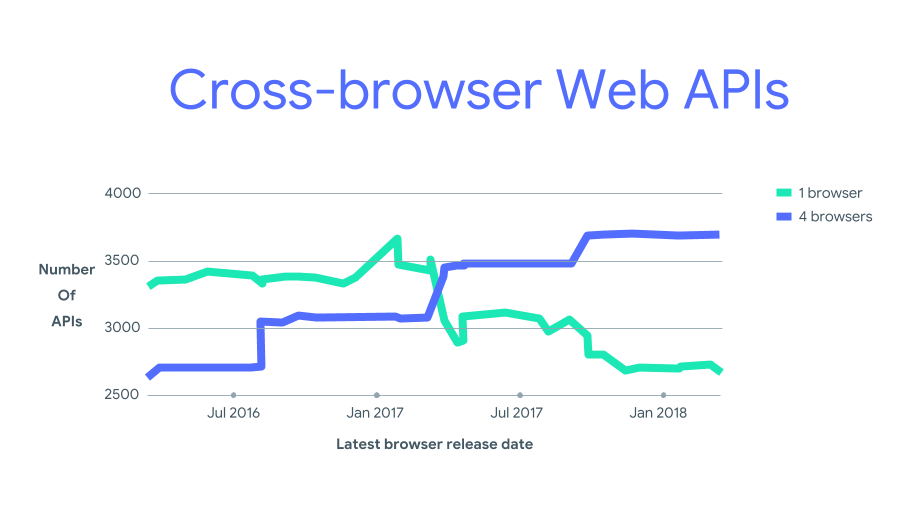
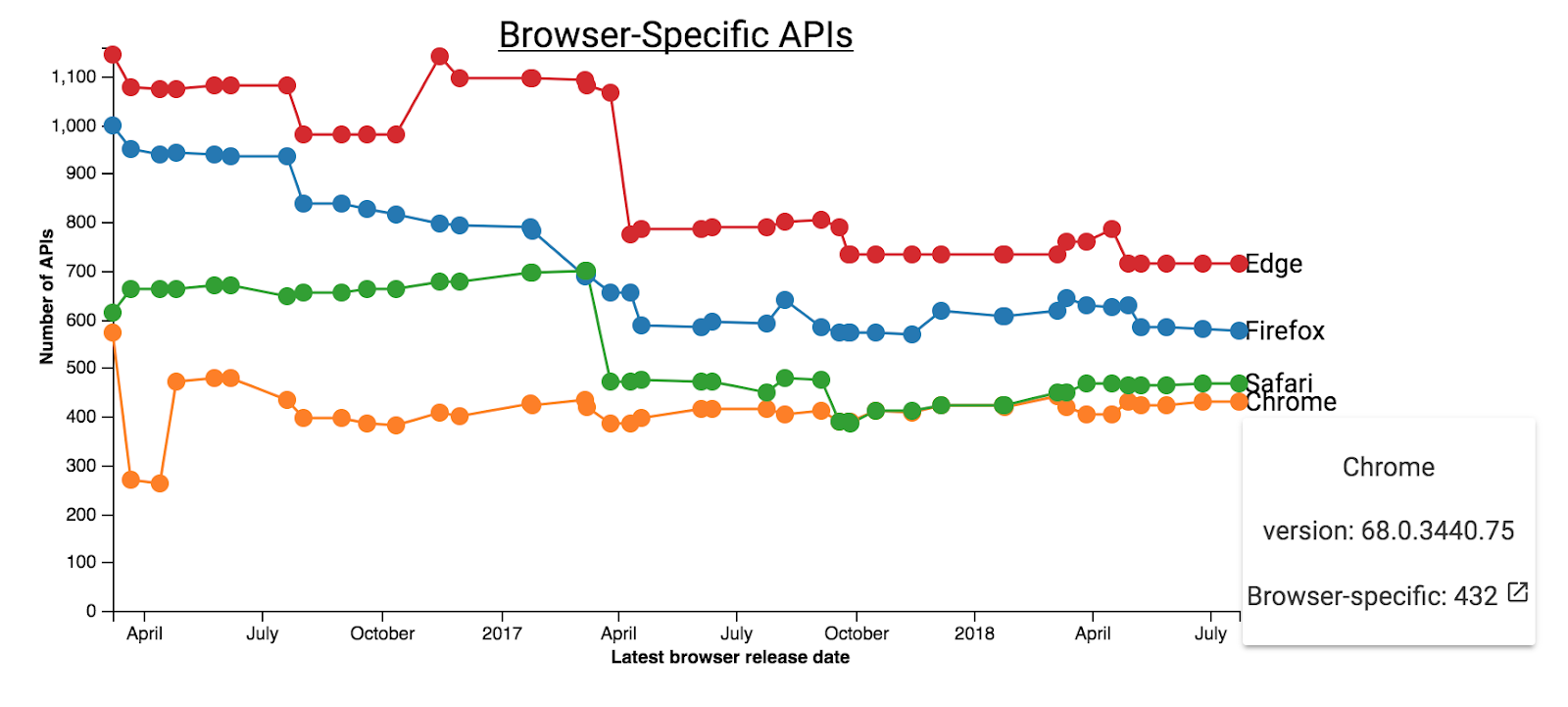
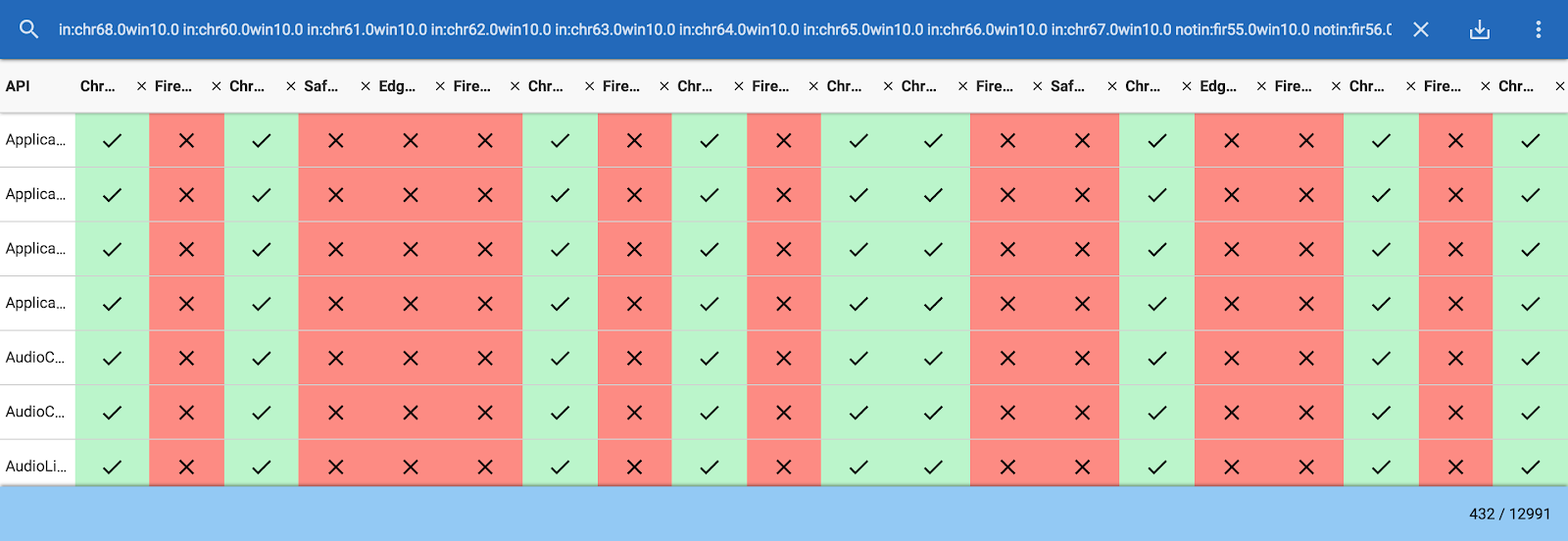
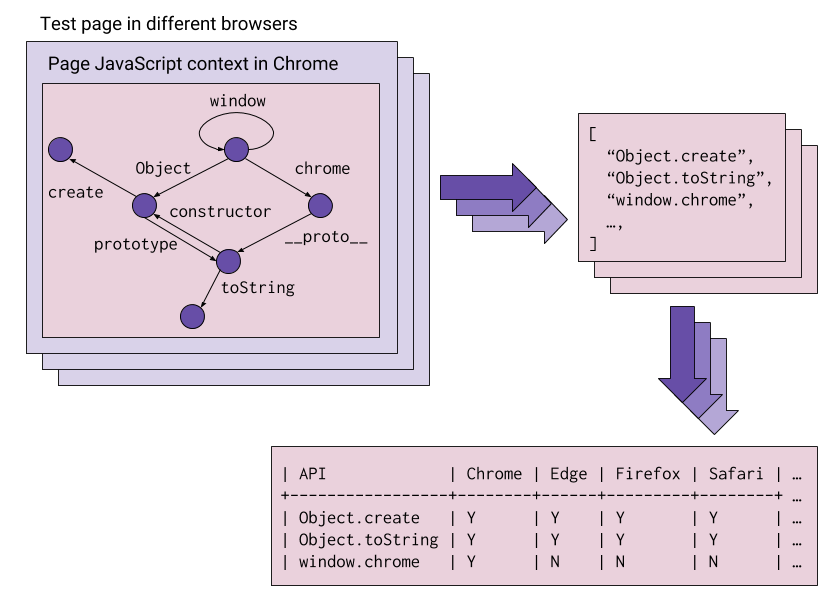
No Google I/O deste ano, lançamos o AndroidX Test, que é parte do Jetpack. Hoje, estamos felizes em anunciar o lançamento da versão v1.0.0 Final com a versão 4.0 do Robolectric. Como parte da versão 1.0.0, todo o AndroidX Test agora é de código aberto.
