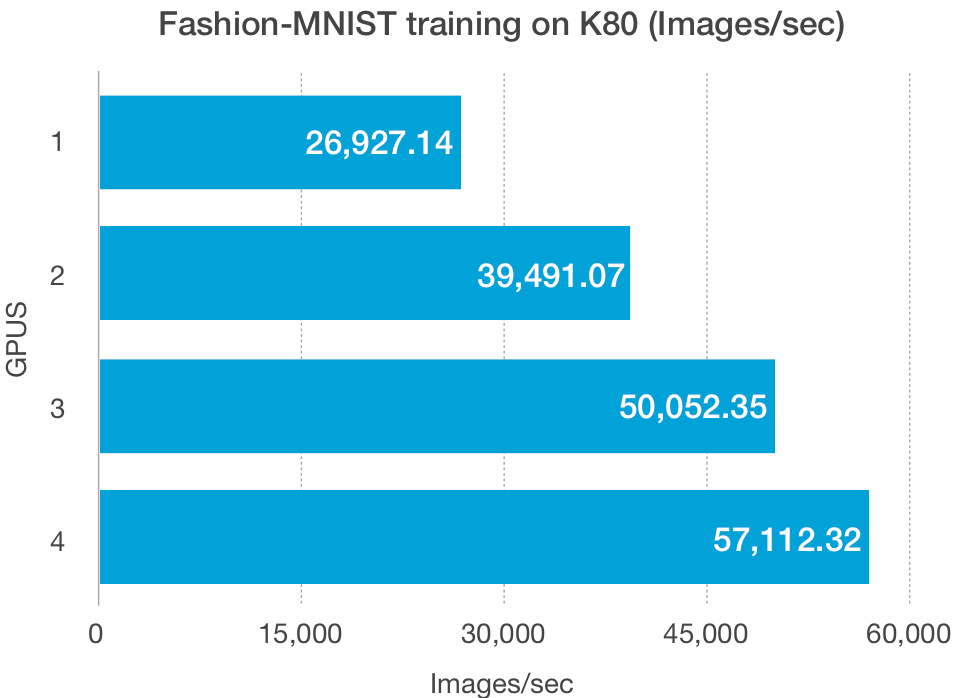
avg_time_per_batch = np.mean(time_hist.times)print(f"{BATCH_SIZE*NUM_GPUS/avg_time_per_batch} images/second with {NUM_GPUS} GPU(s)")
Para checar o desempenho do nosso modelo, chamamos o método "evaluate" no estimador:
estimator.evaluate(lambda:input_fn(test_images, test_labels, epochs=1, batch_size=BATCH_SIZE))
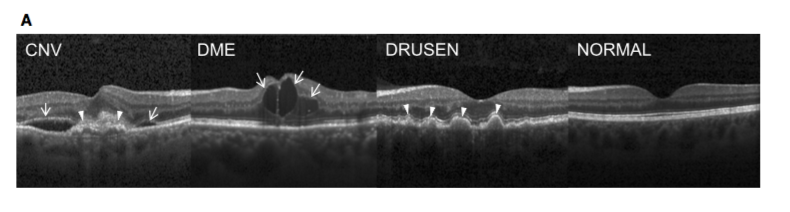
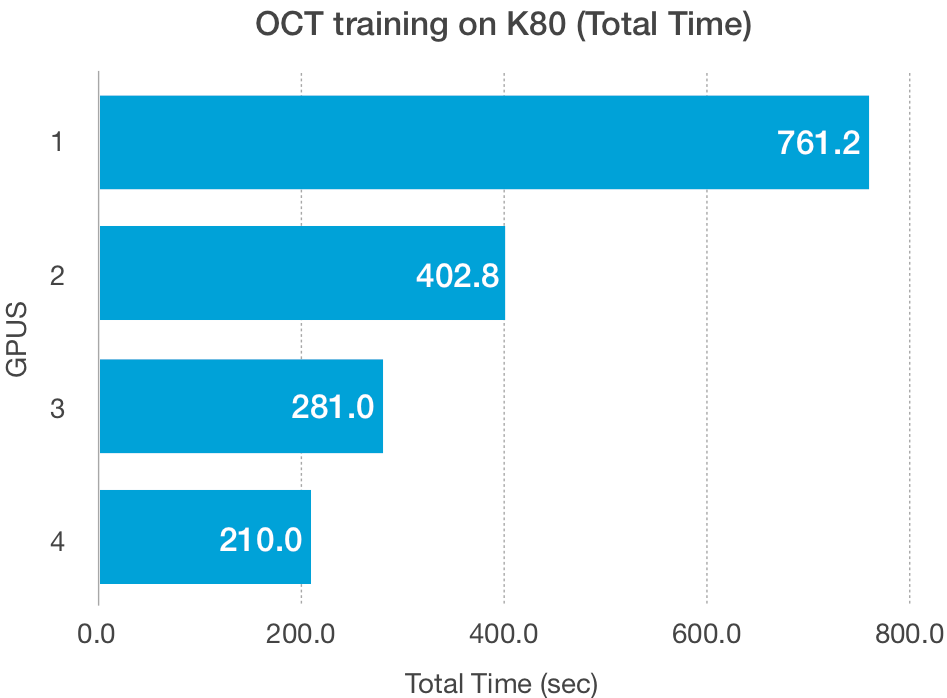
Para testar o desempenho de escalonamento em conjuntos de dados maiores, usamos as imagens de OCT retinais, um dos muitos conjuntos de dados grandes do Kaggle. Esse conjunto tem imagens de raios-X de cortes transversais de retinas de humanos vivos agrupadas em quatro categorias, NORMAL, CNV, DME e DRUSEN:
O conjunto de dados tem um total de 84.495 imagens de raios-X em JPEG, normalmente com 512 x 496 pixels, e pode ser baixado pelo CLI do kaggle:
#!pip install kaggle#!kaggle datasets download -d paultimothymooney/kermany2018
Depois de baixar o conjunto de treinamento e teste, as classes de imagem estarão em suas respectivas pastas. Definiremos um padrão da seguinte forma:
labels = ['CNV', 'DME', 'DRUSEN', 'NORMAL']
train_folder = os.path.join('OCT2017', 'train', '**', '*.jpeg')test_folder = os.path.join('OCT2017', 'test', '**', '*.jpeg')
Depois, criamos a função "input" do nosso estimador, que recebe qualquer padrão de arquivos e retorna imagens redimensionadas e rótulos codificados do tipo one-hot como um tf.data.Dataset. Desta vez, seguimos as práticas recomendadas do Guia de alto desempenho dos canais de entrada. Veja que se o "buffer_size" do prefetch for "None", o TensorFlow usará automaticamente um tamanho de buffer de pré-busca ideal:
