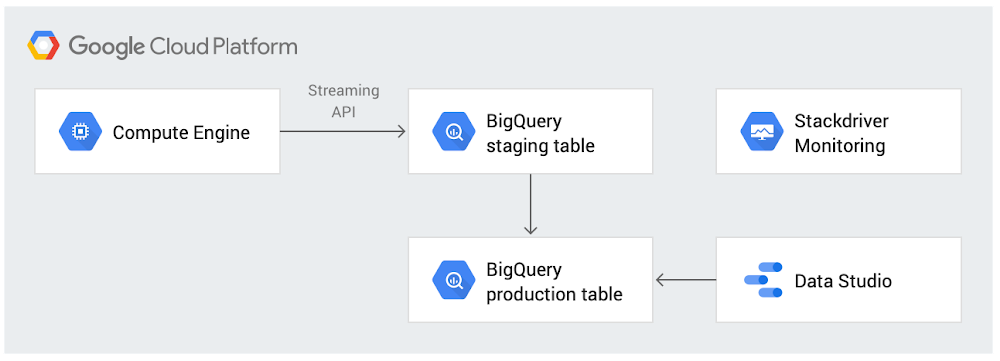
Usamos um script Python simples para ler os problemas da API e inserir as entradas no BigQuery por meio do método da API de streaming. Escolhemos a API de streaming, em vez do Cloud Pub/Sub ou do Cloud Dataflow, porque queríamos preencher novamente o conteúdo do BigQuery com os dados mais recentes várias vezes ao dia. A biblioteca do cliente API Python do Google foi uma escolha óbvia, porque ela oferece uma maneira idiomática de interagir com as APIs do Google, incluindo a API de streaming do BigQuery.
Como esses dados seriam usados somente para fins de relatório, optamos por manter apenas a versão mais recente dos dados extraída. Tivemos duas razões para essa decisão:
- Dados mestres: Nunca haveria dúvida sobre quais dados eram a versão mestre dos dados.
- Dados históricos: Não tínhamos casos de uso que exigissem a captura de dados históricos que ainda não haviam sido capturados na extração de dados.
Seguimos as práticas recomendadas comuns de extrair, transformar e carregar (ETL), com uma tabela de preparação e uma tabela de produção separada para que pudéssemos carregar dados na tabela de preparação sem afetar os usuários dos dados. O design criado com base nas práticas recomendadas de ETL exigia a exclusão de todos os registros da tabela de preparação. Além disso, era necessário carregá-la e substituir a tabela de produção pelo conteúdo.
Ao usar a API de streaming, o buffer de streaming do BigQuery permanece ativo por cerca de 30 a 60 minutos ou mais após o uso. Isso significa que não é possível excluir nem alterar os dados durante esse período. Como usamos a API de streaming, programamos o carregamento a cada três horas para equilibrar a inserção rápida de dados no BigQuery e poder excluir os dados subsequentemente da tabela de preparação durante o processo de carregamento.
Após os dados estarem no BigQuery, seria possível escrever consultas SQL diretamente neles ou usar qualquer uma das diversas ferramentas integradas disponíveis para analisá-los. Para visualização, escolhemos o Data Studio, porque ele é bem integrado ao BigQuery, oferece recursos personalizáveis do painel e a capacidade de colaborar, além de ser gratuito, é claro.
Como os conjuntos de dados do BigQuery podem ser compartilhados com os usuários, a usabilidade dos dados foi aberta para quem recebeu acesso e autorização apropriada. Com isso, também poderíamos combinar esses dados no BigQuery com outros conjuntos de dados. Por exemplo, rastreamos as métricas de engajamento on-line dos nossos guias de referência e as carregamos no BigQuery. Com os dois conjuntos de dados no BigQuery, foi fácil levar em consideração os números de engajamento on-line para criar os painéis.
Criação de um painel de exemplo
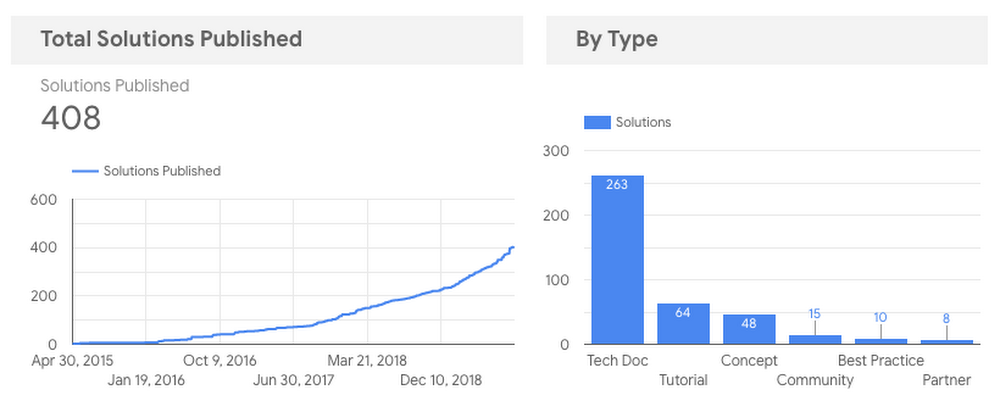
Um dos principais motivos para querermos criar relatórios no nosso processo de publicação é acompanhar esse processo ao longo do tempo. O Data Studio facilitou a criação de painéis com gráficos, semelhantes aos dois que podem ser vistos abaixo. A criação do painel no Data Studio nos permitiu analisar facilmente nossas métricas de publicação ao longo do tempo e depois compartilhar os painéis específicos com outras equipes além da nossa.




3 comments :
Friday Night Funkin' is an open-source, free-to-play rhythm game developed by Cameron Taylor (PhantomArcade) Friday Night Funkin and Isaac Garcia (Kawai Sprite). The game draws heavy inspiration from classic rhythm games like Dance Dance Revolution
This is a fantastic resource. Real Beneficiaries of Ehsaas Program I will definitely bookmark it!
Post a Comment