O AndroidX Test fornece APIs de teste comuns em todos os ambientes de teste, incluindo testes do Robolectric e de instrumentação. Ele inclui o suporte existente do Android JUnit 4, a biblioteca de interação da visualização do Espresso e várias novas e importantes APIs de teste. Essas APIs estão disponíveis para testes de instrumentação em dispositivos reais e virtuais. A partir do Robolectric 4.0, elas também estão disponíveis para testes locais da JVM.
Considere o seguinte caso de uso em que iniciamos a tela de login, inserimos um nome de usuário e uma senha válidos e somos direcionados para a tela inicial.
@RunWith(AndroidJUnit4::class)class LoginActivityTest {
@Test fun successfulLogin() { // GIVEN val scenario = ActivityScenario.launch(LoginActivity::class.java)
// WHEN onView(withId(R.id.user_name)).perform(typeText(“test_user”)) onView(withId(R.id.password)) .perform(typeText(“correct_password”)) onView(withId(R.id.button)).perform(click())
// THEN assertThat(getIntents().first()) .hasComponentClass(HomeActivity::class.java) }}
Vamos analisar o teste:
Esse teste pode ser executado em uma JVM local usando o Robolectric ou em qualquer dispositivo físico ou virtual.
Para executá-lo em um dispositivo Android, direcione o teste para a raiz de origem "androidTest" com as seguintes dependências:
androidTestImplementation(“androidx.test:runner:1.1.0”)androidTestImplementation(“androidx.test.ext:junit:1.0.0”)androidTestImplementation(“androidx.test.espresso:espresso-intents:3.1.0”)androidTestImplementation(“androidx.test.espresso:espresso-core:3.1.0”)androidTestImplementation(“androidx.test.ext:truth:1.0.0”)
A execução em um dispositivo físico ou virtual garante que seu código interaja com o sistema Android corretamente. No entanto, à medida que o número de casos de teste aumenta, você começa a sacrificar o tempo de execução do teste. É possível fazer apenas alguns testes maiores em um dispositivo real e, ao mesmo tempo, executar um grande número de testes unitários menores em um simulador, como o Robolectric, que pode executar testes mais rapidamente em uma JVM local.
Para executar os testes em uma JVM local usando o simulador do Robolectric, direcione o teste para a raiz de origem "teste" adicionando as seguintes linhas ao seu gradle.build:
testImplementation(“androidx.test:runner:1.1.0”)testImplementation(“androidx.test.ext:junit:1.0.0”)testImplementation(“androidx.test.espresso:espresso-intents:3.1.0”)testImplementation(“androidx.test.espresso:espresso-core:3.1.0”)testImplementation(“androidx.test.ext:truth:1.0.0”)testImplementation (“org.robolectric:robolectric:4.0”)
android { testOptions.unitTests.includeAndroidResources = true}
A unificação do teste de APIs entre simuladores e instrumentação traz muitas possibilidades interessantes. O Project Nitrogen, também anunciado no Google I/O, permitirá deslocar testes entre os ambientes de tempo de execução com facilidade. Isso significa que você poderá realizar testes escritos com base nas novas APIs do AndroidX Test e executá-los em uma JVM local, em um dispositivo real ou virtual, ou até mesmo em uma plataforma de testes baseada na nuvem como o Firebase Test Lab. Estamos muito animados com as oportunidades que isso proporcionará aos desenvolvedores, que poderão receber feedback rápido, preciso e acionável sobre a qualidade dos aplicativos.
Por fim, estamos felizes em anunciar que todos os componentes do AndroidX têm o código totalmente aberto. Estamos ansiosos para receber suas contribuições!
Documentação: https://developer.android.com/testing
Notas da versão:
Robolectric: https://github.com/robolectric/robolectric
AndroidX Test: https://github.com/android/android-test
Se há algo que não falta no campo da saúde e das ciências biológicas são dados. No entanto, esse campo poderia se beneficiar mais de análises fáceis de usar e econômicas, que façam sentido e possam ser usadas.
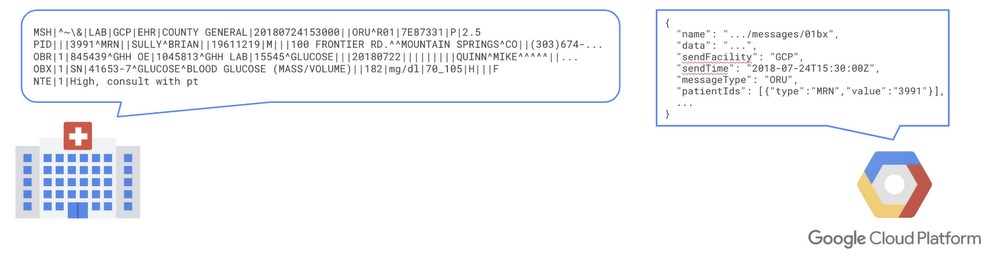
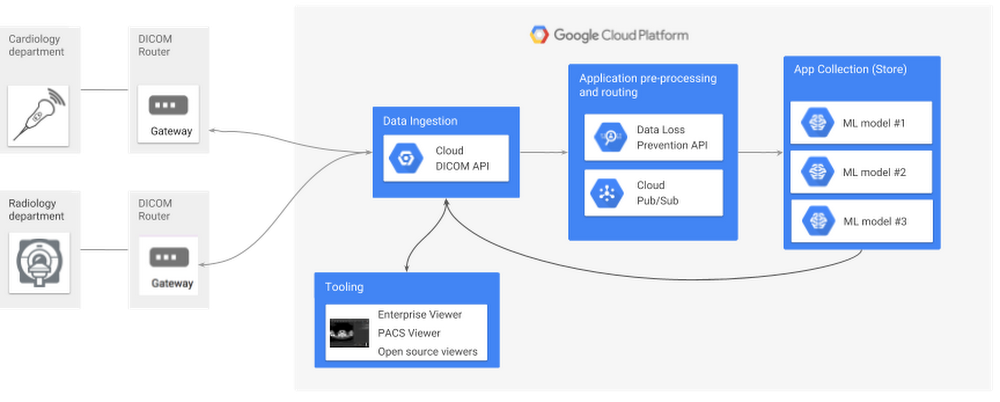
A equipe de saúde e ciências biológicas do Google Cloud recentemente apresentou um conjunto de interfaces de programação de aplicativo (APIs) e armazenamentos de dados que pode ser usado para viabilizar a análise de dados de saúde, aplicativos de aprendizado de máquina e integração dos sistemas de saúde em nível de dados, bem como a recuperação e o armazenamento seguros de vários tipos de dados eletrônicos relacionados a essa área. Hoje, iniciamos uma série de postagens do blog para demonstrar a Cloud Healthcare API. Neste primeiro artigo da série, apresentaremos uma breve visão geral da Cloud Healthcare API e os casos de uso revolucionários que ela permite. Além disso, as próximas edições fornecerão mais orientações sobre como implementar a API com segurança e apresentarão detalhes sobre como preencher lacunas entre os sistemas de saúde, os aplicativos da nuvem e os canais paciente/prestador.
A Cloud Healthcare API oferece uma solução gerenciada para armazenar e acessar dados de saúde no Google Cloud Platform (GCP), propiciando um elo fundamental entre os sistemas de saúde existentes e os aplicativos hospedados no Google Cloud. Com a API, é possível desbloquear novos recursos de análise de dados, aprendizado de máquina e desenvolvimento de aplicativos, bem como usar esses recursos para criar a próxima geração de soluções na área da saúde.