Desta vez, usaremos um VGG16 pré-treinado e retreinaremos somente suas últimas 5 camadas para treinar este modelo:
keras_vgg16 = tf.keras.applications.VGG16(input_shape=(224,224,3), include_top=False)
output = keras_vgg16.outputoutput = tf.keras.layers.Flatten()(output)prediction = tf.keras.layers.Dense(len(labels), activation=tf.nn.softmax)(output)
model = tf.keras.Model(inputs=keras_vgg16.input, outputs=prediction)
for layer in keras_vgg16.layers[:-4]: layer.trainable = False
Agora, temos tudo o que precisamos e podemos prosseguir, como mencionado acima, e treinar o nosso modelo em alguns minutos usando NUM_GPUS GPUs:
model.compile(loss='categorical_crossentropy', optimizer=tf.train.AdamOptimizer(), metrics=['accuracy'])
NUM_GPUS = 2strategy = tf.contrib.distribute.MirroredStrategy(num_gpus=NUM_GPUS)config = tf.estimator.RunConfig(train_distribute=strategy)estimator = tf.keras.estimator.model_to_estimator(model, config=config)
BATCH_SIZE = 64EPOCHS = 1
estimator.train(input_fn=lambda:input_fn(train_folder, labels, shuffle=True, batch_size=BATCH_SIZE, buffer_size=2048, num_epochs=EPOCHS, prefetch_buffer_size=4), hooks=[time_hist])
Depois do treinamento, podemos avaliar a precisão no conjunto de teste, que deve ser de cerca de 95% (nada mau para um ponto de referência inicial 😀):
estimator.evaluate(input_fn=lambda:input_fn(test_folder, labels, shuffle=False, batch_size=BATCH_SIZE, buffer_size=1024, num_epochs=1))
Mostramos acima como é fácil treinar modelos Keras de aprendizado profundo com várias GPUs usando a API Estimators, como criar um canal de entrada que segue as práticas recomendadas para ter boa utilização de recursos (escalonamento linear) e como marcar o tempo da produtividade do treinamento com hooks.