A API inclui três interfaces específicas a modalidades para implementar os principais padrões do setor para dados de saúde:
FHIR, um padrão emergente para a troca de dados de saúde
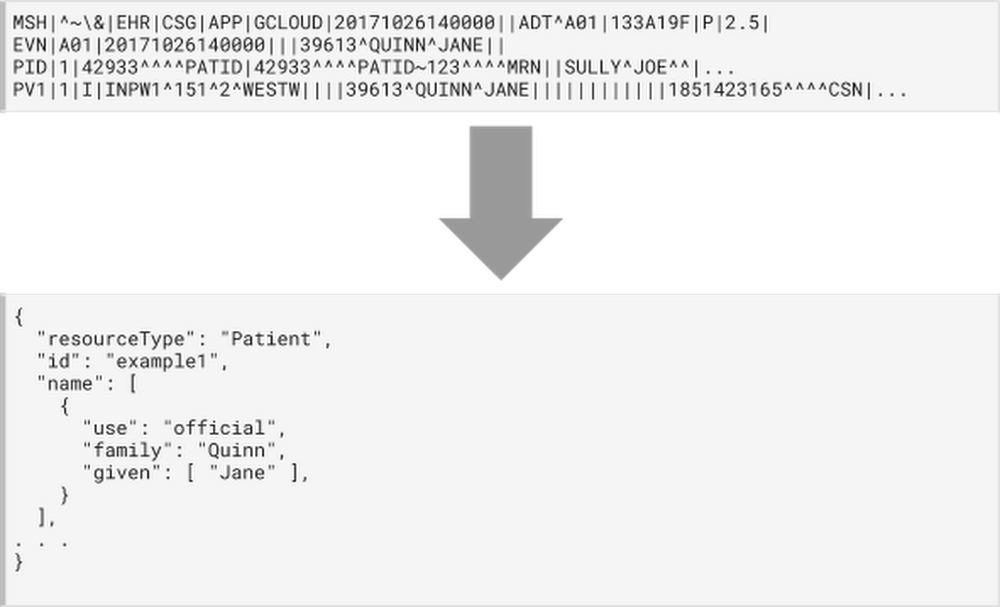
HL7v2, o método mais usado na integração de sistemas de saúde
DICOM, o padrão dominante em radiologia e áreas relacionadas a exames de imagem
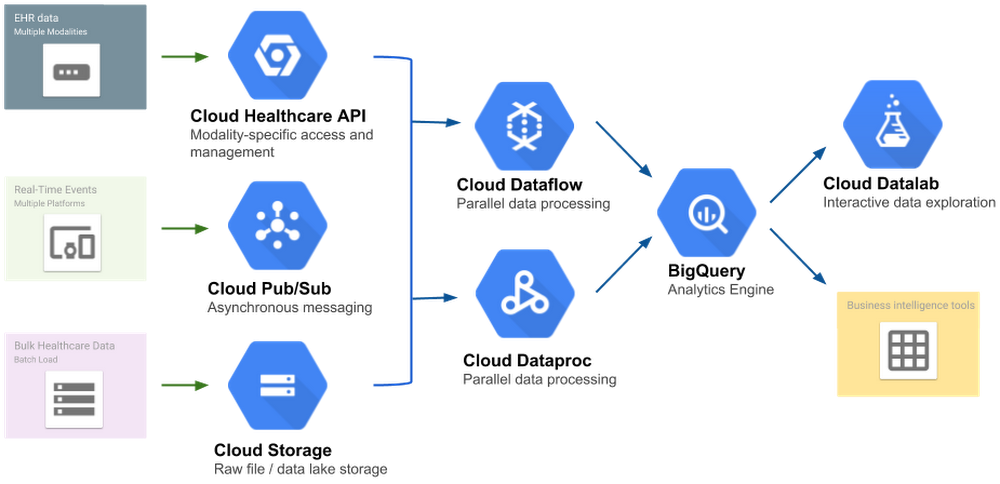
Cada interface é apoiada por um armazenamento de dados em conformidade com os padrões que oferece operações de leitura, gravação, pesquisa e outras funcionalidades com os dados. Além disso, esses armazenamentos de dados oferecem uma interface com o produto Publish-Subscribe (Cloud Pub/Sub) de alta capacidade do Google Cloud para oferecer um ponto e integração simples e seguro para os aplicativos. A integração Cloud Pub/Sub também pode ser usada para invocar transformações de dados no Cloud Dataflow, executar aplicativos sem servidor com o Cloud Functions, fazer streaming de dados para o conhecido mecanismo de análise BigQuery ou gerar previsões de resultado clínico pelo envio de dados para a plataforma de aprendizado de máquina Cloud ML Engine.
A Cloud Healthcare API oferece uma série de recursos importantes que são essenciais para associar tecnologias atuais com a próxima geração de aplicativos e sistemas de saúde:
Conformidade com padrões: o Google oferece suporte ao uso de interoperabilidade baseada em padrões, participando de vários órgãos de normalização da área da saúde. Na Cloud Healthcare API, cada armazenamento de dados específico à modalidade e a API associada substancialmente atendem aos padrões relevantes. Por exemplo, os armazenamentos de FHIR implementam a STU3, a versão atual da especificação FHIR. Os armazenamentos DICOM implementam o DICOMweb, um padrão baseado na Web para a troca de imagens médicas. Nas atualizações futuras, esperamos oferecer suporte a versões adicionais dessas especificações. Também esperamos oferecer a capacidade de solicitar um recurso em uma versão diferente da representação canônica.
Conformidade com normas de privacidade: o GCP apresenta orientações detalhadas sobre o suporte à conformidade com HIPAA nos EUA, PIPEDA no Canadá e outros padrões internacionais de privacidade em cloud.google.com/security/compliance.
Controle do local de dados: a Cloud Healthcare API trata os locais dos dados como um elemento fundamental da API. Há a opção de selecionar o local de armazenamento de cada conjunto de dados em uma lista de locais atualmente disponíveis que correspondem a áreas geográficas distintas alinhadas à estrutura regional do GCP. As regiões futuras do GCP permitirão distribuir o armazenamento para mais áreas geográficas.
Segurança: o modelo de segurança da Cloud Healthcare API tem como base o consolidado sistema de Gerenciamento de identidade e acesso (IAM) do Google. As permissões refinadas do IAM oferecem controle total sobre o acesso aos dados de saúde. Além disso, criamos proxies de código aberto para o sistema eficaz de gerenciamento de APIs da Apigee, que oferece recursos abrangentes de detecção de ameaças e gerenciamento de tráfego para permitir a exposição segura de ePHI confidenciais com aplicativos de paciente e prestador.
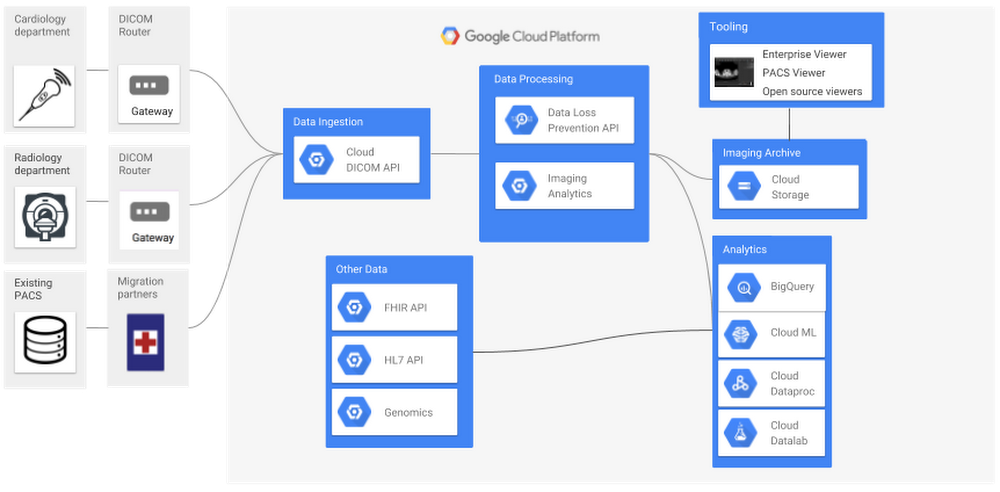
Importação e exportação em massa: as modalidades DICOM e FHIR da Cloud Healthcare API oferecem suporte a importação e exportação em massa de dados, facilitando ainda mais a transferência deles pelo sistema Cloud Storage.
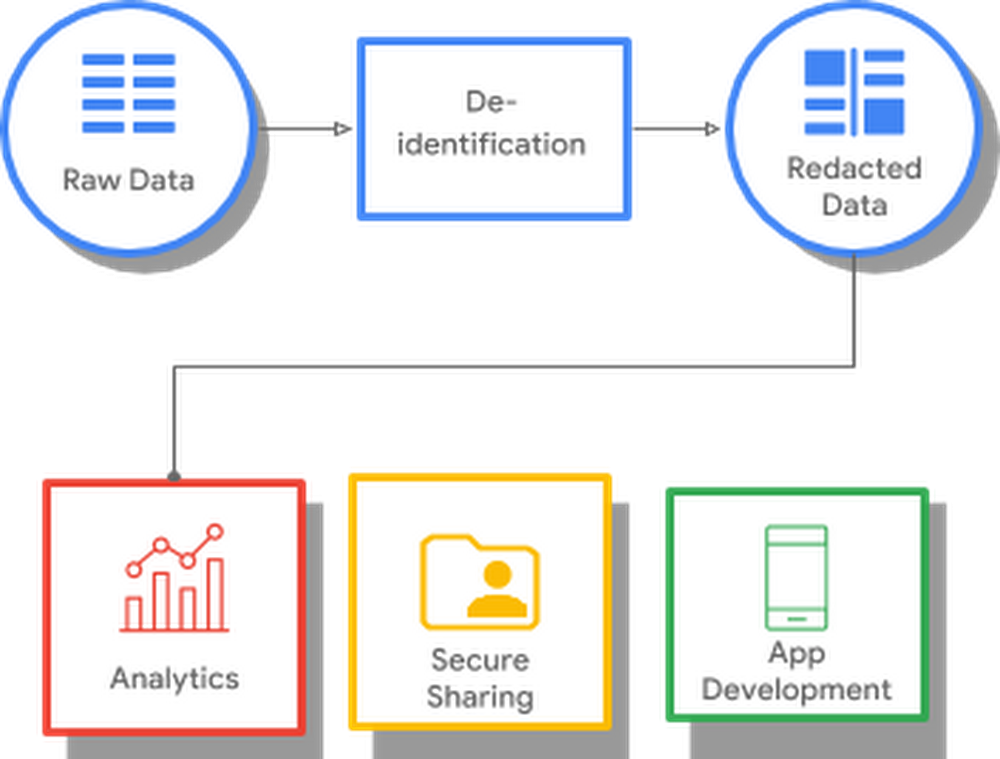
Desvinculação de identidade: há suporte para o processo de remoção de identificação pessoal (de-identification) em DICOM, o que simplifica a edição das informações dos pacientes em estudos de pesquisa e para outras finalidades. Esse processo funciona no armazenamento de dados.
Possibilidade de auditoria: é possível fazer auditoria das solicitações de acesso administrativo e a dados na Cloud Healthcare API. Os registros estão disponíveis no sistema de monitoramento híbrido Stackdriver do Google Cloud.
Alta disponibilidade: disponibilidade para cenários críticos são possibilitados pela infraestrutura robusta e altamente redundante do Google Cloud.
Para muitos aplicativos, a Cloud Healthcare API pode oferecer uma alternativa moderna às pilhas legadas que implementam os padrões DICOM, HL7v2 ou FHIR STU3, simplificando a integração de dados com sistemas existentes e permitindo que os desenvolvedores de aplicativos se concentrem nos próprios recursos diferenciados, como UX e inteligência.
A Cloud Healthcare API viabiliza uma ampla variedade de recursos, desde casos de uso administrativos e clínicos até de pesquisa. Abaixo são descritos alguns exemplos comuns de cada modalidade.
A Cloud Healthcare HL7v2 API permite a integração com os sistemas atuais de prontuário eletrônico do paciente ou com mecanismos de integração, como NextGen Connect, Cloverleaf e outros. Ela também inclui um adaptador de código aberto para o protocolo mínimo de camada inferior (MLLP, na sigla em inglês) HL7, que pode ser hospedado em um sistema PEP ou mecanismo de integração para proporcionar maior segurança. Esse adaptador se comunica com a Cloud Healthcare HL7v2 API por HTTPS, encapsulando a mensagem HL7v2 em uma chamada de API. Os arquitetos de integração também podem optar por chamar a API diretamente, se quiserem.
Os dados recebidos pela HL7v2 API são armazenados no GCP e podem ser acessados somente por aplicativos autorizados. Quando dados novos ou atualizados são recebidos, as notificações podem ser enviadas a aplicativos pelo Cloud Pub/Sub. Isso permite a fácil integração com uma pilha completa de análise de mensagem HL7v2, personalizada de acordo com tipos e conteúdo específicos de mensagem.
Os dados HL7v2 recebidos pela Cloud Healthcare API (ou importados em lote no Google Cloud Storage) podem ser disponibilizados imediatamente para a lógica específica a clientes que aproveita os serviços do GCP, como o Cloud Dataflow, para transformar as mensagens em um formato FHIR padronizado. Além de converter o formato básico em FHIR, essa conversão também pode incluir conversões do sistema de codificação, extração e classificação de conteúdo importante nas anotações clínicas, bem como outros processos. Dados recentemente convertidos podem ser armazenados e disponibilizados para aplicativos pela Cloud Healthcare FHIR API, encaminhados para o BigQuery para análises mais detalhadas ou processados pelos modelos da TensorFlow pelo Cloud ML Engine.
Assim que os dados forem convertidos em um formato padrão, como o FHIR ou o modelo de dados comuns OMOP, eles podem ser usados no BigQuery para produzir insights sobre questões administrativas, clínicas e de pesquisa. Por exemplo, é fácil fazer análises e gerar relatórios em grande escala das estatísticas de reinternação em hospitais por unidade, doença, médico ou outras dimensões com o suporte de SQL do BigQuery. Além disso, o BigQuery oferece suporte a uma série de ferramentas conhecidas de geração de relatórios e visualização para ajudar a obter insights personalizados sobre os dados.
A capacidade de aplicar aprendizado de máquina aos dados de pacientes para identificar rapidamente possíveis diagnósticos é um desenvolvimento inovador. Por exemplo, as imagens de radiologia e de luz natural DICOM armazenadas nos conjuntos de dados da Cloud Healthcare API podem ser usadas para treinar modelos avançados de aprendizado de máquina da TensorFlow. Esses modelos treinados, por sua vez, podem ser executados no Google Cloud ML para analisar grandes volumes de dados ingeridos pelas instâncias de produção da Cloud Healthcare API. As previsões geradas por esses modelos de aprendizado de máquina podem ser armazenadas diretamente nas próprias imagens DICOM, permitindo que radiologistas aproveitem essa análise no contexto dos fluxos de trabalho existentes. Essas análises de alto volume ajudam médicos a realizar uma verificação avançada e consistente para confirmar a presença de doenças comuns. As anomalias detectadas podem ser validadas por médicos especialistas, e o tratamento pode ser iniciado rapidamente se problemas forem identificados.
Da mesma forma, o uso do aprendizado de máquina para aproveitar grandes volumes de dados para prever resultados clínicos está ajudando médicos a identificar populações que estão em risco de resultados adversos. Assim, é possível intervir cedo o suficiente para influenciar o resultado. Isso representa um potencial significativo de redução nas reinternações hospitalares, por exemplo, ou de identificação dos padrões de tratamento que precisam ser reavaliados.
Estudos radiológicos no formato de imagem DICOM podem ser armazenados na Cloud Healthcare DICOM API, onde podem ser recuperados e pesquisados pelos aplicativos. Os metadados do estudo DICOM podem ser extraídos, combinados com outros dados clínicos e disponibilizados no BigQuery, acrescentando uma nova dimensão à análise clínica.
A desvinculação (edição ou transformação) de identidade dos elementos de dados confidenciais costuma ser uma etapa importante no pré-processamento de dados de saúde. Esse processo é necessário para disponibilizar os dados para análise, modelos de aprendizado de máquina e outros casos de uso. A Cloud Healthcare API oferece recursos de desvinculação de identidade dos dados armazenados no serviço, facilitando a análise de pesquisadores ou do aprendizado de máquina para verificações avançadas de anomalias.
Na próxima edição da série, compartilharemos muito mais detalhes sobre os conceitos da Cloud Healthcare API e explicaremos como fazer uma implementação básica. Acompanhe este espaço para saber mais informações sobre como usar a Cloud Healthcare API, aproveitar ainda mais os dados de saúde e oferecer novos aplicativos de saúde inovadores.
Postado por Matt Henderson, gerente de produtos do Google Play
Hoje, estamos dando o pontapé inicial no Playtime, nossa série anual de eventos mundiais que vai receber mais de 800 participantes, em Berlim e São Francisco, para compartilhar insights de especialistas de todo o mundo e mostrar as últimas atualizações dos nossos produtos. Essa série será seguida de eventos em São Paulo, Singapura, Taipei, Seul e Tóquio.
No Google Play, continuamos investindo em ferramentas que facilitem o desenvolvimento e a distribuição de aplicativos a um público global. Listamos abaixo algumas das atualizações mais incríveis que estamos anunciando hoje:
O Android App Bundle é o novo formato de publicação do Android, com o qual você pode criar uma experiência incrível com mais facilidade em um aplicativo menor. Aplicativos menores têm maior taxa de conversão. Nossas pesquisas de usuários mostram que o tamanho do aplicativo é o principal motivo das desinstalações. Com a modularização do Android App Bundle, você também pode oferecer recursos sob demanda em vez de no momento da instalação, reduzindo ainda mais o tamanho do aplicativo.
Milhares de pacotes de aplicativo já estão em produção com uma redução de tamanho média de 35%. Hoje, estamos anunciando atualizações que oferecem mais motivos para você migrar para o nosso pacote.
Para saber mais sobre o Android App Bundle, recursos dinâmicos e todos os benefícios que você ganha criando um aplicativo menor e modular, leia nosso artigo no Medium.