É bom destacar que, no final, o ponto mais importante são os erros do conjunto de teste. Você pode notar que a precisão do conjunto de teste cai quando aumentamos o NUM_GPUS. Um dos motivos pode ser o fato de que MirroredStrategy realmente treina com um tamanho de lote de BATCH_SIZE*NUM_GPUS, o que pode exigir o ajuste de BATCH_SIZE ou da taxa de aprendizado quando se usa mais GPUs. Neste caso, separei todos os outros hiperparâmetros da constante NUM_GPUS para facilitar os traçados. No entanto, em um cenário real, será preciso ajustá-los.
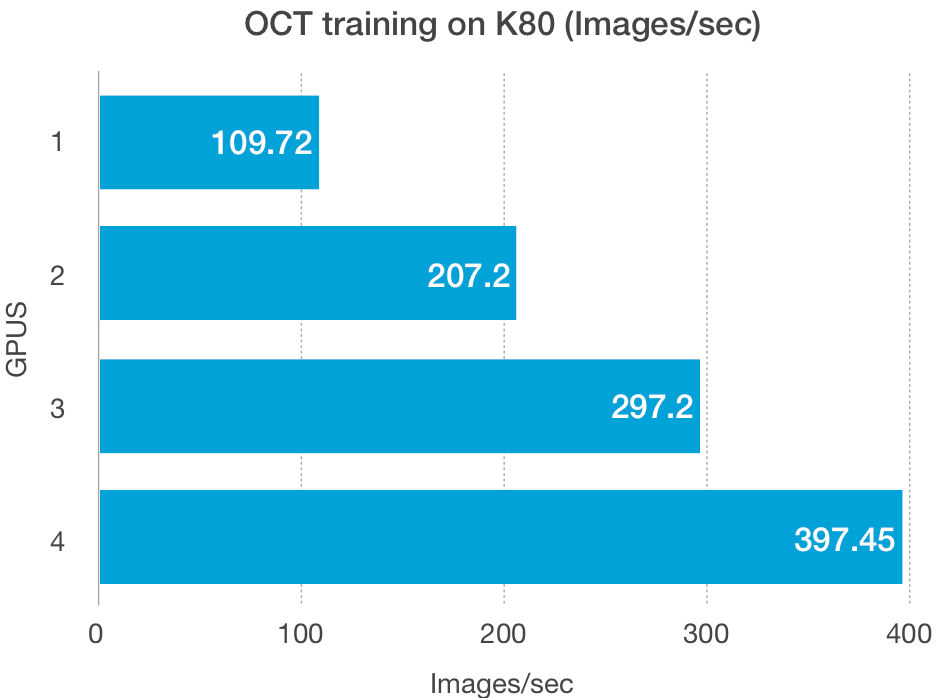
O tamanho do conjunto de dados, além do tamanho do modelo, afeta a capacidade de dimensionamento desses esquemas. As GPUs têm baixa largura de banda na leitura e gravação de dados de baixo volume, especialmente as GPUs mais antigas, como a K80, e podem ser responsáveis pelos traçados de Fashion-MNIST acima.
Quero agradecer à equipe do TensorFlow, especialmente a Josh Gordon, e a todos da Zalando Research pela ajuda na correção do rascunho, especialmente Duncan Blythe, Gokhan Yildirim e Sebastian Heinz.
Such A nice post... thanks For Sharing !! Now you can Send Valentine gifts To UK to your love one and spread the joy of this occassion.Flower delivery UK| Send Christmas Gifts To UK to your love one and spread the joy.
Can’t wait to read more from you. Apply for Ehsaas Program This was great!
Postar um comentário


2 comentários :
Such A nice post... thanks For Sharing !! Now you can Send Valentine gifts To UK to your love one and spread the joy of this occassion.Flower delivery UK| Send Christmas Gifts To UK to your love one and spread the joy.
Can’t wait to read more from you. Apply for Ehsaas Program This was great!
Postar um comentário