Ouvimos sempre o seu feedback para facilitar a criação de aplicativos instantâneos. Aumentamos recentemente o limite de tamanho para 10 MB para permitir o recurso "EXPERIMENTE AGORA" da Play Store e removemos a exigência de URL. Para os desenvolvedores de jogos, fizemos uma parceria com o Unity para criar um plug-in do Google Play Instant e incorporamos instantâneos diretamente no novo Cocos Creator.
Agora, estamos usando o Android App Bundle para resolver um dos principais problemas na criação de aplicativos instantâneos. Antes, era preciso publicar um aplicativo instantâneo e um aplicativo instalável. Com o Android Studio 3.2, era possível publicar pacotes com a característica instantânea, mas ainda era obrigatório publicar um pacote de aplicativo principal.
Agora, você pode esquecer essa história de manter códigos distintos. Com a versão beta do Android Studio 3.3, o desenvolvedor pode publicar um único pacote de aplicativo e classificar o pacote, ou um módulo específico, como instantâneo. O pacote de aplicativo unificado é o futuro das experiências instantâneas nos aplicativos. Esperamos que você experimente esse novo recurso.
O Google Play Instant já está disponível para títulos premium e em campanhas de pré-cadastro. Assim, as pessoas podem experimentar o jogo antes do lançamento, gerando expectativa adicional. Todos os dias, o Google Play Instant recebe novos jogos e aplicativos. Estamos entusiasmados por receber o Umiro, da Devolver Digital, e o Looney Tunes World of Mayhem, da Scopely, como alguns dos primeiros a aproveitar os benefícios desses novos recursos.
O Play Console oferece duas ferramentas para ajudar você a monitorar o desempenho e aumentar a qualidade dos aplicativos. O relatório pré-lançamento executa os aplicativos em dispositivos reais presentes no Firebase Test Lab e gera metadados úteis para ajudar a identificar e corrigir problemas antes que os aplicativos passem para o ambiente de produção. O Android Vitals ajuda a monitorar o desempenho e a qualidade dos aplicativos em dispositivos de usuários do mundo real.
Agora, estamos juntando os dois para oferecer insights mais relevantes e objetivos. Sempre que uma falha do mudo real ocorrer no Android Vitals e também durante a execução de um relatório pré-lançamento, você obterá todos os metadados extras do relatório pré-lançamento no painel do Android Vitals para aumentar a eficácia da depuração. Isso funciona nos dois sentidos. Portanto, se uma falha que já acontece no mundo real ocorrer nos relatórios pré-lançamento, você poderá ver o impacto atual no Android Vitals, o que ajudará você a priorizar os problemas destacados pelos relatórios pré-lançamento.
Fizemos muitas mudanças para facilitar o gerenciamento de aplicativos e do negócio como um todo no Play.
Estamos muito empolgados com o lançamento do Academy for App Success, que contém novos cursos interativos para ajudar os desenvolvedores a aproveitarem tudo o que o Play Console tem a oferecer, entender políticas do Play e utilizar as práticas recomendadas para aumentar a qualidade e melhorar o desempenho do negócio. Esse novo programa é gratuito e permite monitorar o progresso do aprendizado com testes e comprovações de habilidades para demonstrar o seu conhecimento. No momento, o programa está disponível apenas em inglês. Novo conteúdo e cursos traduzidos serão adicionados em breve.
Esta postagem foi útil para você? Avalie!
★ ★ ★ ★ ★
Na Zalando Research, assim como na maioria dos departamentos de pesquisa de IA, sabemos da importância da agilidade nos testes e na criação de protótipos. Com os conjuntos de dados ficando cada vez maiores, é bom saber como treinar modelos de aprendizado profundo com velocidade e eficiência usando os recursos compartilhados disponíveis.
A API Estimators do TensorFlow é útil para treinar modelos em ambientes distribuídos com várias GPUs. Aqui, apresentaremos esse fluxo de trabalho treinando um estimador personalizado criado com tf.keras para o pequeno conjunto de dados Fashion-MNIST. Depois mostraremos um caso de uso mais prático.
Nota: a equipe do TensorFlow também está trabalhando em um recurso novo e incrível (no momento da criação deste artigo, ainda está na fase de master) que permite treinar um modelo tf.keras sem precisar transformá-lo em um estimador, usando apenas algumas poucas linhas de código a mais. Esse fluxo de trabalho também é ótimo. Abaixo, nos limitaremos à Estimators API. Escolha o que for melhor para você.
TL;DR: na essência, o que queremos lembrar é que um tf.keras.Model pode ser treinado com a API tf.estimator convertendo-o em um objeto tf.estimator.Estimator pelo método tf.keras.estimator.model_to_estimator. Depois da conversão, podemos aplicar as ferramentas que o Estimators oferece para treinar em diferentes configurações de hardware.
Você pode baixar o código desta postagem neste bloco de anotações e executá-lo por conta própria.
import osimport time
#!pip install -q -U tensorflow-gpuimport tensorflow as tf
import numpy as np
Usaremos o conjunto de dados Fashion-MNIST, uma substituição direta do MNIST, que contém milhares de imagens em escala de cinza dos artigos de moda da Zalando. Obter os dados de treinamento e teste é bem simples:
(train_images, train_labels), (test_images, test_labels) = tf.keras.datasets.fashion_mnist.load_data()
Queremos converter os valores de pixels dessas imagens de um número entre 0 e 255 em um número entre 0 e 1 e converter o conjunto de dados para o formato [B,H,W,C], onde "B" é o número de imagens do lote, "H" e "W" são a altura e o comprimento, e "C" é o número de canais (1 para escala de cinza) do nosso conjunto:
TRAINING_SIZE = len(train_images)TEST_SIZE = len(test_images)
train_images = np.asarray(train_images, dtype=np.float32) / 255# Convert the train images and add channelstrain_images = train_images.reshape((TRAINING_SIZE, 28, 28, 1))
test_images = np.asarray(test_images, dtype=np.float32) / 255# Convert the test images and add channelstest_images = test_images.reshape((TEST_SIZE, 28, 28, 1))
Depois, precisamos converter os rótulos de um ID de número inteiro (por exemplo, 2 ou suéter) para uma codificação tipo one-hot (por exemplo, 0,0,1,0,0,0,0,0,0,0). Para fazer isso, usaremos a função tf.keras.utils.to_categorical:
# How many categories we are predicting from (0-9)LABEL_DIMENSIONS = 10
train_labels = tf.keras.utils.to_categorical(train_labels, LABEL_DIMENSIONS)
test_labels = tf.keras.utils.to_categorical(test_labels, LABEL_DIMENSIONS)
# Cast the labels to floats, needed latertrain_labels = train_labels.astype(np.float32)test_labels = test_labels.astype(np.float32)
Criaremos nossa rede neural usando a API Keras Functional. O Keras é uma API de alto nível para criar e treinar modelos de aprendizado profundo que é intuitiva, modular e fácil de ampliar. O tf.keras é a implementação do TensorFlow para essa API e oferece suporte a recursos como execução antecipada, canais tf.data e estimadores.
Para a arquitetura, usaremos os ConvNets. Em um nível bem resumido, os ConvNets são pilhas de camadas convolucionais (Conv2D) e camadas de agrupamento, ou pooling (MaxPooling2D). Mas o mais importante é que, para cada exemplo de treinamento, eles recebem tensores 3D de formato (altura, largura e canais). No caso de imagens em escala de cinza, começam com channels=1 e retornam um tensor 3D.
Portanto, depois da parte do ConvNet, precisaremos nivelar (Flatten) o tensor e adicionar camadas de densidade (Dense) em que a última retorna um vetor de tamanho LABEL_DIMENSIONS com a ativação de tf.nn.softmax:
inputs = tf.keras.Input(shape=(28,28,1)) # Returns a placeholder
x = tf.keras.layers.Conv2D(filters=32, kernel_size=(3, 3), activation=tf.nn.relu)(inputs)
x = tf.keras.layers.MaxPooling2D(pool_size=(2, 2), strides=2)(x)
x = tf.keras.layers.Conv2D(filters=64, kernel_size=(3, 3), activation=tf.nn.relu)(x)
x = tf.keras.layers.Flatten()(x)
x = tf.keras.layers.Dense(64, activation=tf.nn.relu)(x)predictions = tf.keras.layers.Dense(LABEL_DIMENSIONS, activation=tf.nn.softmax)(x)
Agora, podemos definir o nosso modelo, selecionar o otimizador (escolhemos um do TensorFlow, e não do tf.keras.optimizers) e compilá-lo:
model = tf.keras.Model(inputs=inputs, outputs=predictions)
optimizer = tf.train.AdamOptimizer(learning_rate=0.001)
model.compile(loss='categorical_crossentropy', optimizer=optimizer, metrics=['accuracy'])
Para criar um estimador no modelo Keras compilado, chamamos o método model_to_estimator. Veja que o estado inicial do modelo Keras é preservado no estimador criado.
Ok, mas o que os estimadores têm de tão bom assim? Podemos começar com o seguinte:
E como fazemos para treinar nosso modelo tf.keras simples para usar várias GPUs? Podemos usar o paradigma tf.contrib.distribute.MirroredStrategy, que faz replicação no gráfico com treinamento síncrono. Veja esta conversa no treinamento de Distributed TensorFlow para saber mais sobre essa estratégia.
Essencialmente, cada GPU de worker tem uma cópia da rede e recebe um subconjunto dos dados com os quais calcula os gradientes locais e, em seguida, espera que todos os workers terminem de maneira síncrona. Depois, os workers comunicam seus gradientes locais entre si com uma operação "Ring All-reduce" que, normalmente, é otimizada para reduzir a largura de banda da rede e aumentar a produtividade. Quando todos os gradientes chegarem, cada worker calculará a média deles e atualizará o seu parâmetro. A próxima etapa começará em seguida. Isso é ideal em casos com várias GPUs em um único nó conectado por alguma interconexão de alta velocidade.
Para usar essa estratégia, primeiro criamos um estimador no modelo tf.keras compilado e atribuímos a ele a configuração MirroredStrategy pelo RunConfig. Por padrão, essa configuração usará todas as GPUs, mas você também pode definir uma opção num_gpus para usar um número específico de GPUs:
NUM_GPUS = 2
strategy = tf.contrib.distribute.MirroredStrategy(num_gpus=NUM_GPUS)config = tf.estimator.RunConfig(train_distribute=strategy)
estimator = tf.keras.estimator.model_to_estimator(model, config=config)
Para canalizar os dados para os estimadores, precisamos configurar uma função de importação de dados que retorne um conjunto tf.data de lotes (imagens,rótulos) dos nossos dados. A função abaixo recebe matrizes "numpy" e retorna o conjunto dados por um processo de ETL.
Veja que, no fim, também chamamos o método "prefetch", que carrega os dados em buffer para as GPUs enquanto elas estão treinando, preparando o próximo lote e esperando pelas GPUs, em vez de fazer as GPUs esperarem os dados a cada iteração. Pode ser que a GPU ainda não seja totalmente utilizada, e, para melhorar isso, podemos usar versões combinadas das operações de transformação, como "shuffle_and_repeat", em vez de duas operações distintas, mas eu considerei apenas o caso mais simples.
def input_fn(images, labels, epochs, batch_size): # Convert the inputs to a Dataset. (E) ds = tf.data.Dataset.from_tensor_slices((images, labels))
# Shuffle, repeat, and batch the examples. (T) SHUFFLE_SIZE = 5000 ds = ds.shuffle(SHUFFLE_SIZE).repeat(epochs).batch(batch_size) ds = ds.prefetch(2)
# Return the dataset. (L) return ds
Primeiro, definiremos uma classe SessionRunHook para registrar os momentos de cada iteração do método do gradiente descendente estocástico:
class TimeHistory(tf.train.SessionRunHook): def begin(self): self.times = []
def before_run(self, run_context): self.iter_time_start = time.time()
def after_run(self, run_context, run_values): self.times.append(time.time() - self.iter_time_start)
Agora, chegamos na parte boa! Podemos chamar a função "train" do nosso estimador fornecendo a "input_fn" que definimos (com o tamanho do lote e o número de eras para as quais queremos treinar) e uma instância de TimeHistory por meio do argumento "hooks":
time_hist = TimeHistory()
BATCH_SIZE = 512EPOCHS = 5
estimator.train(lambda:input_fn(train_images, train_labels, epochs=EPOCHS, batch_size=BATCH_SIZE), hooks=[time_hist])
Graças ao nosso hook de temporização, agora podemos usá-lo para calcular o tempo total do treinamento, além da média de imagens que treinamos por segundo (a produtividade média):
total_time = sum(time_hist.times)print(f"total time with {NUM_GPUS} GPU(s): {total_time} seconds")
avg_time_per_batch = np.mean(time_hist.times)print(f"{BATCH_SIZE*NUM_GPUS/avg_time_per_batch} images/second with {NUM_GPUS} GPU(s)")
Para checar o desempenho do nosso modelo, chamamos o método "evaluate" no estimador:
estimator.evaluate(lambda:input_fn(test_images, test_labels, epochs=1, batch_size=BATCH_SIZE))
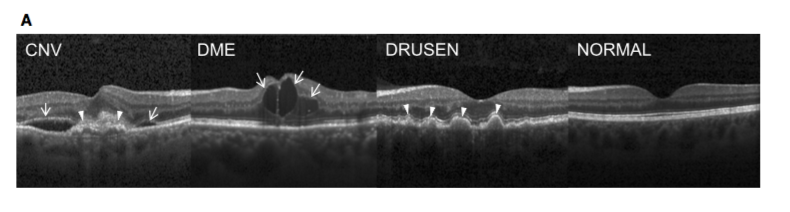
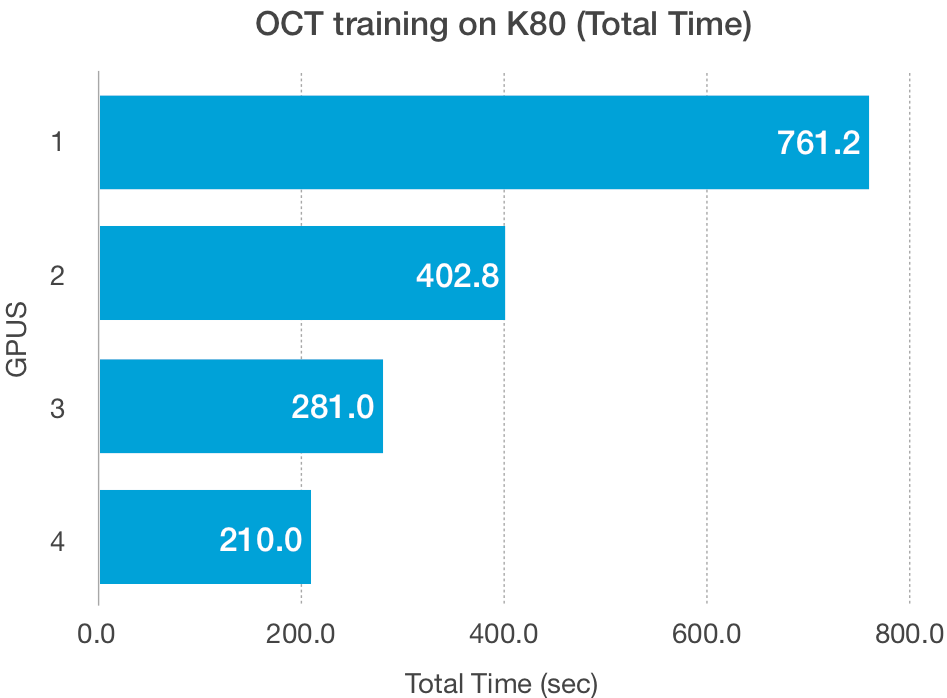
Para testar o desempenho de escalonamento em conjuntos de dados maiores, usamos as imagens de OCT retinais, um dos muitos conjuntos de dados grandes do Kaggle. Esse conjunto tem imagens de raios-X de cortes transversais de retinas de humanos vivos agrupadas em quatro categorias, NORMAL, CNV, DME e DRUSEN:
O conjunto de dados tem um total de 84.495 imagens de raios-X em JPEG, normalmente com 512 x 496 pixels, e pode ser baixado pelo CLI do kaggle:
#!pip install kaggle#!kaggle datasets download -d paultimothymooney/kermany2018
Depois de baixar o conjunto de treinamento e teste, as classes de imagem estarão em suas respectivas pastas. Definiremos um padrão da seguinte forma:
labels = ['CNV', 'DME', 'DRUSEN', 'NORMAL']
train_folder = os.path.join('OCT2017', 'train', '**', '*.jpeg')test_folder = os.path.join('OCT2017', 'test', '**', '*.jpeg')
Depois, criamos a função "input" do nosso estimador, que recebe qualquer padrão de arquivos e retorna imagens redimensionadas e rótulos codificados do tipo one-hot como um tf.data.Dataset. Desta vez, seguimos as práticas recomendadas do Guia de alto desempenho dos canais de entrada. Veja que se o "buffer_size" do prefetch for "None", o TensorFlow usará automaticamente um tamanho de buffer de pré-busca ideal:
Desta vez, usaremos um VGG16 pré-treinado e retreinaremos somente suas últimas 5 camadas para treinar este modelo:
keras_vgg16 = tf.keras.applications.VGG16(input_shape=(224,224,3), include_top=False)
output = keras_vgg16.outputoutput = tf.keras.layers.Flatten()(output)prediction = tf.keras.layers.Dense(len(labels), activation=tf.nn.softmax)(output)
model = tf.keras.Model(inputs=keras_vgg16.input, outputs=prediction)
for layer in keras_vgg16.layers[:-4]: layer.trainable = False
Agora, temos tudo o que precisamos e podemos prosseguir, como mencionado acima, e treinar o nosso modelo em alguns minutos usando NUM_GPUS GPUs:
model.compile(loss='categorical_crossentropy', optimizer=tf.train.AdamOptimizer(), metrics=['accuracy'])
NUM_GPUS = 2strategy = tf.contrib.distribute.MirroredStrategy(num_gpus=NUM_GPUS)config = tf.estimator.RunConfig(train_distribute=strategy)estimator = tf.keras.estimator.model_to_estimator(model, config=config)
BATCH_SIZE = 64EPOCHS = 1
estimator.train(input_fn=lambda:input_fn(train_folder, labels, shuffle=True, batch_size=BATCH_SIZE, buffer_size=2048, num_epochs=EPOCHS, prefetch_buffer_size=4), hooks=[time_hist])
Depois do treinamento, podemos avaliar a precisão no conjunto de teste, que deve ser de cerca de 95% (nada mau para um ponto de referência inicial 😀):
estimator.evaluate(input_fn=lambda:input_fn(test_folder, labels, shuffle=False, batch_size=BATCH_SIZE, buffer_size=1024, num_epochs=1))
Mostramos acima como é fácil treinar modelos Keras de aprendizado profundo com várias GPUs usando a API Estimators, como criar um canal de entrada que segue as práticas recomendadas para ter boa utilização de recursos (escalonamento linear) e como marcar o tempo da produtividade do treinamento com hooks.
É bom destacar que, no final, o ponto mais importante são os erros do conjunto de teste. Você pode notar que a precisão do conjunto de teste cai quando aumentamos o NUM_GPUS. Um dos motivos pode ser o fato de que MirroredStrategy realmente treina com um tamanho de lote de BATCH_SIZE*NUM_GPUS, o que pode exigir o ajuste de BATCH_SIZE ou da taxa de aprendizado quando se usa mais GPUs. Neste caso, separei todos os outros hiperparâmetros da constante NUM_GPUS para facilitar os traçados. No entanto, em um cenário real, será preciso ajustá-los.
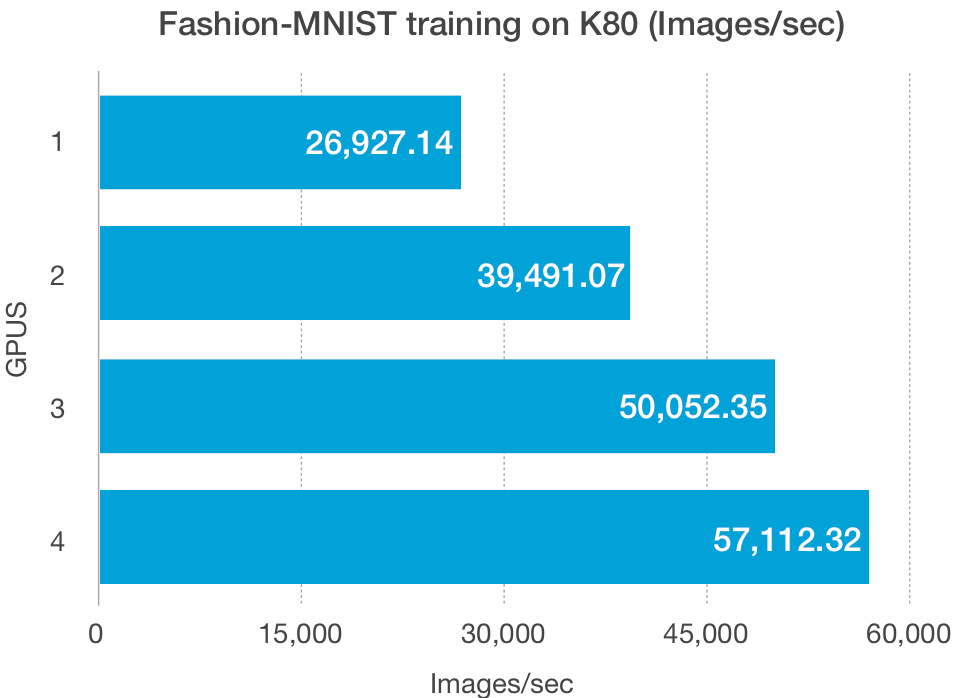
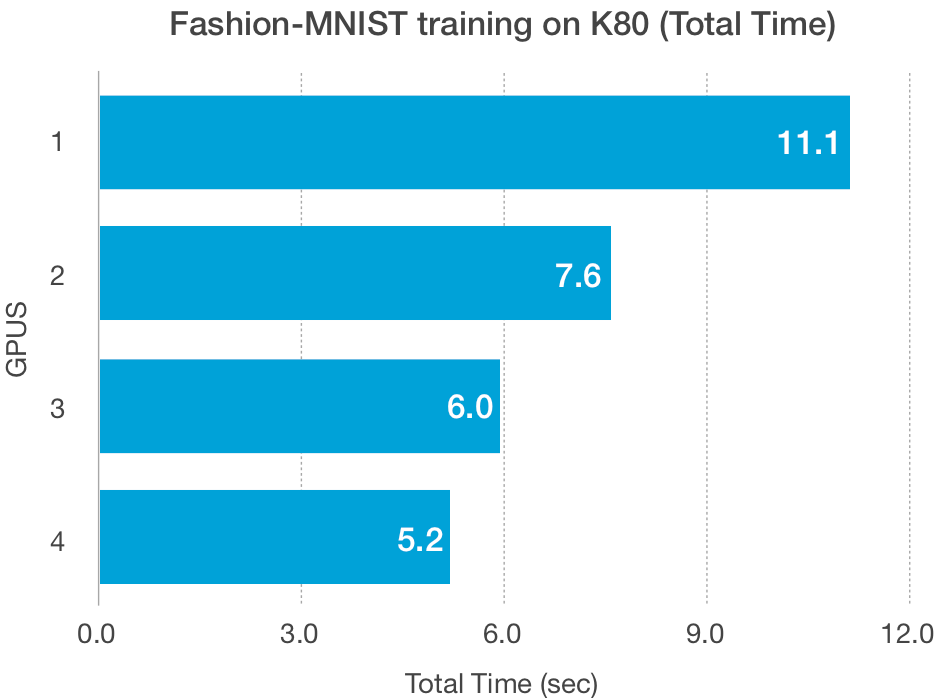
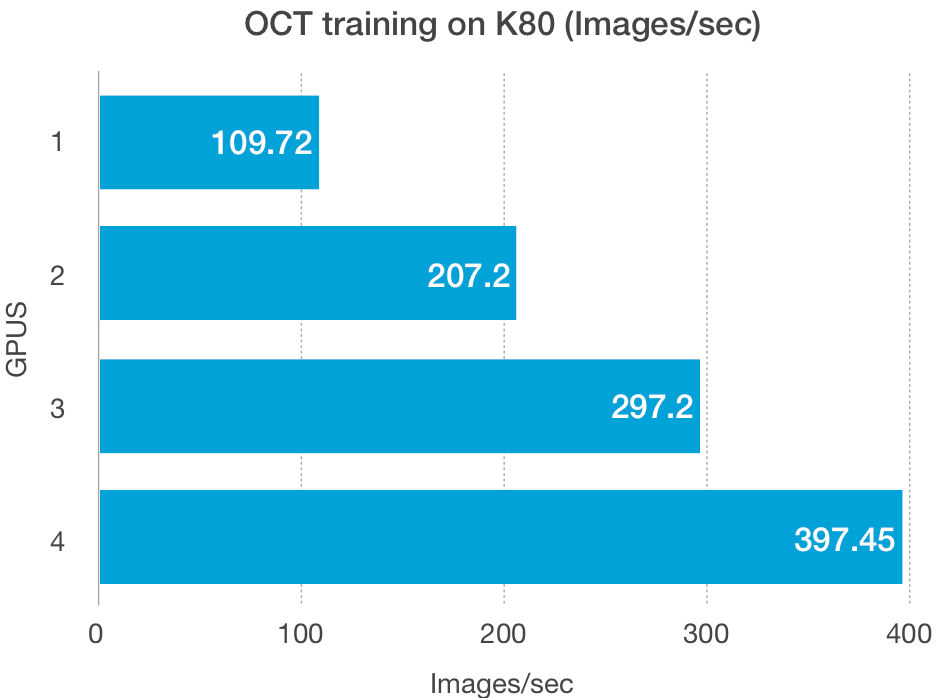
O tamanho do conjunto de dados, além do tamanho do modelo, afeta a capacidade de dimensionamento desses esquemas. As GPUs têm baixa largura de banda na leitura e gravação de dados de baixo volume, especialmente as GPUs mais antigas, como a K80, e podem ser responsáveis pelos traçados de Fashion-MNIST acima.
Quero agradecer à equipe do TensorFlow, especialmente a Josh Gordon, e a todos da Zalando Research pela ajuda na correção do rascunho, especialmente Duncan Blythe, Gokhan Yildirim e Sebastian Heinz.
De Yash Katariya, estagiária de engenharia de programas para desenvolvedores
Sempre achei os modelos geradores e sequenciais fascinantes: eles fazem um tipo de pergunta diferente dos que normalmente encontramos quando começamos a estudar aprendizado de máquina (AM). Quando comecei a estudar AM, aprendi (como muitos de nós) classificação e regressão. Esses conhecimentos me ajudaram a responder perguntas como:
Classificação e regressão são conhecimentos que vale muito a pena dominar. As possibilidades de aplicação desses conhecimentos em problemas úteis e reais são praticamente ilimitadas. Mas há outros tipos de pergunta que podemos fazer e que têm um aspecto bem diferente:
No meu estágio de verão, desenvolvi exemplos dessas áreas usando duas das APIs mais recentes do TensorFlow: tf.keras e execução antecipada. As duas estão compartilhadas a seguir. Espero que sejam úteis e que você se divirta bastante!
Se você ainda não é muito experiente com essas APIs, pode aprender mais explorando a sequência de blocos de anotações em tensorflow.org/tutorials, que contém exemplos atualizados recentemente.
Todos os exemplos abaixo são completos e seguem um padrão similar:
Nosso primeiro exemplo é de geração de texto, em que usamos uma RNN para gerar texto em um estilo parecido com o de Shakespeare. Você pode executá-lo no Colaboratory com o link acima (ou baixá-lo do GitHub como um bloco de anotações do Jupyter). O código é explicado em detalhes no bloco de anotações.
Considerando a enorme coleção de obras de Shakespeare, esse exemplo aprende a gerar textos com estilo parecido:
Embora a maioria das sentenças não faça sentido (obviamente, esse modelo simples não aprendeu o significado da linguagem), o que impressiona é que a maioria das palavras *é* válida e a estrutura das peças produzidas é semelhante à do texto original (esse é um modelo baseado em personagens, no breve período em que o treinamos; ele aprendeu as duas coisas totalmente do zero). Se quiser, você pode alterar o conjunto de dados mudando uma única linha do código.
O melhor lugar para entender melhor as RNNs é no excelente artigo de Andrej Karpathy, The Unreasonable Effectiveness of Recurrent Neural Networks. Se quiser saber mais sobre como implementar RNNs com o Keras ou o tf.keras, recomendamos esses blocos de anotações de Francois Chollet.
Neste exemplo, geramos dígitos escritos a mão usando DCGAN. Uma rede geradora adversária (GAN) consiste em um gerador e um discriminador. O trabalho do gerador é criar imagens convincentes para enganar o discriminador. O trabalho do discriminador é classificar as imagens como reais ou falsas (criadas pelo gerador). O resultado abaixo foi gerado após o treinamento do gerador e do discriminador por 150 eras usando a arquitetura e os hiperparâmetros descritos neste artigo.
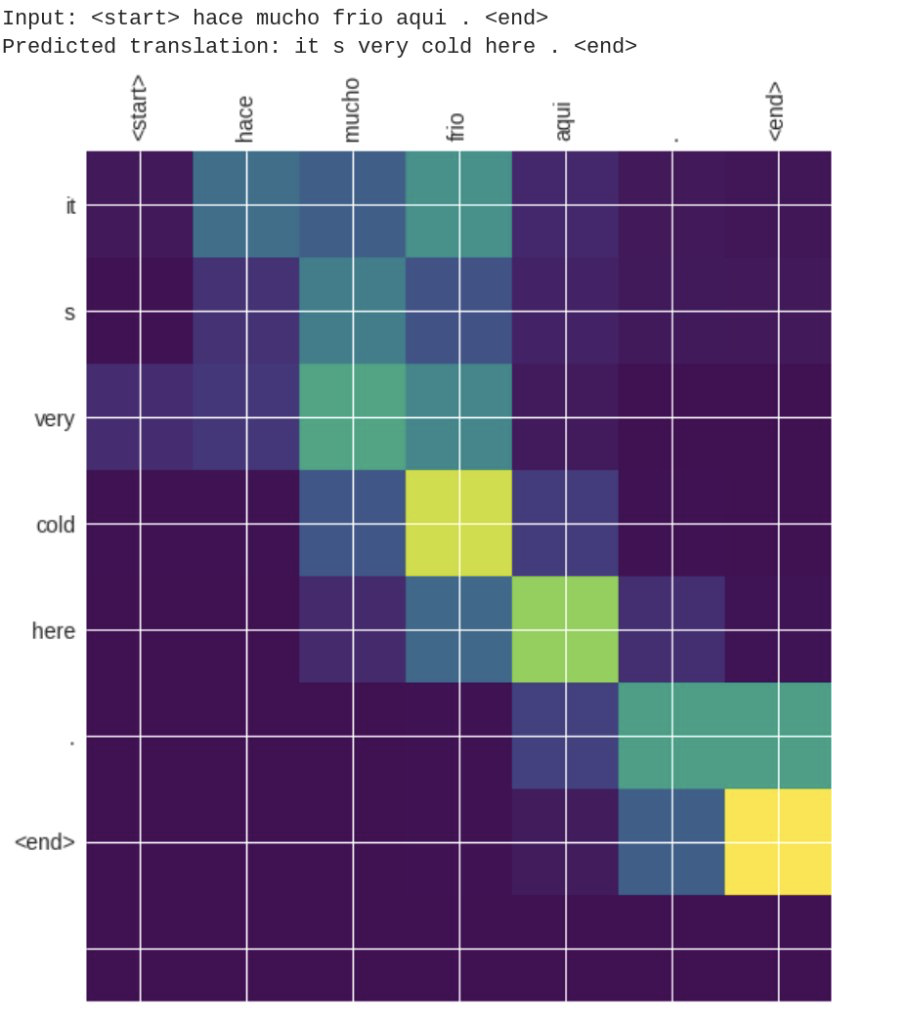
Este exemplo treina um modelo para traduzir frases em espanhol para o inglês. Depois de treinar o modelo, você poderá inserir uma frase em espanhol, como "¿todavia estan en casa?", e retornar a tradução para o inglês: "are you still at home?"
A imagem abaixo é o diagrama de atenção. O diagrama mostra que partes da frase de entrada têm a atenção do modelo durante a tradução. Por exemplo, quando o modelo traduziu a palavra "cold", estava analisando "mucho", "frio", "aqui". Implementamos o Bahdanau Attention do zero usando o tf.keras e a execução antecipada, que explicamos detalhadamente no bloco de anotações. Você pode usar essa implementação como base para implementar seu próprios modelos personalizados.
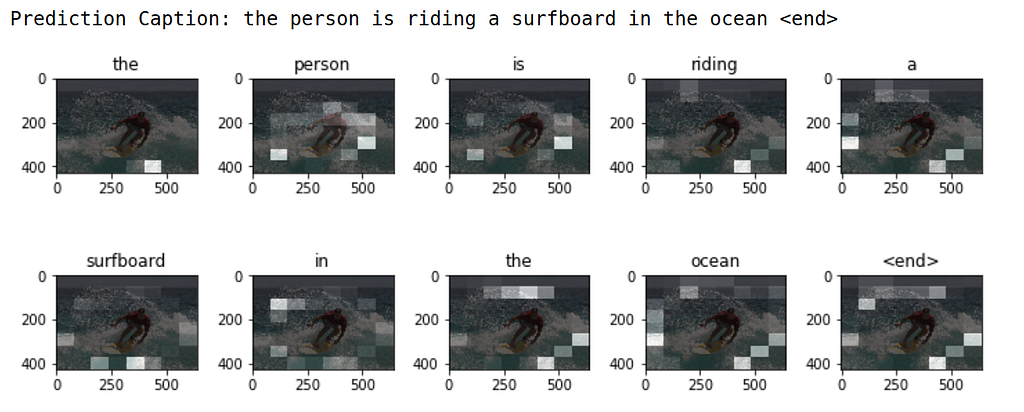
Neste exemplo, treinamos o nosso modelo para prever a legenda de uma imagem. Geramos também um diagrama de atenção, que mostra partes da imagem em que o modelo se concentra para gerar a legenda. Por exemplo, o modelo se concentrou na área perto da prancha de surfe da imagem quando previu a palavra "surfboard". Esse modelo foi treinado usando um subconjunto do conjunto de dados MS-COCO, que será baixado automaticamente pelo bloco de anotações.
Próximos passos
Para saber mais sobre o tf.keras e a execução antecipada, fique atento ao conteúdo de tensorflow.org/tutorials (frequentemente atualizado) e confira periodicamente este blog e o feed do TensorFlow no Twitter. Obrigado por ler!
Agradecimentos
Agradecemos imensamente a Josh Gordon, Mark Daoust, Alexandre Passos, Asim Shankar, Billy Lamberta, Daniel "Wolff" Dobson e Francois Chollet por suas contribuições e sua ajuda.